

はじめに
はじめまして。DataPlatform開発の宇代と申します。これまで業務委託として参画してきましたが、改めて2023年5月より正社員としてKiZUKAIにJoinしました(絶賛、新入社員でございます)。これまでの経歴等、すこしだけ自己紹介させてください。

(シリーズAの資金調達記念の写真撮影。まだ業務委託開始1ヶ月にも関わらず呼んでもらいました。正社員や業務委託の垣根を感じないフラットな文化もKiZUKAIならではですね。)
自己紹介
大手メーカーで約4年従事し独立。個人事業主として業務委託にて複数案件こなしつつ、営業パートナーとともに、アイデア出しやブラッシュアップ、市場調査、自社プロダクト開発、営業、起業メンバー探し等も行ってました。クライアントとの接し方の難しさだったり、集客の難しさだったり、これまでの開発での思考回路とはまるで違った経験をして、何となく今まで感じていた「1つの分野だけでなく複数ドメインに幅広く携われる生き方の方が楽しい」という自分なりの考えが、確固たるものになった時期でもありました。
新鮮な毎日を過ごせていましたが、信用も知見もない個人でモノを売るには、やはり壁はたくさんありました。プロダクト開発したは良いが、ペルソナが明確に決まっていなかったため、誰にも売れなかったり。まずは売る経験をするために、知人経由だったりメディアプラットフォームに掲載して売ってみたは良いものの、スケールはしない事を肌で感じたり。
