

こんにちは。Quipper採用担当の鈴木です。今回の記事は、VP of Engineeringのbeniyamaによる「Google I/O で、進みゆく世界の背中を見てきた」です!弊社には業務上必要な自己の能力開発を目的に国内/海外の研修への参加について起案できる制度(※)があり、今回はそちらを利用してテックカンファレンスに参加しました。是非、ご覧ください!
こんにちは、id:beniyama です。5月7日から9日までの三日間、Mountain View で開催された Google I/O 2019 というイベントに参加してきました。今年もチケット抽選を引き当てて、去年に引き続きの参戦です。
野外テックフェス、Google I/O
Google I/O はその名の通り Google 社が開催しているテックカンファレンスで、4月開催の Google Cloud Next につづく大規模なイベントです。GCP 周りの話が主な Cloud Next に比べると、Android や Google Assistant、あるいは Google AI といった幅広い技術寄りのトピックがメインで、エンジニアやデザイナーといった開発者を主なターゲットにしているのが特徴です。
Mountain View の Googleplex(Google 本社)にほど近い、Shoreline Amphitheater という野外劇場にステージを建造して開催されるので、気分はだいぶ野外フェスっぽくなります(野外フェス行ったことないので完全なる想像ですが)。


<野外フェスっぽさある会場。メインセッションは芝生からも観戦?できる。>
今年は 7,200 人が現地参加し、数百万人もの人たちがライブストリーミングで全世界から視聴していたとのことでした。また、今年から AR を使った会場案内やフォトブースが設置されるなど、ちょっとした仕掛けもありました。

<I/O アプリの AR モードを起動した様子。日本語対応!>
イベントのまとめは既に様々な記事があるので、詳細はそちらをご覧いただければと思いつつ、本記事では私的に最も印象に残った下記3つのトピックについてご紹介します。
- エッジコンピューティングの進化
- 検索という体験の見直し
- 見えてきた AI プロダクトとの付き合い
1. エッジコンピューティングの進化 ~ 手元で AI が当たり前に ~
今回の I/O のビッグテーマの一つは紛れもなく『エッジコンピューティング』だったと思います。機械学習から AR、はたまた STADIA というゲームサービスに至るまで、今回の I/O で披露されたモバイル UX の進化は想像以上のものでした。
機械学習においては Google Assistant で使用しているモデルを 100GB から 0.5GB!まで圧縮することに成功。外部通信を必要としないオンデバイスでの音声認識を実現しています。その結果、リアルタイム性の向上(最大で従来比10倍)とプライバシー情報を端末内に留めることが可能になりました。また、個々人の環境で取得されたデータをオンデバイスで学習し、その結果のみを集約してさらに精度を上げる『Federated Learning』にも注力しています。
何種類ものタスク操作を音声コマンドで切り替えながら実行するデモがあったのですが、オンデバイスで処理が完結するためタスク切換えが非常に速く、また「OK Google」と毎回言わなくても認識するようになったために自然な操作感を獲得しています(下記動画の 22:41 あたりをご覧ください)。
https://www.youtube.com/watch?v=lyRPyRKHO8M&feature=youtu.be&list=PLOU2XLYxmsILVTiOlMJdo7RQS55jYhsMi
YouTube だけでなく自分で撮影した動画に字幕をつけたり(Live Caption)、リアルタイム Text-to-speech / Speech-to-text でテキスト入力での電話応対を可能にしたり(Live Transcribe)というようなユースケースを見ていて、認識精度の高さでこういった機能の恩恵を十分に受けられるであろう英語圏の人々がとても羨ましくなりました。
2. 検索という体験の見直し ~『Search』から『Ask』へ ~
今回の I/O では、Google の代名詞とも言える『検索』にも変化の兆しを感じました。検索結果に 3D モデルが表示され、そこから AR で高精細な 3D オブジェクトを呼び出して実空間に投影できる…というのもあるのですが、気になったのは『Google Assistant との融合』です。

