
株式会社コムデ's job postings
はじめに
Dynamodb上のデータをグラフ化するにはBIツールであるAmazon QuickSightやElasticsearchなどのサービスがあります。
しかし、Amazon QuickSightでグラフ化するにはLambdaを使ってDynamoDBのデータをCSVに変換しS3に格納したりする必要があるため面倒です。もっと簡単にグラフ化したいですよね??
いつも使っているCloudwatchとかで見えたら最高ですよね!なので今回はcloudwatchを使ってデータをグラフ化(可視化)したいと思います。
設定手順
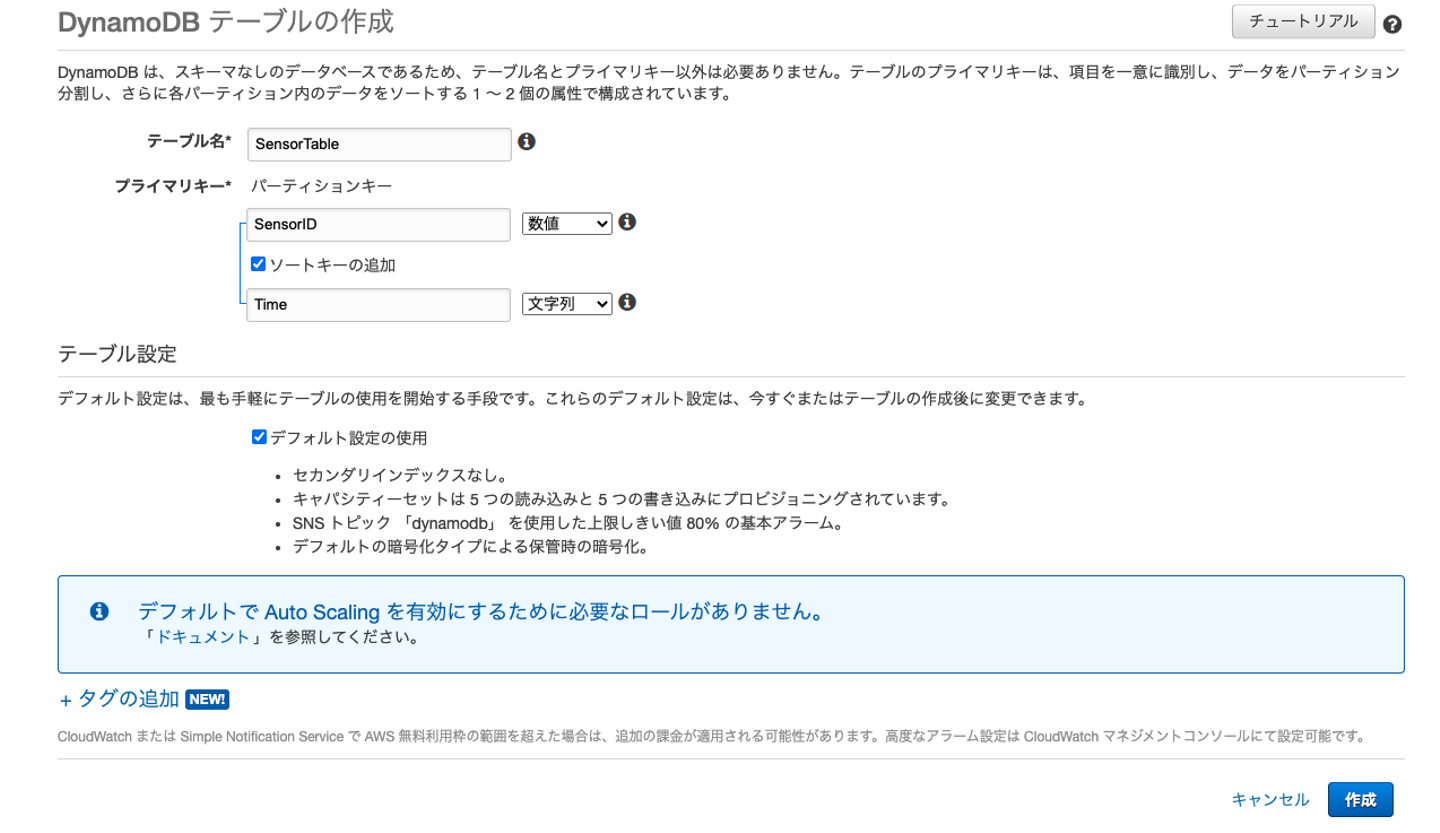
①Dynamodbテーブルの作成
今回はデバイスの温度を管理するテーブルを作成し、データをグラフ化したいと思います。
- - テーブル名: SensorTable
- - プライマリキー: SensorID 数値型
- - ソートキー: Time 文字列型
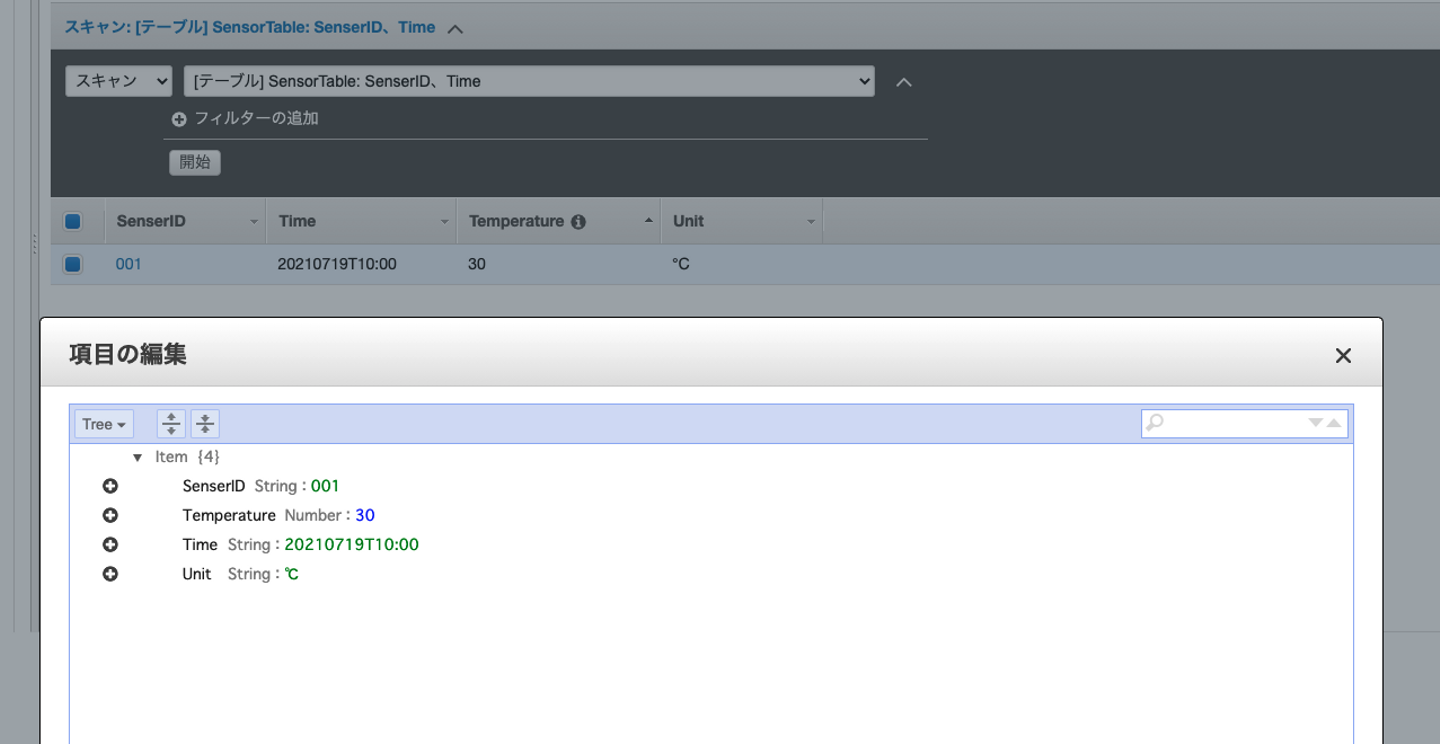
作成したSensorTableにデータを入れます。
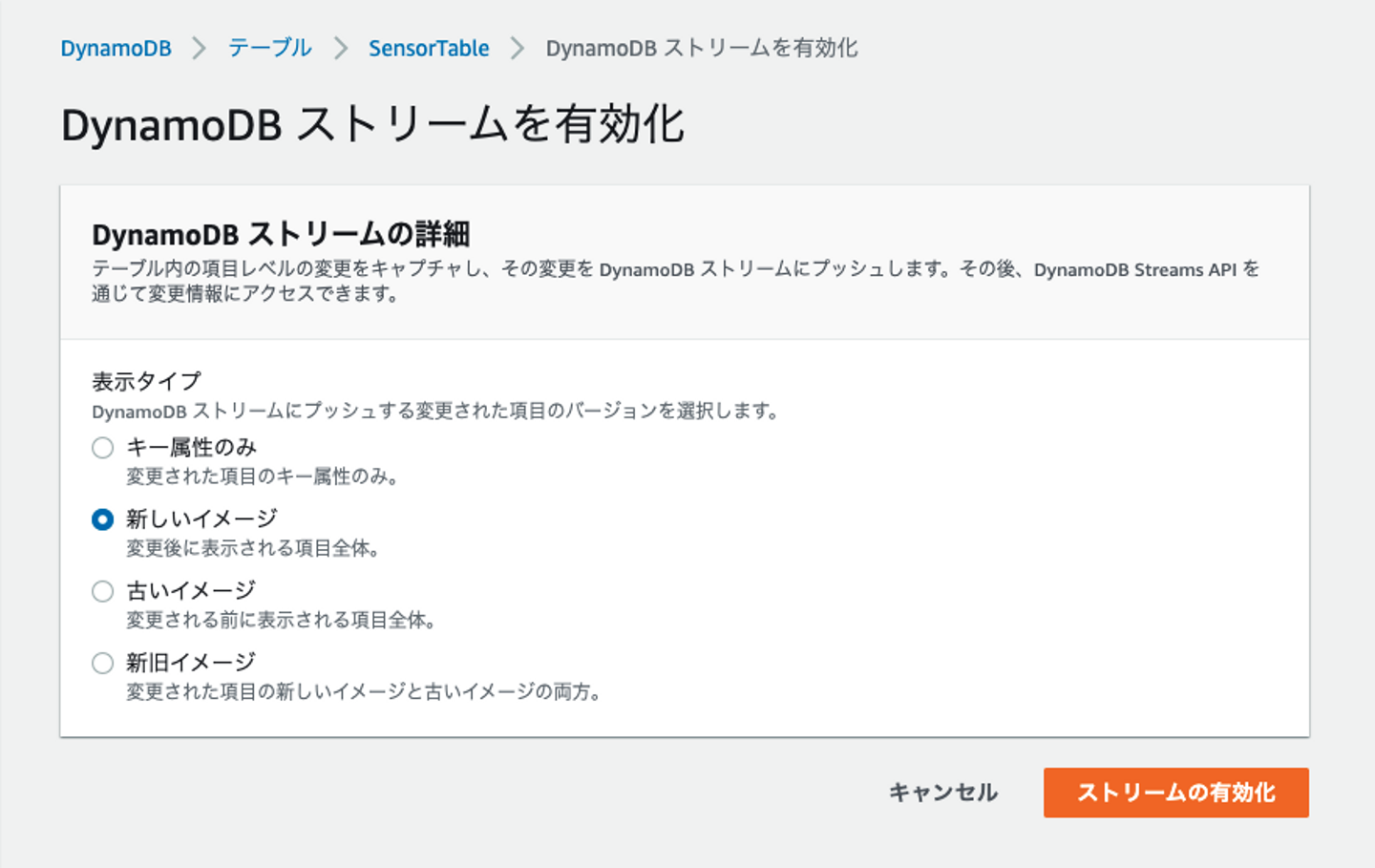
■Dynamodb Streamの有効化