違うアプローチを模索していきたいと思っていたその時、業務委託として働いていたKiZUKAIから正社員へのオファーを受けました。もともと「手を上げたら基本トライさせてくれる文化」に、居心地の良さを感じていたのですが、フルコミットした方が経営まわりも含めビジネス側の知見が身につくのでは?と思い、正社員への移行を決めました。(もちろんそれ以外にもプロダクトへの愛だったり、社内メンバーとの相性だったり、いくつか理由はありますが、ここでは割愛します。別途、社員インタビューで触れているので、ぜひご覧ください。)
今後は、開発にも従事しつつ、ビジネスの知見もキャッチアップしていき、コアな人材になっていければと思ってます。
本題
KiZUKAIでは「手を上げたらトライさせてくれる文化」があるので、要件定義から開発フロー、細かな機能詳細仕様変更に至るまで、手を挙げたら、まず聞き入れてくれます。既存プロダクトが動いているのであれば、特に大規模な変更はGoの決断ができない企業も珍しくないですが、プロダクトが良くなるメリットや実現工数等々、明確に伝えられれば、適切に判断してもらえる感覚があります。1つの例として、DataPlatformチームにおけるdbt導入について本記事では話をします。
dbtとは
dbt(Data Build Tool)は、データパイプラインの構築、運用、テストを効率化するためのオープンソースのSQLフレームワークです。主な機能は、データベース内でのデータ変換(transform)作業を自動化することです。データ抽出(extract)とデータロード(load)は、Apache Airflow、Stitch、Fivetranなど他のツールによって行われる中で、dbtはELT(Extract, Load, Transform)パイプラインの最後のステップ、「T」を実行します。dbtはModern Data Stackにおけるデータパイプラインの中心とも言える重要な役割を果たしています。
dbt導入背景
KiZUKAIツールの役割はLTV向上ですが、ツール導入における効果の1つとして、他社のデータサイエンティスト費用/工数の代替があります。
データ分析の専門家として我々KiZUKAIが他社の分析を担う事で、ある程度どういう分析をすれば意味ある分析になるか当たりどころをつけたり、データ整理や定義等のいわゆるデータ設計ができます。
しかし、もちろんデータサイエンティストの代替となると、データの準備や、前処理、分析、テストにおいても、やることは多岐に渡ります。またクライアントによって異なるデータであるため個別対応も多く、分析量が膨大になっています。