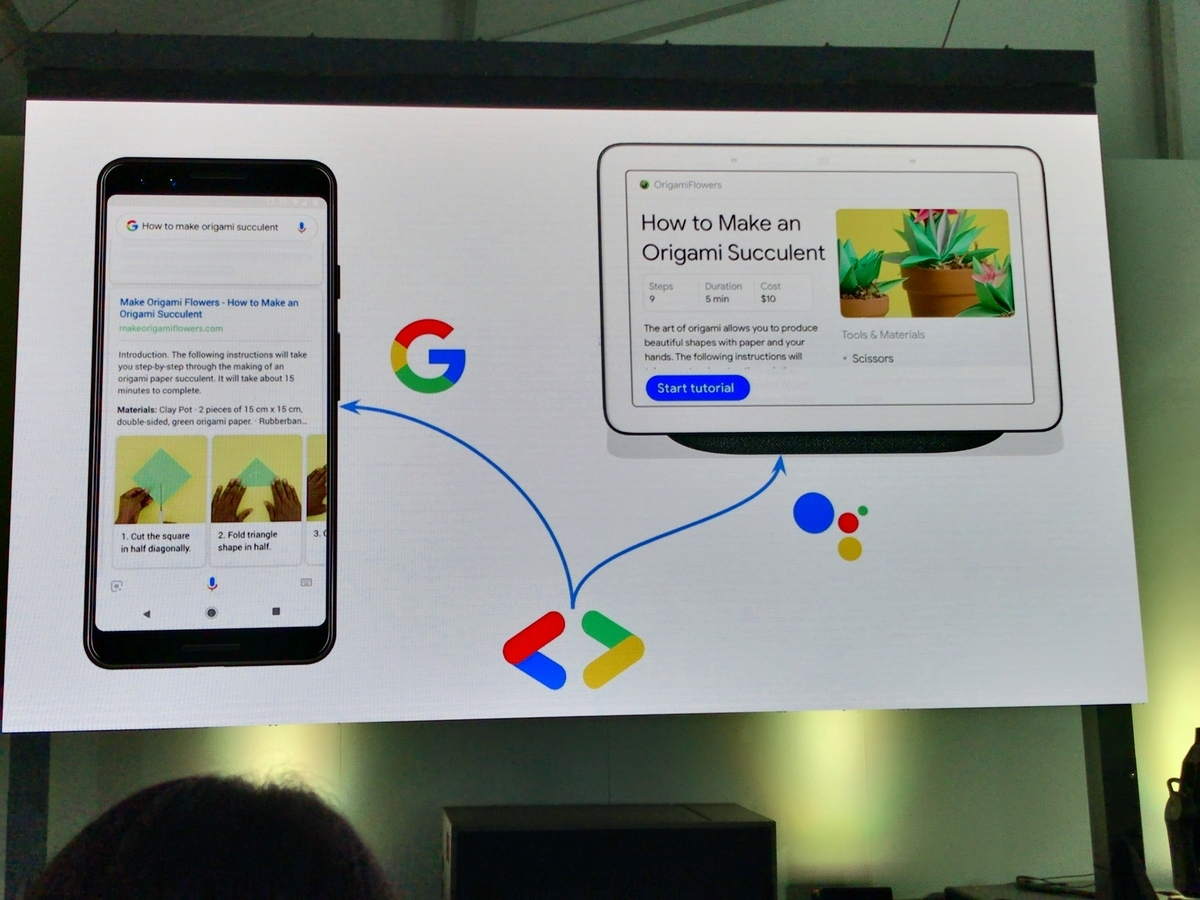
Enhance Your Search and Assistant Presence with Structured Data より、融合する SearchとGoogleAssistant
今回、Actions on Google ではステップ別の動画で料理のレシピなどを説明する『How-to』や、サイト内 FAQ を Google Assistant 経由で提供可能にする『FAQ』という新たなコンテンツ形式をサポートしました。特殊なタグで Web ページをマークアップすることで、Google 検索と Google Assistant 経由での問い合わせに対して、同じ結果をそれぞれのデバイスに適したフォーマットで返すことができます。
これまで検索は、提供された検索結果を自ら見たり読んだりするという能動的な動きを必要とするアクションでした。一方、Actions on Google との融合がより進んで構造化されたリッチコンテンツをサポートすることによって、PC やスマホの前という限定的なシーンではなく、日常の動作の中でちょっと「教えてもらう」「尋ねる」ようなやや受動的なインタラクションも可能になりつつあります。もう一つのキーワードでもある『AI for everyone』に向けた進歩だと感じました。
昨年の I/O でも触れられていましたが、これからのコンテンツ制作は、より多様なシーン、多様なデバイス、多様なモダリティを想定しながら(単に検索結果を返すだけではなく)いかにユーザーをアシストできるか?という観点が求められていくのだと思います。Web・アプリデザインだけでも大変なのに、UX デザインのカバーする領域が爆発的に拡がりそうな予感がしました。
3. 見えてきた AI プロダクトとの付き合い方 ~ ユーザー中心の開発へ ~
[https://events.google.com/io/schedule/events/5d8b65d2-5369-4f0e-ba3c-ea048fd80999:title] というセッションではユーザー志向な AI プロダクトを開発するためのガイドブックである People + AI Guidebook が発表されました。これまでも Google では AI Principles という Google の考える AI はかくあるべきという原則集を持っていたのですが、今回のガイドブックはそれを実際のプロダクト開発において実現するためにどうすればよいか?という疑問に答えるものになっています。
例えば「AI で解決できる何かを探す」のではなく「◯◯(ユーザーの課題)を AI で解決できるか考える」ことから始め、果たしてそれが AI を適応すべき課題なのかどうか、また 『Augmentation(拡張)』と『Automation(自動化)』のどちらのタイプを考えるべきか?などというようなチェックポイントが読みやすい形で記載されています。数多くの AI プロダクトを開発してきた Google のエッセンスが詰まったガイドラインと言うことができそうです。
またガイドラインに限らず今回の I/O で繰り返し強調されていたのは、昨今大きな議論を巻き起こしているプライバシー保護についてです。様々なセッションにおいて、事あるごとにユーザーデータを端末に留めてオンデバイス処理を実行していることを強調していました。今回、Google Maps でも Incognito モードの提供が発表されるなど、かなりプライバシー周りのトピックをケアしていることが伺えます。
