こんにちは!バックエンドチームマネージャーの @tsuwatch です!
2022/9/8〜10に三重県にて開催されたRubyKaigi 2022でプラチナスポンサーとして協賛し、スポンサーブースを出展しました。
弊社からは WEAR を開発するバックエンドエンジニア、SRE、PdMなど合計10名ほどが現地で参加しました。
我々が運営しているファッションコーディネートアプリ「WEAR」のバックエンドはRuby on Railsで開発しています。2013年にVBScriptで作られたシステムですが、2020年くらいからVBScriptのシステムをコードフリーズし、リプレイスをはじめました。現在もリプレイスを進めながら、新規の機能もRubyでどんどん開発しています。
また弊社ではRubyコミッタのsonotsさんがいたり、顧問としてMatzさんにもご協力いただいており月に一度、Matzさんに何でも聞く会をやっていたり、積極的にRubyを活用しています。
今回もエンジニアによるセッションの紹介とブースでの取り組みについて紹介します。
エンジニアによるセッション紹介 弊社エンジニアによるセッションの紹介をします。
How fast really is Ruby 3.x?
高久です。Fujimoto Seijiさんのセッション「How fast really is Ruby 3.x?」についてご紹介します。
このセッションでは、Rubyの過去バージョンと比較しRuby 3.xではどれくらい早くなったかを、実際のアプリケーションを用いて検証した結果を報告しています。検証対象のアプリケーションはFujimoto Seijiさんがコミッターを務めるFluentdです。
検証の背景について。まず前提としてRuby 3は「Ruby 3×3」という「Ruby 2.0の3倍早くする」ことを目指して開発が進められました。そして過去のRubyKaigiでも同様に実際のアプリケーションを使った検証の話がいくつかありました。しかし、どれもRailsアプリで作られたものでは3倍にならないという話でした。なぜならRailsアプリは基本的に、アプリケーションの多くの時間を占めているのがRubyの処理ではなく、DBなどの外部処理によるものだからです。Rubyを早くしたとしても、その他にかかる時間が大きいため、全体の処理時間の短縮化に大きく寄与するものではありませんでした。
そこで今回、多くの処理をRubyで行なっているFluentdを対象に測定してみたらどうなるか? というのがテーマとなっています。
検証は読み込ませるファイルごとに2パターン行なっています。
検証した結果Ruby 1.9と比較しRuby 3.2(YJIT有効)は、LTSVファイルで約3.15倍、nginxログファイルで約2.5倍のスループットが出ることを確認できました。Ruby 1.9と3.2の比較にはなりますが、概ね「Ruby 3×3」は実現しているのではということが、Fujimoto Seijiさんが伝えたかった内容になります。
セッションでは、更に他の言語と比較してどうかを述べていました。気になる方は是非スライドをご確認ください。
コミッターさんたちがRubyをより良くするために開発をし、Rubyが日々進化していることを実感した発表でした!
Make RuboCop super fast
小山です。RuboCopメンテナの@koicさんによる「Make RuboCop Super fast」の発表を紹介します。
RuboCopは2012年4月21日がファーストコミットで今年10周年を迎えました。RuboCopは現在1.36.0が最新バージョンでありますが、2.0系リリースに向けてマイルストーンを掲げており、この発表はそのマイルストーンのうちの1つであるRuboCop2×2に関する発表でした。RuboCop2×2はRuby 3×3で目指しているように、RuboCopの速度を1.0系と比較し、2倍を目指すというものです。
RuboCopはCaching、Multi-cores、Reduce unused requires、Daemonizeの4つのアプローチで高速化を図っています。
Cachingはかねてから提供されていて、1回検査したコードはデフォルトで ~/.cache/rubocop_cacheに保存しています。
Multi-coresは1.19からデフォルトで並列検査するようになり、1.32から並列でオートコレクションするようになりました。8 core CPUかつHyper-Threadingを使用して約1,300ファイルに対して直列実行と並列実行を比較した場合、直列実行は61秒で完了したのに対し、並列実行は10秒で完了したそうです。
Reduce unused requiresは --onlyオプションを付与したとしてもすべてのCopが読み込まれてしまう問題がありました。require 'rubocop' の改善により高速化を実現しており、セッションの本論で話されていたserverモードと一部関連があります。
Daemonize(serverモード)がセッションで一番厚くお話されていた内容になります。serverモードは #10706 で対応されて1.31から導入されています。使用することでrubocopコマンドを実行する度にプロセスを起動するのではなく、プロセスを常駐することでモジュールの読み込みが初回のみになります。Client/Serverモデルを採用して高速化を実現していたサードパーティ製のgem、rubocop-deamonを統合することで、RuboCopのserverモードは高速化されています。Client/Serverモデルとは、Server側の初回プロセスであらかじめモジュールを読み込んでおいて、Client側がすでにモジュールを読み込んでいるサーバーに接続するアプローチです。またrubocop-daemonをどのように統合したか、serverモードの設計、具体的な使用方法についてはセッション内で詳しく解説されていますので気になる方は是非スライドをご覧ください。
成果としては、moduleの読み込みを必要なもののみにし、serverモードを実装したことで850倍高速化されています。驚くべき成果です。
RubyのDX向上に、すぐに繋がると実感した素敵な発表でした。まだ不安定な挙動が残っているとの補足はありましたが、RuboCopのバージョンを上げて積極的に使っていきたいです!