Dynamodb StreamとはDynamoDBに対する項目の追加、変更、削除をイベントとして検出できる機能です。
テーブルで DynamoDB Streams を有効にした場合、書き込む AWS Lambda 関数にストリーミングの Amazon リソースネーム (ARN) を関連付けることができます。テーブルの項目が変更されると、新しいレコードがテーブルのストリーミングに直ちに表示されます。AWS Lambda はストリーミングをポーリングし、新しいストリーミングレコードを検出したときに Lambda 関数を同期的にコールします。
②Lambdaの作成
- - 関数名(今回はput_cloudwatch)
- - ランタイム Python 3.8
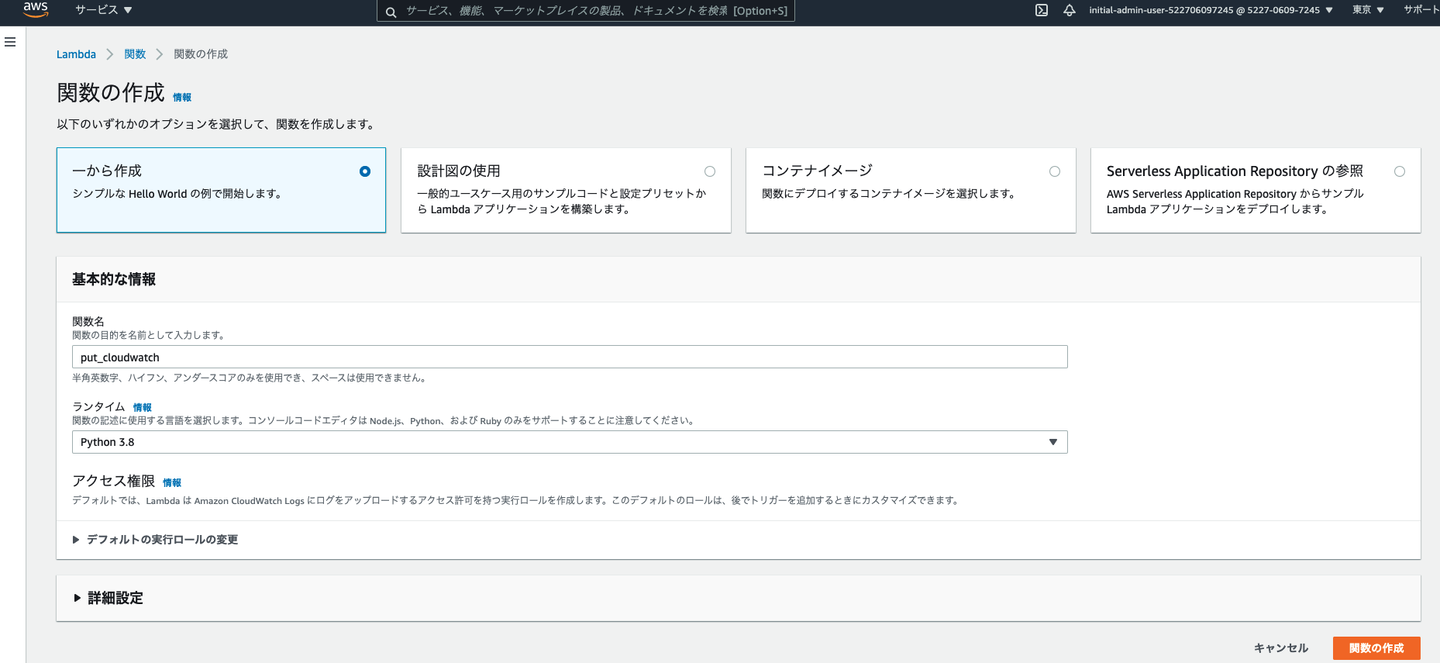
これでLambda関数が作成されたと思います。関数を作成すると自動でロールが作成されます。しかし、このロールはCloudwatch logsの権限しかついていないためポリシーをつけ加えます。
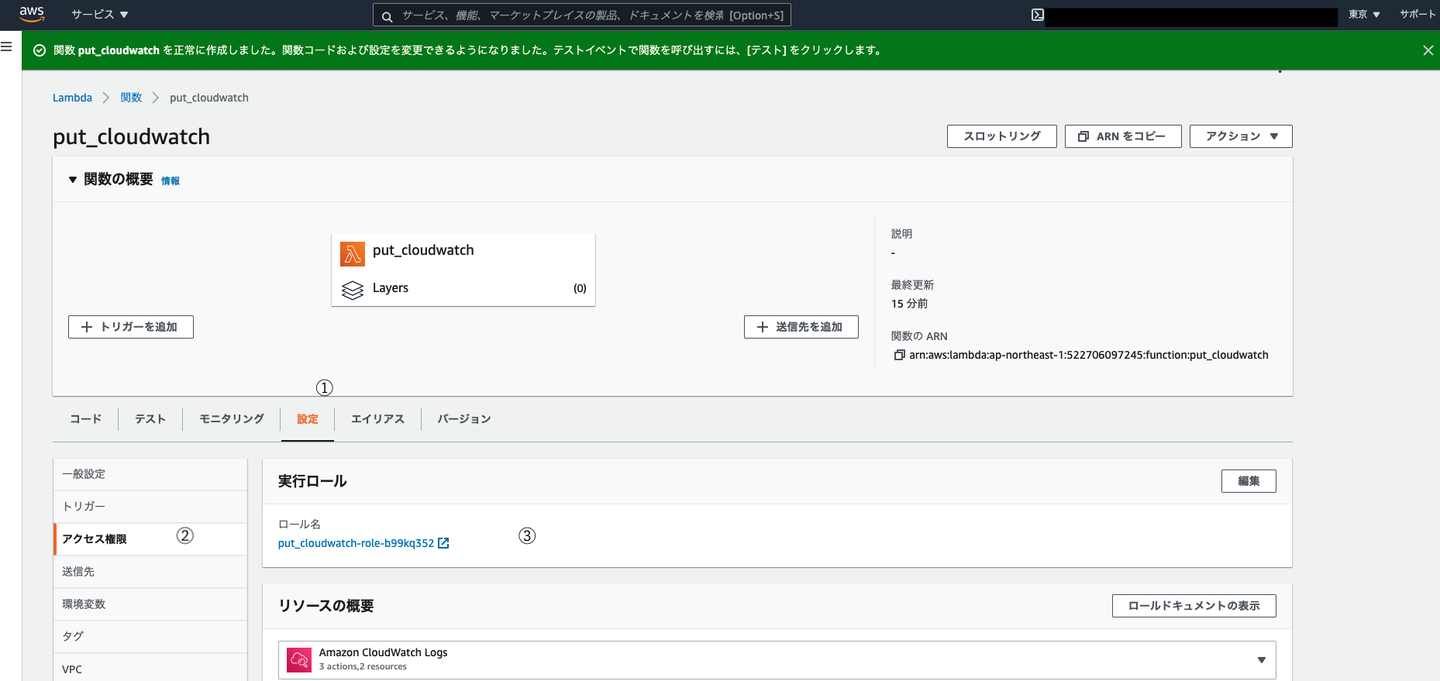
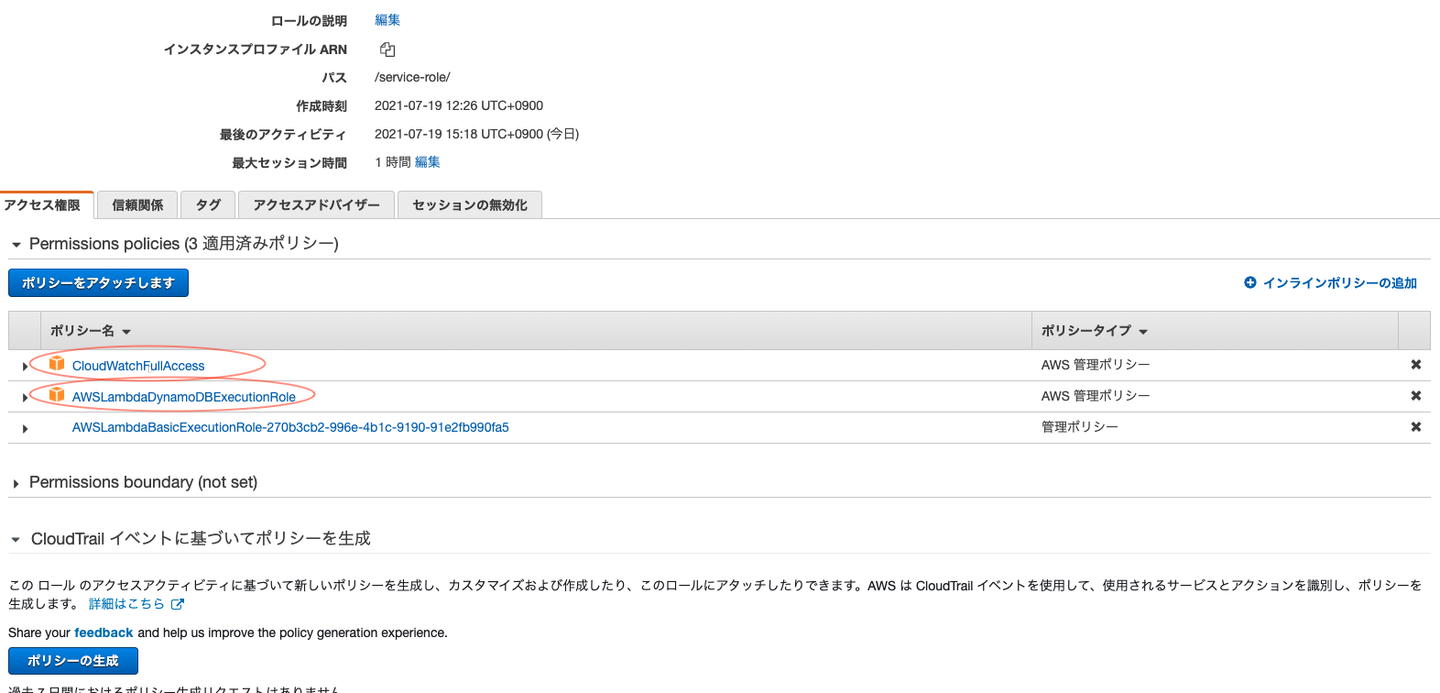
下記2つのポリシーをアタッチする
- - CloudWatchFullAccess
- - AWSLambdaDynamoDBExecutionRole