一方でプロフィール情報を明示的に提供すれば、より便利なサービス(家族情報などに応じてパーソナライズされたナビゲーションなど)を享受できることもアピールしていました。今後の AI プロダクトはデータ収集がどのようにユーザー価値につながるのかを明らかにし、より多くの情報の提供を許可してもらえるように便益やリスクを伝えていけるかが重要になってきそうです。
まだまだ他にも Stadia とか Pixel 3a とか Nest Hub Max とか Google Lens とか 5G x AR とか Jeff Dean とか Geoffrey Hinton とか色々トピックはあるのですが、その辺は割愛させていただきます。
リアリティを持ち始めた AI プロダクト、聞こえ始めた AI 格差の足音
今回象徴的に感じたのは、去年会場を大いにどよめかせた『Google Duplex』(AI が人間の代わりに電話をかけて美容院などの予約をしてくれる)がややトーンダウンして『Google Duplex for Web』(AI が人間の代わりに Web フォームを入力してくれてレンタカーなどの予約をしてくれる)に置き換わったことでした。かなり挑戦的な取り組みだと感じた去年からすると現実的なスコープになり、ある意味 AI 技術の実現可能性とビジョンのバランスがとれるポイントを見定めたようにも感じました。
そして今回披露された機能群も、コンセプトベースではこれまで誰かがやっていたものばかりで真新しさはありませんでしたが、Pixel 3a のような廉価帯デバイスも含めて、『AI for everyone』という形で多くの人に実用的な精度・速度で提供されるようになってきたというのが最も大きなポイントだったかと思います。
その一方で、特に音声認識・自然言語処理においては英語圏、あるいはデータの集まりやすさや言語仕様の観点などから機械学習との相性が良い国の方がこういった AI プロダクトの恩恵を早く受けることができ、追々 AI 格差が生まれてもおかしくないなと感じました。Quipper ではインドネシアやフィリピン、メキシコといった国でもサービスを展開していますが、2〜3年後にはこれらの国々の方が日本国内より先進的な AI アシストを受けているかもしれません。
実際、識字率がまだまだ高くない国でのテストで、ユーザーが「カメラで写した文字を読み上げるという AI 機能のサポートで ATM からお金を引き出したり、電車のチケットを買えるようになった」というような逸話も紹介されていました。
教育という文脈でもこのような AI プロダクトの影響はますます大きくなっていくと思いますので、引き続き国内外の技術トレンドをキャッチアップしながら、最高の学習体験を生み出せるプロダクト開発に取り組んでいこうと思います!
(※) 本制度はエンジニア、デザイナー及びプロジェクトマネージャー職種の方に適用されます。

/assets/images/8020079/original/f5632a6b-81e7-484b-87e8-9a2dd6aeeee7?1635733533)




/assets/images/8499187/original/1944cc29-7cbf-49e3-a0e7-345d3a36e4b1?1642059254)