The Better RuboCop World to enjoy Ruby
三浦です。私からはOhba Yasukoさん(@nay3)によるセッション "The Better RuboCop World to enjoy Ruby" について紹介したいと思います。技術的なセッションからは少し視点を変えた、RuboCopとうまく付き合っていくにはどうしたら良いかを考える内容になります。
RuboCopはRubyの静的コード解析ツールの1つで、コーディング規約を守れていないコードを簡単に確認でき、自動で修正できる便利なツールです。CIで回して事前に修正しておくことでレビューの負担軽減にも繋がります。
ただこのRuboCopのルールは "状況に合わないこと" もあります。例えば "Naming/PredicateName" というルールは、has , is , have_ といった特定の接頭辞のメソッド名をチェックし、接頭辞を排除したメソッドを使うよう警告します。
# bad
def is_child?
end
def has_child?
end
# good
def child?
end
ただ child? にしてしまうと、どちらとも捉えられるような曖昧なメソッド名になってしまいます。
"is child" なことをチェックするメソッド "has child" なことをチェックするメソッド このようにRuboCopの中にはルールとして間違ってはいないけど状況によっては合わないルールがいくつか存在しています。
初心者〜初級者のエンジニアの場合、状況に合っていないルールなのかを判断するのは難しいです。そのためRuboCopの警告に忠実に従ってコーディングをしてしまい、その結果かえって読みにくいコードになってしまう場合があります。
レビューで指摘された軽微な修正でも直そうとするとRuboCopのルールに引っかかってしまい、複雑な実装になってしまったなんてこともよくあります。(私もありました、、、) このような状況に合わないルールで振り回されてしまうのは、開発速度を低下させる一因にもなります。
RuboCopの全てのルールは、無効にしたりデフォルトとは異なる方針に変更できます。また、特定のコードで特定のルールを無視できます。しかしこのルールの設定の判断はルールの妥当性を判断できる技術力と経験が必要です。初心者〜初級者のエンジニアにとってはこの判断はなかなか難しいものです。かといって経験者が1つ1つのルールを必要か毎回確認するのも大変です。
そこで提案されたのがルールを大きく2つのレベルに分けて考えることでした。
強制レベル:ほぼ100%の状況で適用しても問題がないようなルール 参考レベル:なるべく多くの改善ポイントに気付けるような理想的なルール この2つのレベルに合わせてrubocop.ymlの設定ファイル自体を分けておきます。強制レベルのルールは現状通りCIなどで警告を出し、修正を強制します。参考レベルのルールはCIを回しますが、参考情報として表示するだけに留めておきcommitの禁止やマージの禁止といった強制力は持たせないようにします。
このように参考レベルのルールを作っておくと全てのルールに従おうとして不自然なコードを作ることを防ぐことができるので良いのではということでした。Ruby初心者にとってのつまづきポイントなどもたくさん紹介しており、うなずきたくなるような共感できる内容でした。スライドのイメージ図は全て画像生成AIのMidjourneyを使って生成したものだそうで笑いも起こる楽しいセッションでした。