KiZUKAIツールのインフラはAWSなので、データの前処理や分析は、Glueで行っていましたがいくつかの課題がありました。
- テスト難易度が高い
- Glueの知識が必要
- コードの再利用性が難しい
- 処理フローが見えにくい
- コストが高い
これらの課題は、クライアントの増加とともにより顕著となり、開発メンバーの中でも特定メンバーしか保守できない属人化が起きていました。これらの問題に対応するため、兼ねてより気になっていたdbt導入を検討しました。
dbt導入による改善事例
原則として、先述のGlueに関するデメリットをほぼカバーしていますが、代表的な例についてピックアップします。(dbtの構築において、特に拘った点や困った点は多々ありますが、詳細については後日投稿できればと思います)
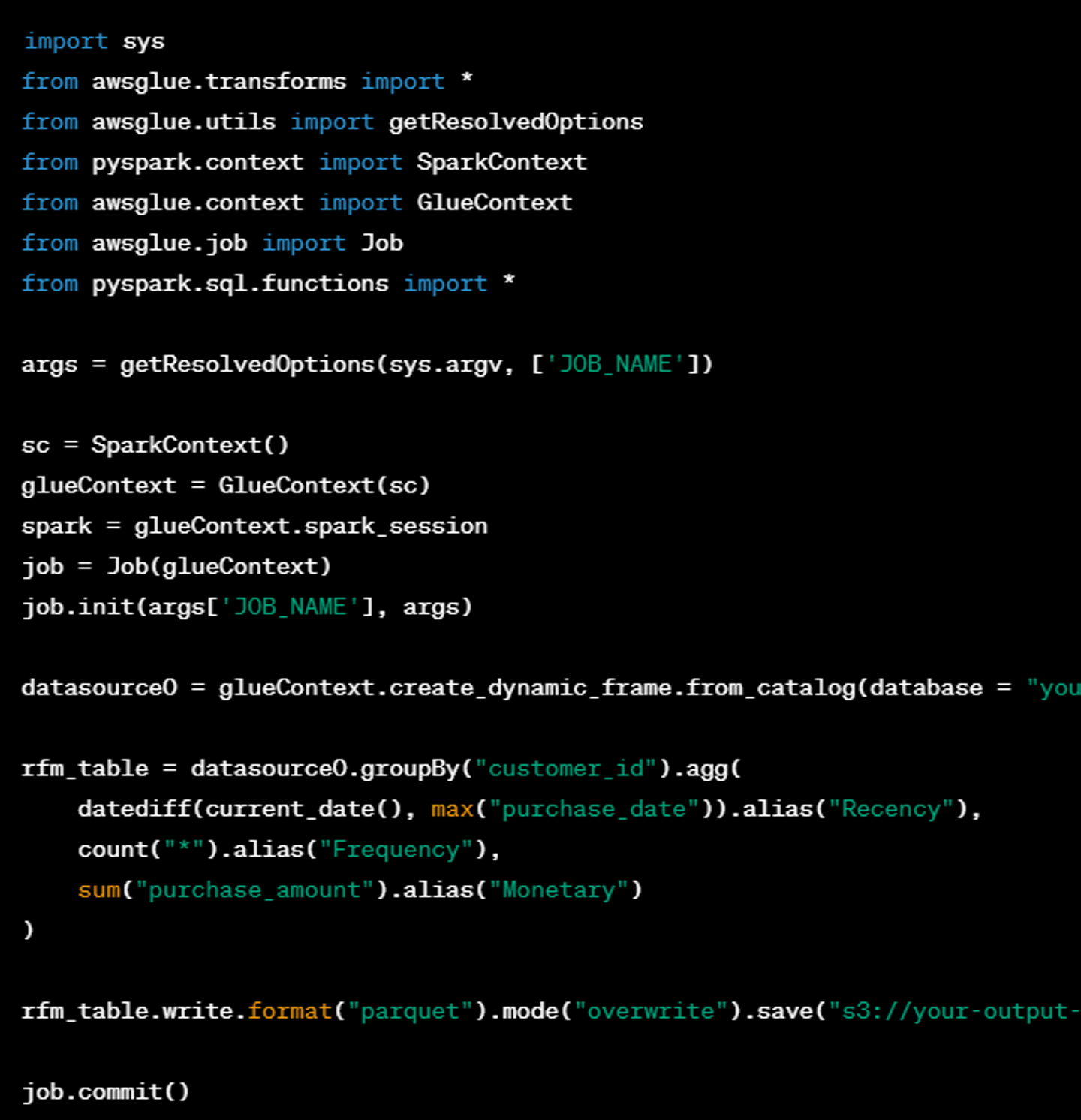
【課題1】Glueの知識が必要
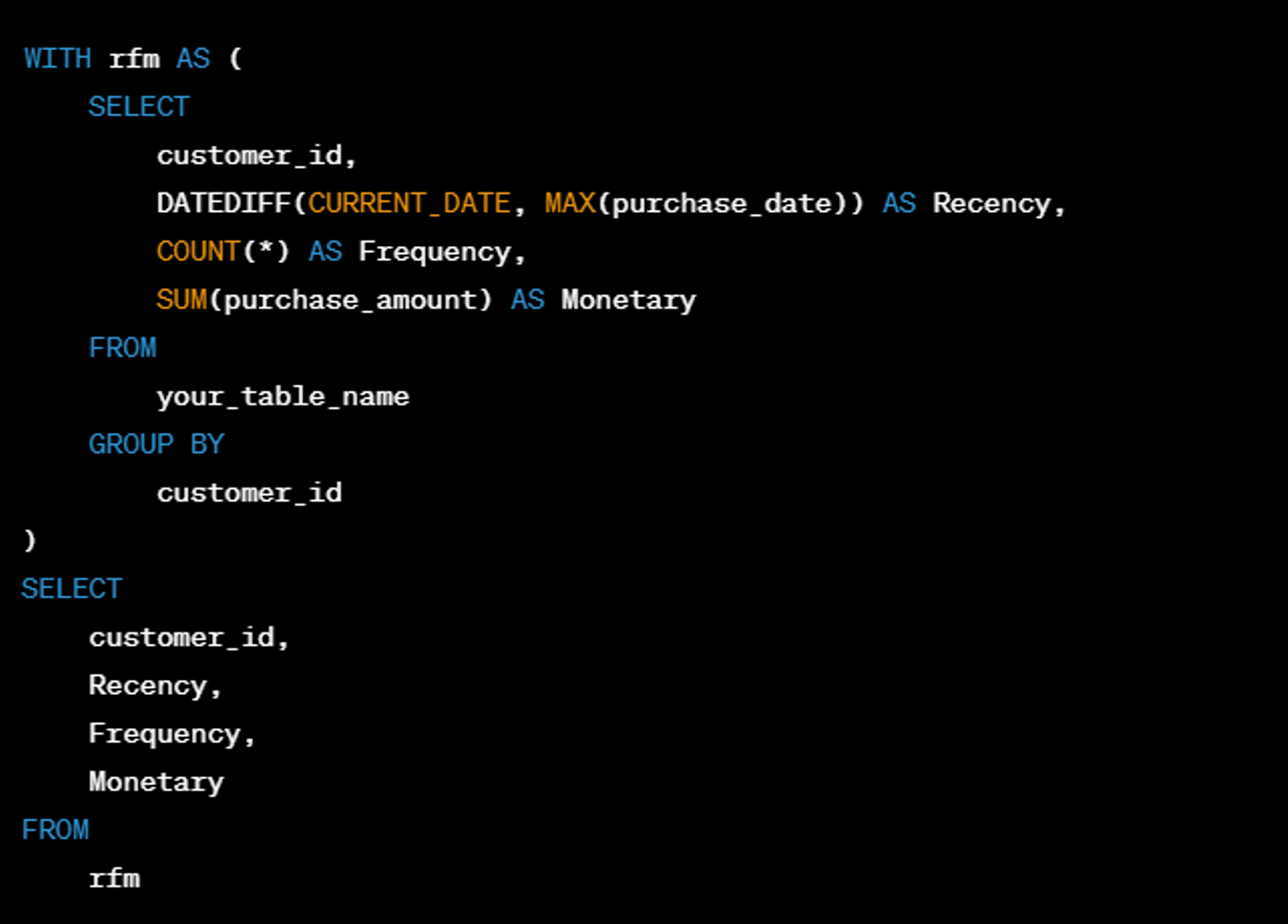
Glueでは、Sparkなどの知識やGlue固有の複雑な仕様が必要となるため、新規作成する場合だけでなくデバッグも困難です。一方、dbtは設計思想がある程度決まれば、SQLを書くだけで実現できます。RFM分析についてのサンプルを以下に記載します。
・Glueサンプル
・dbtサンプル
【課題2】テスト難易度が高い
