
目次
Introduction
Cooperation
Partnership
Shared Kernel
Customer-Supplier
Conformist
Anticorruption Layer
Open-Host Service
Separate Ways
Resources
Introduction
In Domain-Driven Design (DDD), the bounded context pattern is essential for breaking down complex systems into manageable, well-defined components.
A bounded context has several key characteristics:
- Clear Boundaries: Each bounded context establishes a physical boundary where a specific model and its ubiquitous language apply.
- Team Ownership: A bounded context and its ubiquitous language can be implemented and maintained only by a single team.
- Independence: Each bounded context operates separately from the rest of the system, enabling independent changes, evolution, and lifecycle management without impacting other contexts.
However, while bounded contexts are designed to be independent, they still must work together to form a cohesive system.
The challenge is establishing integration mechanisms that allow bounded contexts to interact while maintaining their autonomy and minimizing the impact of changes across contexts.
This post explores DDD patterns for defining integrations between bounded contexts. These patterns are driven by the nature of collaboration between teams working on bounded contexts.
The patterns are grouped into three categories, each reflecting a different type of team collaboration:
cooperation, customer–supplier, and separate ways.
Let’s dive in.
Cooperation
Cooperation patterns apply when teams communicate effectively and collaborate closely across bounded contexts.
In the simplest case, these are bounded contexts implemented by a single team.
Partnership
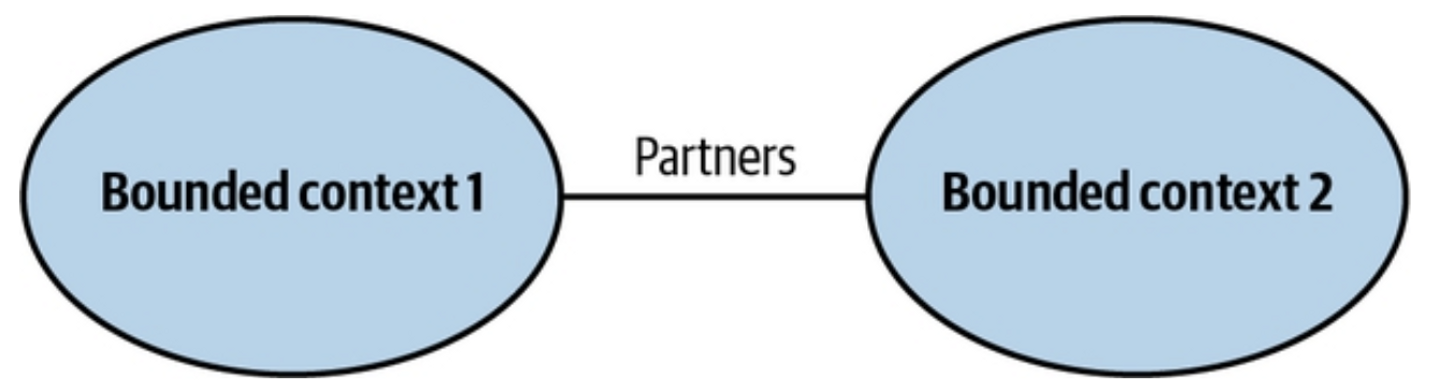
Overview
The Partnership Pattern is used when two teams working on separate bounded contexts collaborate closely to ensure smooth integration. Teams notify each other about changes, resolve integration issues together, and adapt without conflict.
How it works
Integration is a two-way process—neither team dictates the published language. Instead, both sides negotiate and choose the best solution collaboratively.
One team notifies the other about API changes, and the second team adapts smoothly - no drama or conflicts.
Neither team is interested in blocking the other one.
Successful implementation requires well-established communication practices, frequent synchronization, and a high level of commitment between teams. Continuous integration helps minimize the feedback loop and resolve issues quickly.
When to use
- When teams have strong, effective collaboration.
- When frequent synchronization is feasible and beneficial.
When not to use
- When teams are geographically distributed or have significant time zone differences.
- When one team has strict control over the integration.
- When collaboration is weak, leading to delays or misunderstandings.