トリガーの追加
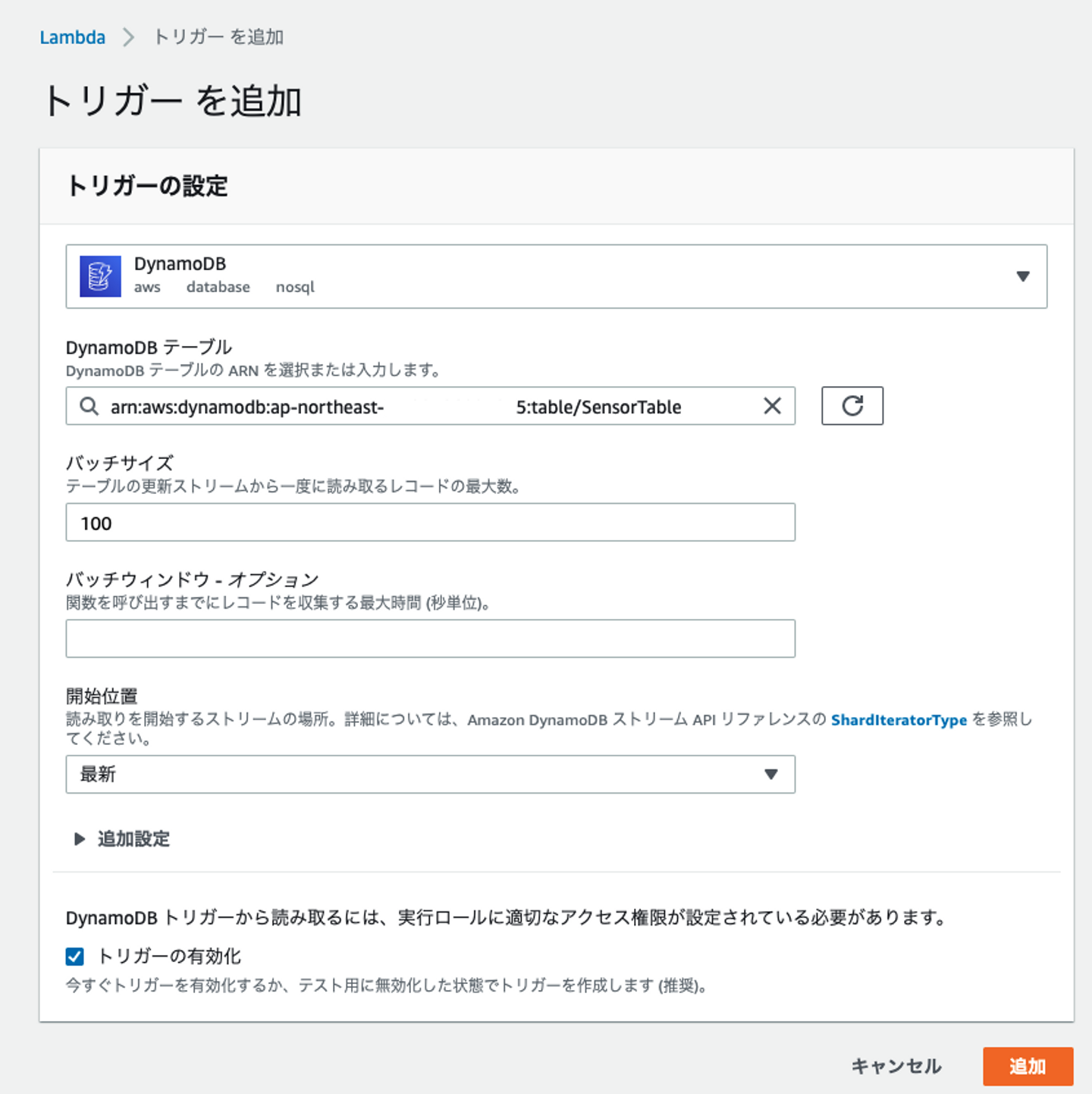
最後にソースコードをDeployすればDynamodbをトリガーとするLamabda関数の完成です。
import json
import boto3
cloudwatch = boto3.client('cloudwatch')
def lambda_handler(event, context):
SensorID = event['Records'][0]['dynamodb']['Keys']['SensorID']['N']