サンプルとして、not_nullテストと、参照整合性を検証するrelationshipsテストについて、記載します。
・Glueサンプル
Glueを使用する場合、例外的なケースについて適宜実装する必要があります。また、データ分析とテストをGlueで分けて実行する場合、コードがより複雑になることがあります。さらに、遅延評価を考慮しないと、パフォーマンスが急激に低下する可能性があります。
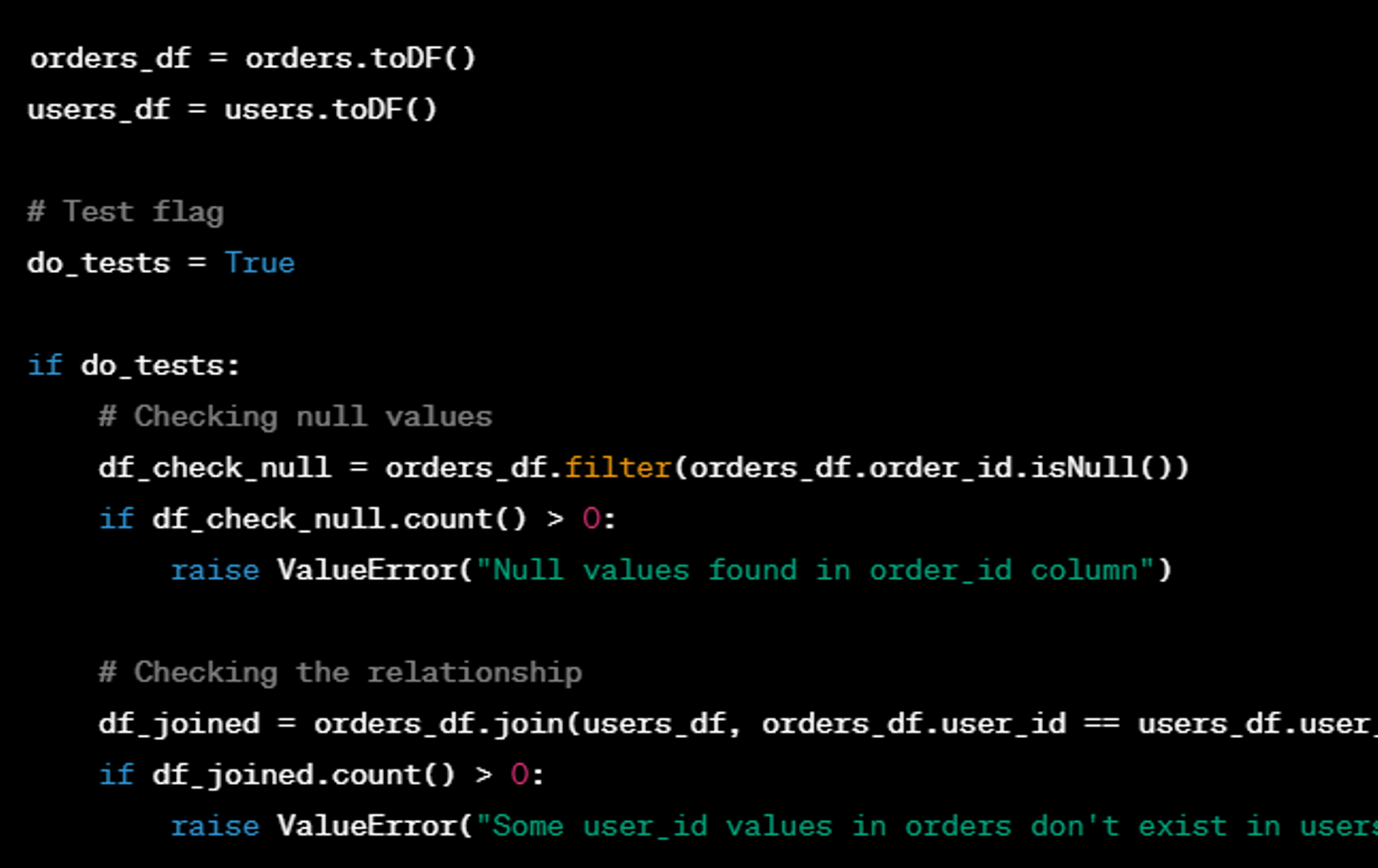
・dbtサンプル
テストフレームワークが用意されており、簡単に実装できます。また、データ分析とテストを分けて実行する場合も容易です。マクロも定義できるため、カスタムしたテストを使い回すことも容易です。
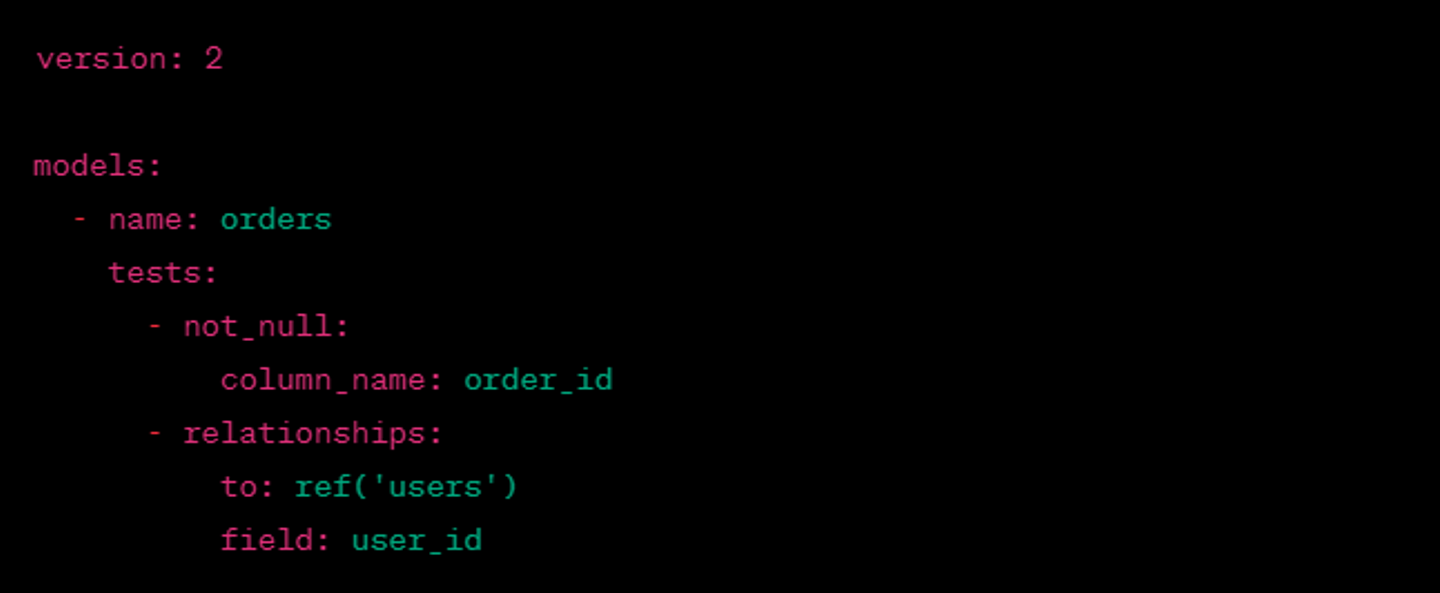
【課題3】データ処理フローが見えにくい
Glueでは、SparkUIを構築してフローを可視化することができますが、構築に手間がかかります。dbtを使用すると、DAG(Directed Acyclic Graph)として簡単にフローを可視化できます。
・DAGサンプル
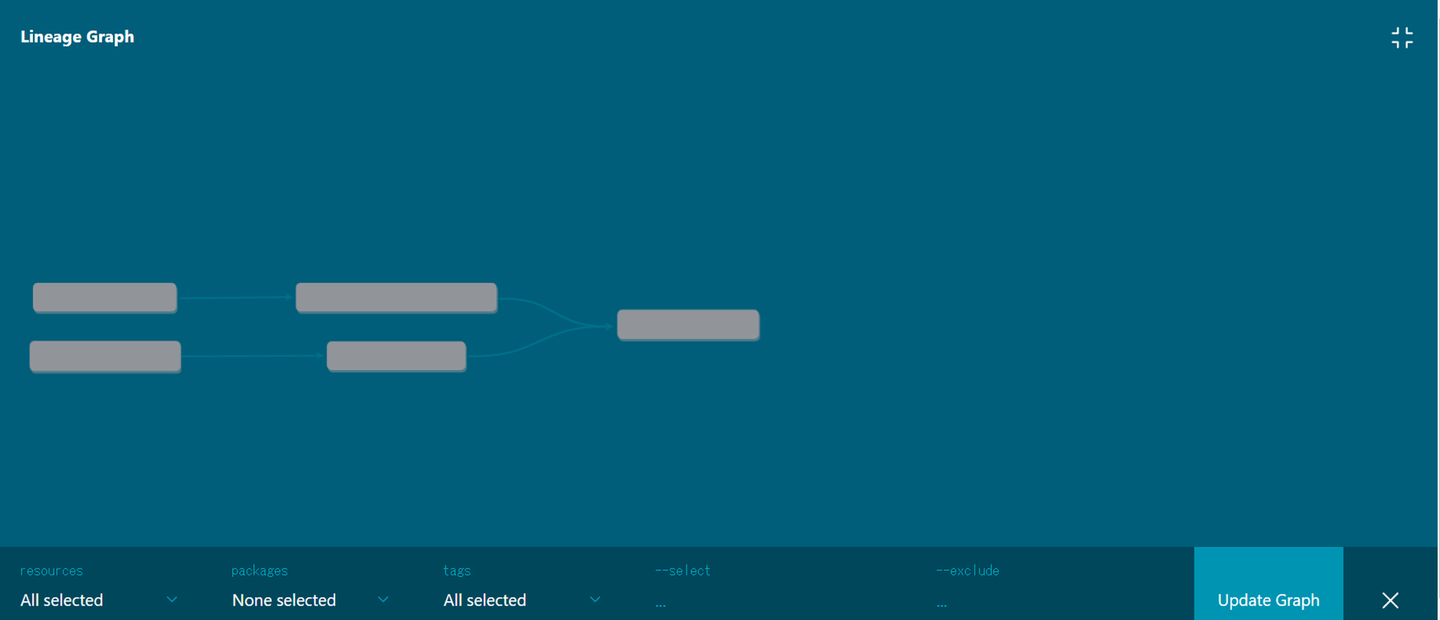
これらの問題がクリア出来たことにより、少しだけdbtの知識をキャッチアップして、SQLが書けるメンバーであれば、データまわりの開発ができるようになり、属人化が解消されました。また、データ処理フローの共有により、Salesと開発のコミュニケーションがより取りやすくなる副次効果もありました。
さいごに
本記事のdbt導入は、弊社の「手を上げたらトライできる文化」を表した一例ですが、おおむね開発内で閉じた話でした。
今後は、スタートアップならではのチーム間の距離の近さも活かし、開発外も含め、別ドメインのメンバーが手を挙げて協力することで、近い未来、イノベーションを実現していきます。
KiZUKAIでは、絶賛メンバー採用中です!
また、お決まりですがKiZUKAIでは絶賛エンジニアメンバーも採用中です!
カジュアル面談も大歓迎です。お気軽にエントリーしてください。
/assets/images/4934437/original/620a5add-6f94-4f12-a97c-34d1c83e6d2d?1587689225)


/assets/images/4934437/original/620a5add-6f94-4f12-a97c-34d1c83e6d2d?1587689225)
/assets/images/13534329/original/620a5add-6f94-4f12-a97c-34d1c83e6d2d?1686292776)