Shared Kernel
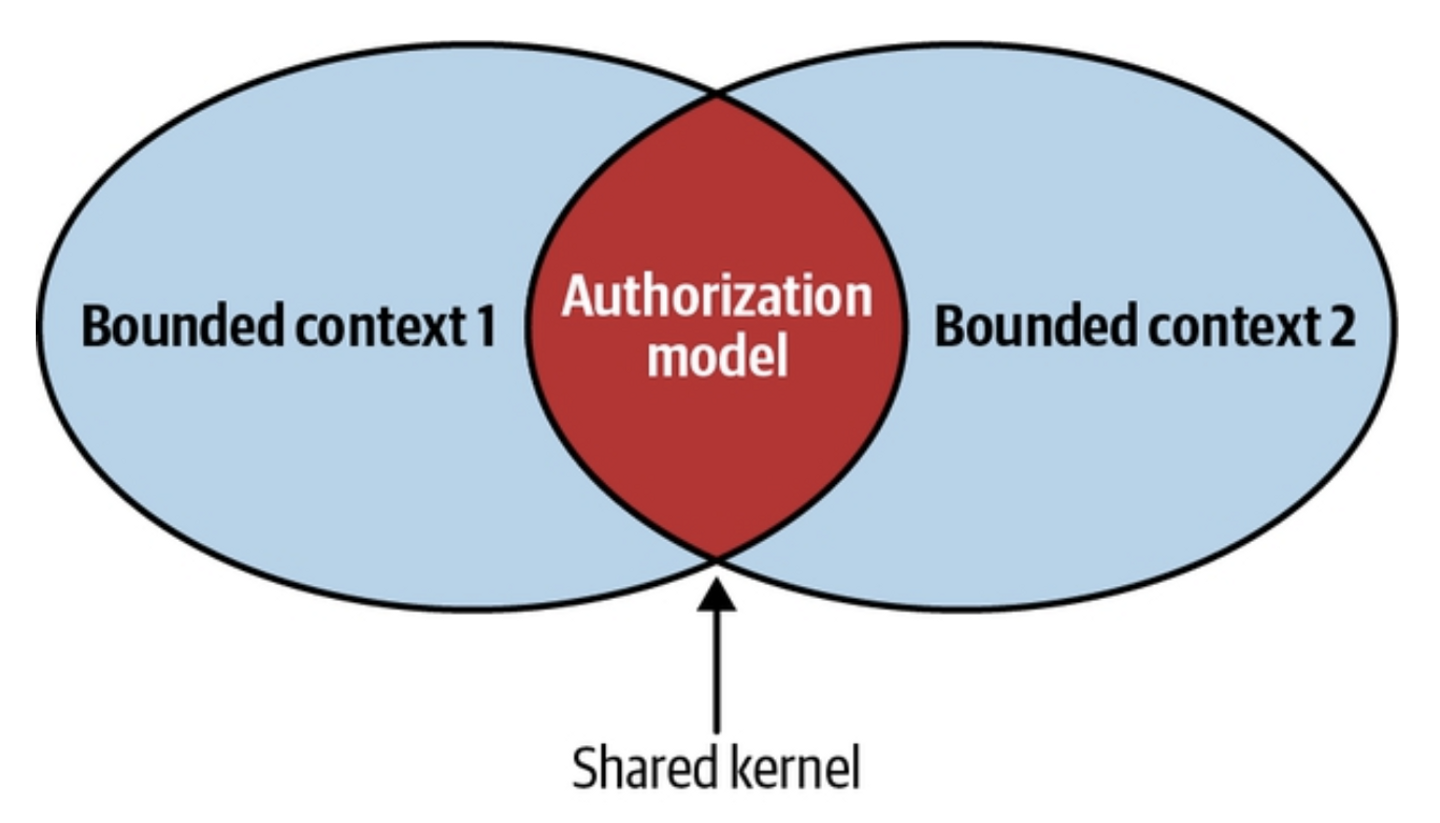
Overview
Shared Kernel Pattern is used when multiple bounded contexts need to share a common model or a subset of it.
A shared kernel is a pragmatic exception to strict bounded context separation. It should be used cautiously, ensuring that its benefits outweigh the challenges of maintaining a shared, evolving model.