Temperature = event['Records'][0]['dynamodb']['NewImage']['Temperature']['N']
# print(Temperature)
# print(SensorID)
try:
cloudwatch.put_metric_data(
MetricData = [
{
'MetricName': 'SensorTable',
'Dimensions': [
{
'Name': 'SensorID',
'Value': f'SensorID-{int(SensorID)}'
},
],
'Unit': 'Count',
'Value': int(Temperature)
},
],
Namespace = 'SensorTable'
)
except Exception as e:
print('Error: Dynamodb error', e)
print(e)あとはLambdaをDeployすれば完成です。SensorTableにテーブルにデータを入れるとcloudwatchカスタムメトリクスが作成されているはずです。エラーが出た場合はCloudwatch logsを確認してみてください。
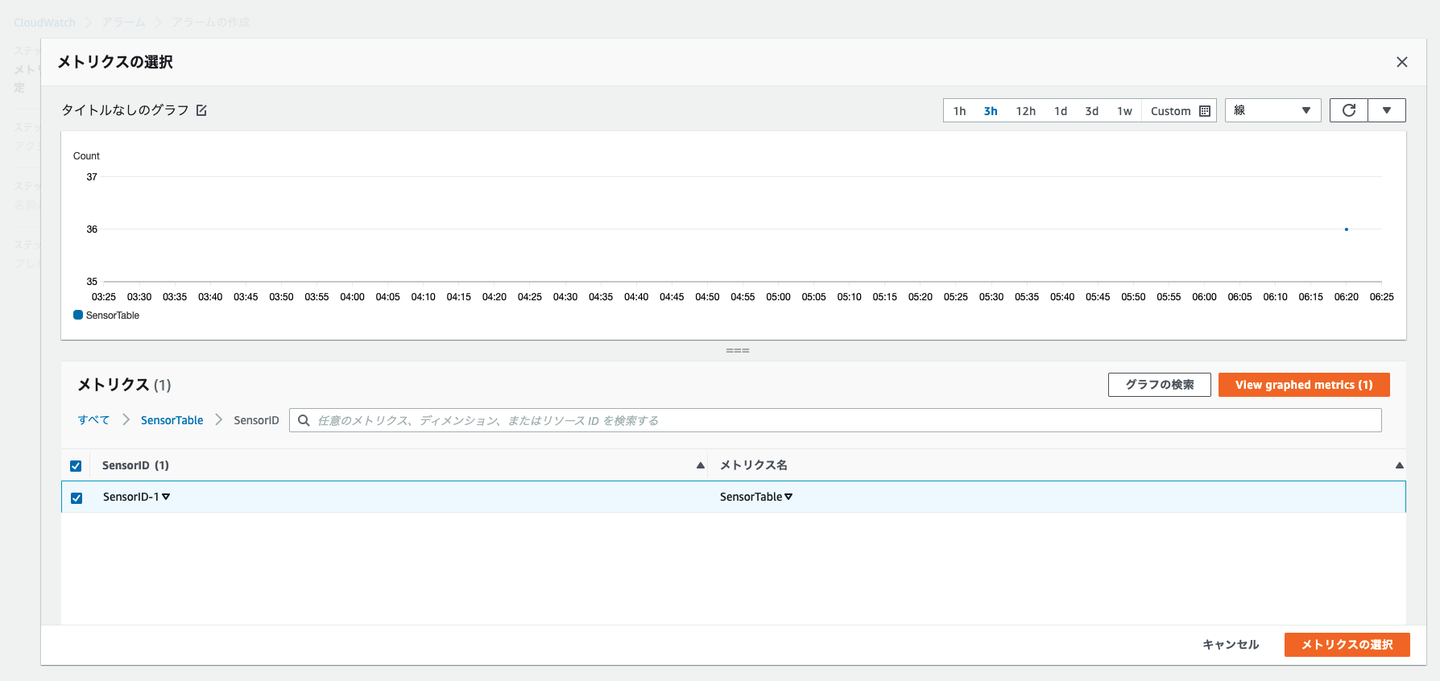
■まとめ
今回はDynomodb上のデータをcloudwatchを利用してグラフを作成しました。cloudwatchで作成したことによりアラームの作成やほかサービスとの連携が簡単にできると思います。しかし、cloudwatchの料金は意外と高いため注意が必要です!
参考
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/Streams.Lambda.Tutorial.html


Invitation from 株式会社コムデ
If this story triggered your interest, have a chat with the team?
Dynamodbを可視化グラフ化