Implementing Object Shapes in CRuby @tsuwatch です。個人的におもしろそうだなと思っていたObject Shapesというオブジェクトのプロパティを表現する手法について書こうと思います。Object Shapesを導入することでインスタンス変数のを見つけるときのキャッシュヒット率の増加とランタイム時のチェックを減らすことができ、JITのパフォーマンスを向上させるというものです。また、この手法はTruffleRubyやV8で採用されているそうです。
詳細はチケットにあるのでご覧ください。
Object Shapesとは
class Foo
def initialize
# Currently this instance is the root shape (ID 0)
@a = 1 # Transitions to a new shape via edge @a (ID 1)
@b = 2 # Transitions to a new shape via edge @b (ID 2)
end
end
class Bar
def initialize
# Currently this instance is the root shape (ID 0)
@a = 1 # Transitions to shape defined earlier via edge @a (ID 1)
@c = 1 # Transitions to a new shape via edge @c (ID 3)
end
end
foo = Foo.new # blue in the diagram
bar = Bar.new # red in the diagram
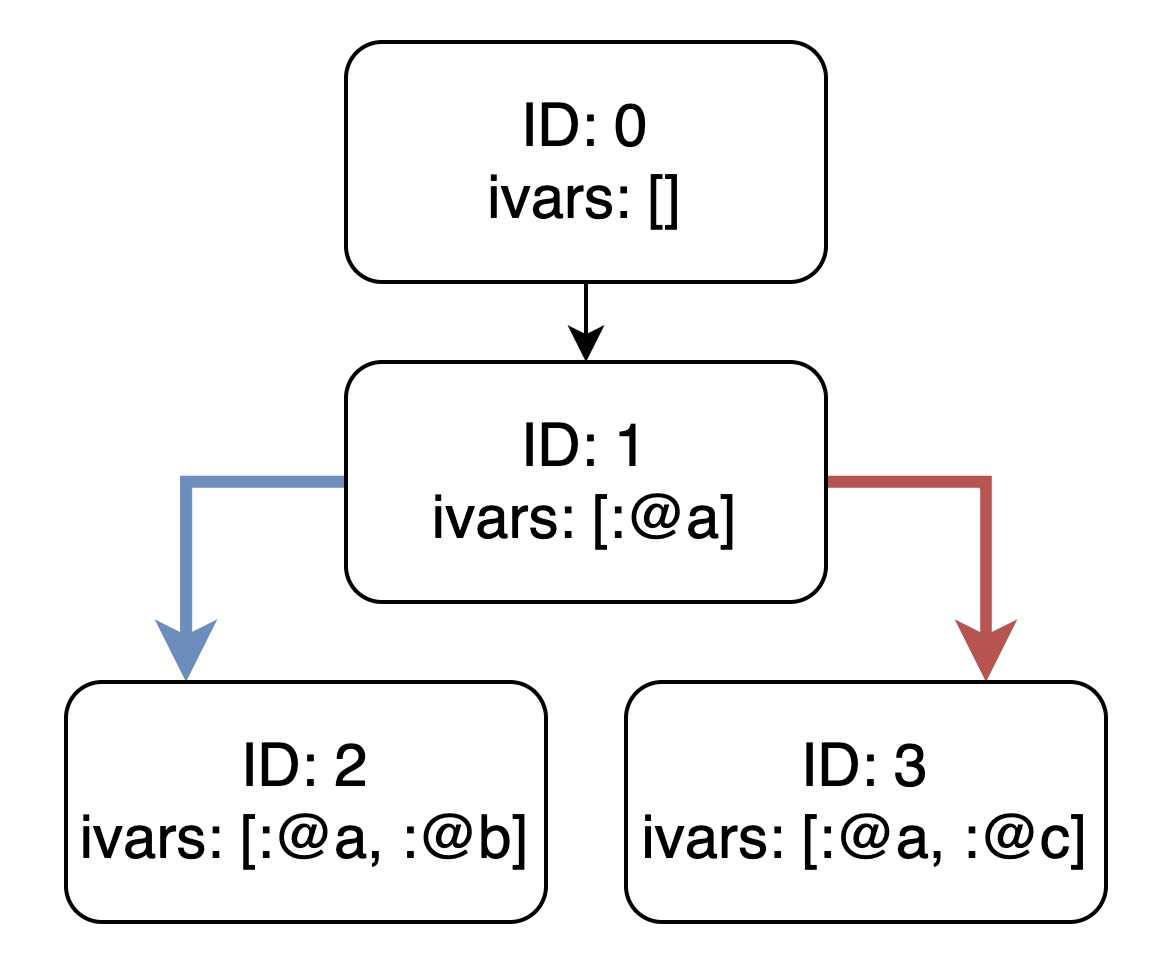
例えばこういうコードが存在したときにObject Shapesは以下のようなツリー構造を構築します。
インスタンス変数の遷移をツリー状に構築することで、同じ遷移をするクラスはキャッシュを利用できます。別のクラスをnewしたときにも元のShapesの差分のみ作れば良いというわけです。
class Hoge
def initialize
# Currently this instance is the root shape (ID 0)
@a = 1 # Transitions to the next shape via edge named @a
@b = 2 # Transitions to next shape via edge named @b
end
end
class Fuga < Hoge; end
hoge = Hoge.new
fuga = Fuga.new
現在はクラスをキャッシュキーとして使用しており、その場合はこのコードではキャッシュヒットさせることはできません。Object Shapesを導入することでクラス依存しないキャッシュを実現し、キャッシュヒット率を上げることができます。
複雑そうですが、効果がありそうなパフォーマンスチューニングです。キャッシュの構造や実際にどれくらいパフォーマンスが改善するのか今後もウォッチしていこうと思います。
続きは こちら

/assets/images/7661308/original/3a023d97-0ee4-488d-a826-b9ee662c0ee1?1632994701)


/assets/images/7661308/original/3a023d97-0ee4-488d-a826-b9ee662c0ee1?1632994701)
/assets/images/7661308/original/3a023d97-0ee4-488d-a826-b9ee662c0ee1?1632994701)