How it works
A shared kernel is a portion of the domain model that multiple bounded contexts rely on. Any modification to this shared model immediately affects all contexts using it. To minimize disruption, the shared kernel should be limited in scope, ideally covering only essential integration contracts and data structures that are intended to be passed across the bounded contexts.
From an implementation perspective:
- In the case of a monorepo, shared files can be referenced directly.
- If separate repositories are used, one of the following approaches can be used:
- Published library – The shared kernel can be extracted into a versioned library and published (e.g., using Maven or Gradle).
- Linked library – The shared kernel can be included as a directly referenced source (e.g., via Git submodules).
- Continuous integration is essential to ensure that changes do not introduce inconsistencies across bounded contexts.
- Each change to the shared kernel must trigger integration tests for all the affected bounded contexts.
When to use
- When multiple bounded contexts must share a consistent model.
- When the cost of duplication is higher than the cost of coordination.
- When bounded contexts belong to the same team or have strong collaboration.
- When refactoring a legacy system, use a shared kernel as a transition phase.
When not to use
- When teams prefer to evolve models separately.
- When the shared model is unstable and changes frequently, causing disruptions.
- When collaboration is weak, leading to delays or misunderstandings.
Customer-Supplier
Customer–supplier patterns apply when one bounded context (the supplier) provides a service to other bounded contexts (the customers). Unlike cooperation patterns, the success of each team is not strictly tied to the other. This often results in an imbalance of power, where either the upstream (supplier) or downstream (customer) team dictates the integration contract.
Conformist
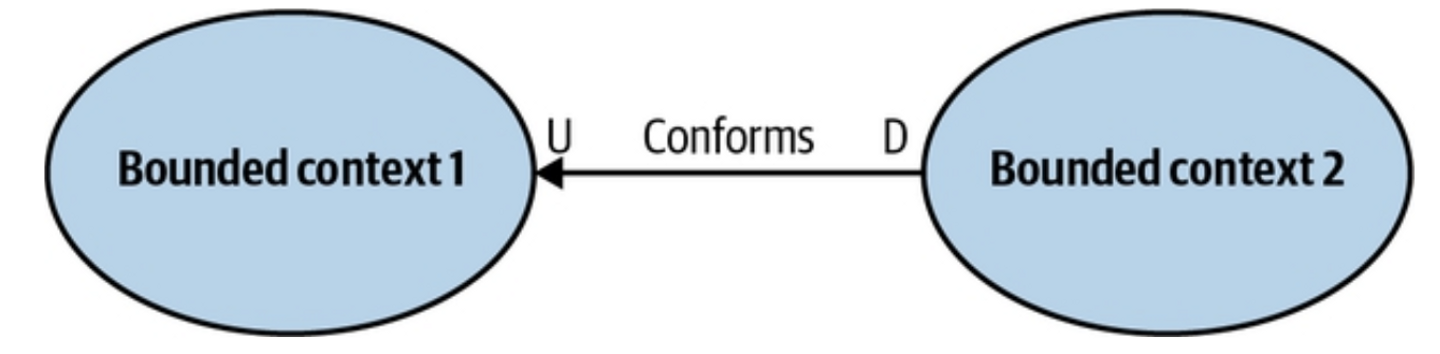
Overview
In this case, the balance of power favors the upstream team, which has no real motivation to support its clients’ needs. It just provides the integration contract, defined according to its own model—take it or leave it.
Such power imbalances can be caused by integration with service providers that are external to the organization or simply by organizational politics.
If the downstream team can accept the upstream team’s model, the bounded contexts’ relationship is called conformist.
How it works
The downstream team adopts the upstream’s model without introducing an additional translation layer. Instead of negotiating changes, the downstream simply integrates with the upstream as-is.
When to use
- When the upstream service follows a well-established industry standard.
- When the integration contract is stable and reliable.
When not to use
- When the supplier model is messy or inconvenient for the customer’s needs.
- When the upstream service is unstable or frequently changing.
- When the downstream team requires greater autonomy over its model.
Anticorruption Layer
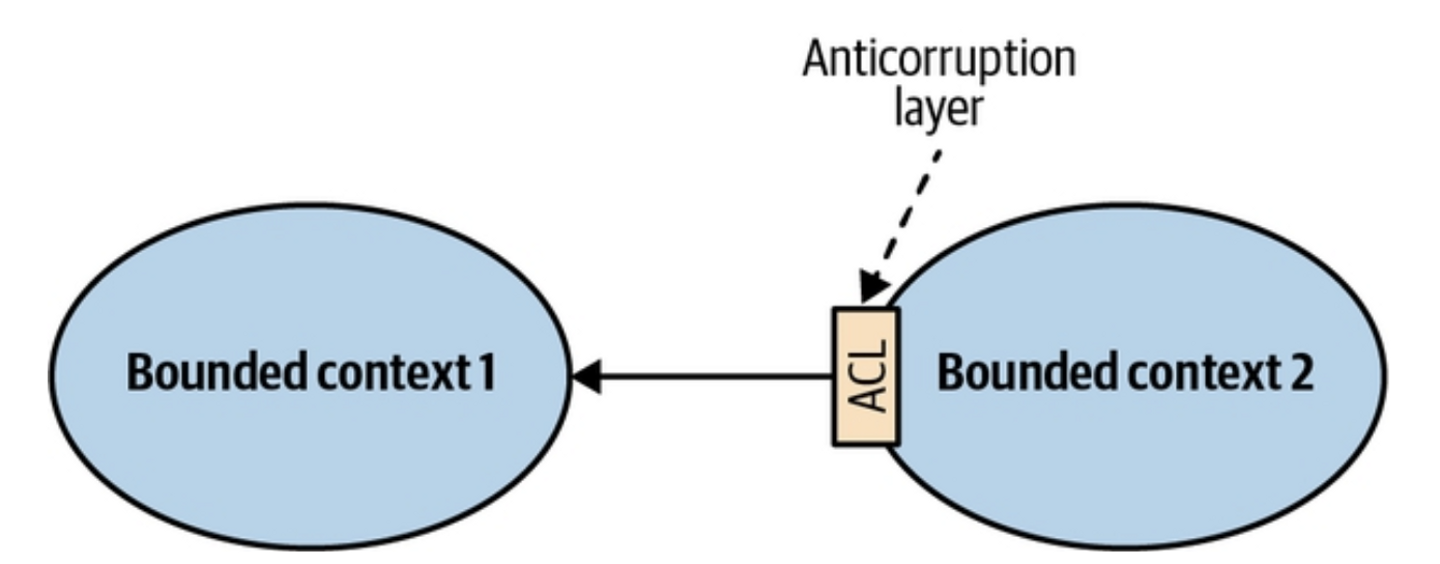
Overview
As in the Conformist Pattern, the balance of power in this relationship favors the supplier. However, in this case, the downstream bounded context is not willing to conform.
Instead, the downstream service introduces an anticorruption layer (ACL) to maintain control over its own model.
How it works
The customer can translate the upstream bounded context’s model into a model tailored to its own needs via an ACL.
ACL handles both model translation and infrastructure concerns.
As a result, changes in the supplier’s model affect only the translation mechanism, keeping the integration flexible, stable, and loosely coupled.
From a modeling perspective, the ACL isolates the customer from foreign concepts, simplifying the customer’s ubiquitous language and model.
When to use
- When the downstream bounded context contains a core subdomain that should be protected from foreign concepts.
- When the supplier model is messy or inconvenient for the customer’s needs.
- When the supplier changes frequently, and the customer wants to minimize disruptions.
When not to use
- When the supplier model is already a good fit making an extra translation layer unnecessary.
Open-Host Service
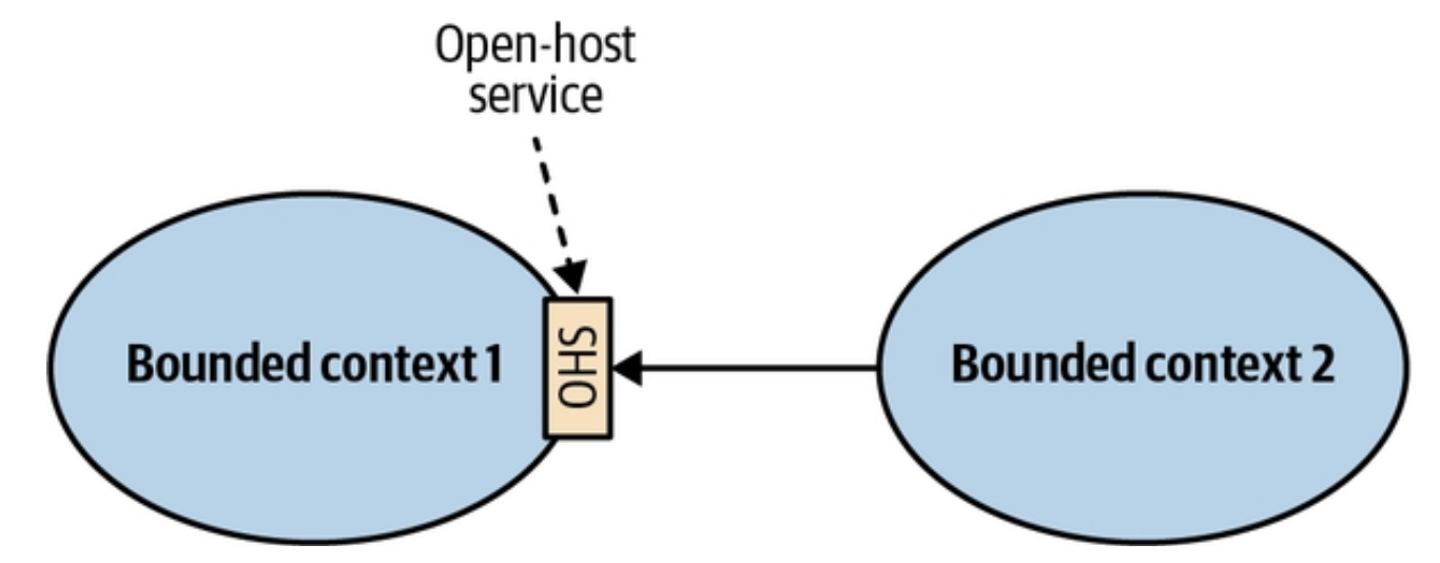
Overview
The Open-Host Service Pattern applies when the balance of power favors the downstream consumers.
The supplier is interested in protecting its consumers and providing the best service possible.
How it works
To protect the consumers from changes in its implementation model, the upstream supplier decouples the implementation model from the public interface.
This public interface is a stable, integration-friendly protocol tailored for external consumers, called Published Language.
This decoupling allows the supplier to evolve its implementation and public models at different rates,
It also enables versioning, so multiple consumers can adopt new changes gradually without being forced to upgrade simultaneously:
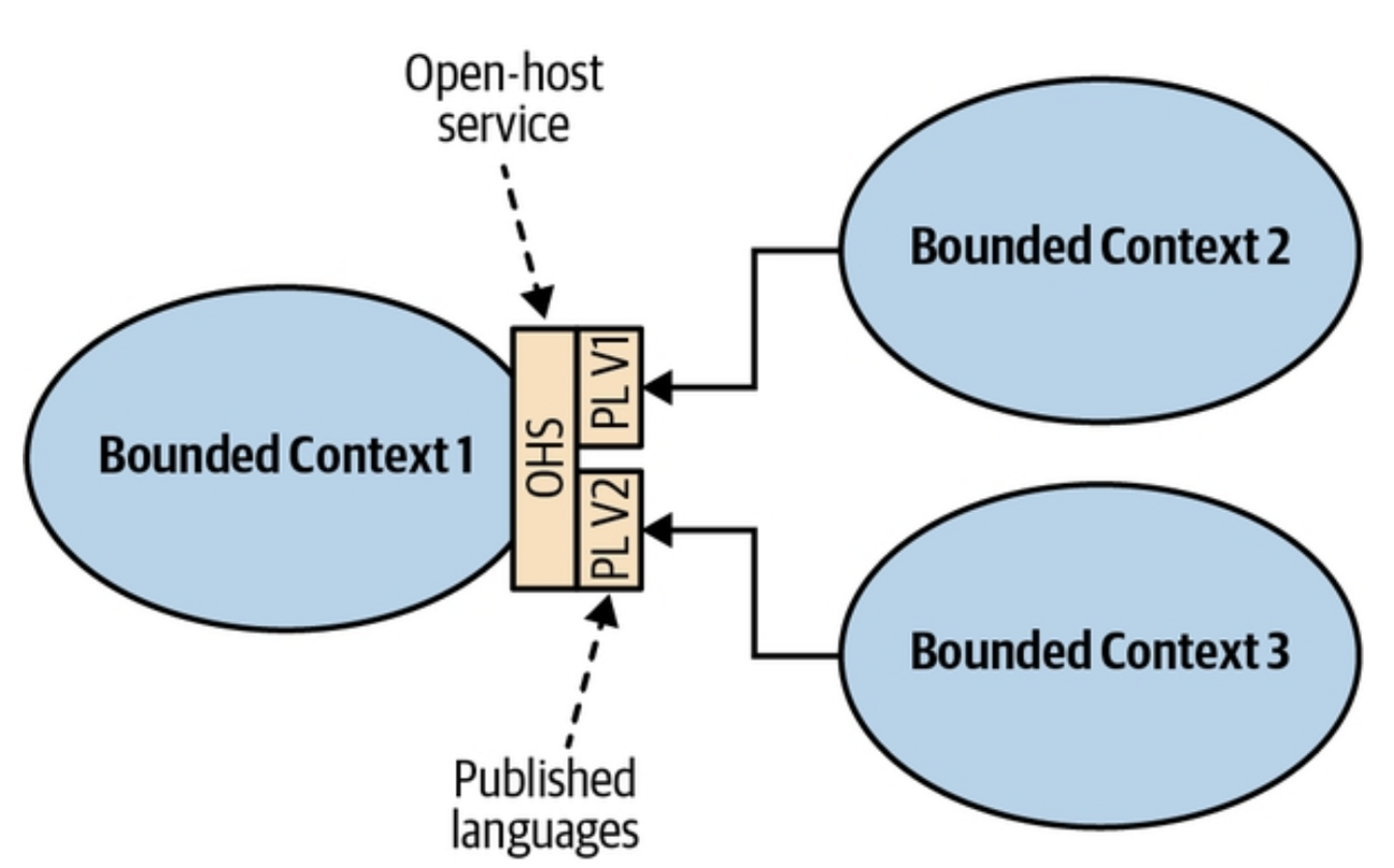
When to use
- When the supplier's internal model is expected to change frequently.
- When consumers require a stable, well-defined integration interface.
- When enabling gradual migration between versions is important.
When not to use
- When the supplier's internal model is already stable and aligned with consumer needs.
Separate Ways
Overview
The last collaboration option is not to collaborate at all. This pattern can arise for different reasons, in cases where the teams are unwilling or unable to collaborate.
This might be due to organizational barriers, communication difficulties, or differences in models that make integration too costly or impractical. Instead of sharing functionality, each team implements its own version independently.
How it works
Instead of integrating, teams duplicate functionality within their own bounded contexts. This can reduce coordination overhead, especially when collaboration is slow, difficult, or not cost-effective.
When to use
- When communication between teams is difficult or slow.
- When the subdomain in question is generic and easy to duplicate.
- When bounded contexts have fundamentally different models that are hard to align.
- When the cost of collaboration is higher than the cost of duplication.
When not to use
- When working with a core subdomain.
Duplicating the implementation of such subdomains would defy the company’s strategy to implement them in the most effective and optimized way. - When duplication creates a maintenance burden or leads to inconsistencies.
- When future collaboration is expected or needed.
Resources
Mainly the following book by Vlad Khononov:
Learning Domain-Driven Design: Aligning Software Architecture and Business Strategy
/assets/images/2809871/original/d94cff11-482c-401f-968c-7d38d7f1d867?1571658343)


/assets/images/2809871/original/d94cff11-482c-401f-968c-7d38d7f1d867?1571658343)
/assets/images/6144578/original/d94cff11-482c-401f-968c-7d38d7f1d867?1611534232)


