
こんにちは、SRE(Site Reliability Enginner) の @showwin です。前回の LAPRASインフラチームで避難訓練を行いました の記事に引き継ぎ、今回もSREチームの取り組みの紹介です。
概要
2021年2月からSLI, SLOを定めた運用を開始し、約半年が経過しました。導入の背景や、運用開始までの流れ、実際に運用してみて気付いたことをまとめました。
体制としては、SREチームはフルタイム1名、適宜手伝っていただけるメンバー2名で構成されており、アプリケーションエンジニアが9名です。また、サービスの利用者に対してはSLAを提示しておりません。このような状況下において運用されているという前提で読み進めていただけたら幸いです。
SLO導入に至った経緯
前任のインフラエンジニアの退職により、2020年9月より私がその役割を引き継いだのですが、なんとなくカッコ良さそうという理由で "SRE" という役職名を自分に付けました。インフラエンジニアではなく、SREと名乗ったのだから、そもそもSREが何をすべきエンジニアなのかきちんと理解するところから始めようと思い、あの有名な SRE本 を読むことにしました。ただ、自分だけがその役割を理解していても周りのメンバーがSREとは何なのかを理解していなければ、自分は動きにくく、また周りからも適切なリクエストが来ません。そこでSREチーム + 興味のあるエンジニアでSRE本の輪読会を行うことにしました。詳細には踏み込みませんが、毎週1時間時間を取って約50ページずつ読み進め、10月末から開始して年末には読み終えました。
SRE本を読んだ結果、SREという役割はSLI, SLOの運用あっての存在であることがわかり、とりあえずSLOを導入してみることにしました。SLOを導入するメリットは一通り理解していましたが、それによって解決されるようなクリティカルな課題を有していた訳ではありません。個人的に"守破離"を大事にしており、まずはセオリー通りにやってみることで、次に見えてくる世界があると思っているため、まずはやってみるという決断をしました。
運用開始までにやったこと
今までにやったことがない新しい取り組みであることや、現状抱えているクリティカルな課題を解決しに行くものではなかったため、できるだけコストを掛けすぎず、失敗しても損害が大きくなりすぎないことを目標としていました。
導入までに行ったことがこちらです。
・SLO管理ツールの選定 (Datadogを使用)
・エラーバジェットポリシーの作成
・全社向けのSLO説明記事作成
小さく始めるということで、まずはサービスの可用性のみを運用の対象としました。サービスの可用性であればDatadogに外形監視(Synthetic)とSLOの管理機能があるため、自分たちで何も用意せずとも運用体制の構築が可能です。SLIを「DatadogのSynthetic機能により行われる計測で、サービスのトップページがHTTP Status Code 200を返す時間」とし、SLOを99.95%と設定しました。99.95%の値は、AWSが公開している、Well-Architected for Startups -信頼性の柱- 導入編 の記事とLAPRASでの過去の可用性計測実績により決定しています。(いきなり非現実的な目標を立てても機能しません)
エラーバジェットポリシーに関しては、SLO違反をした時にいつまでプロダクションフリーズ(機能変更を含むリリース禁止)を継続するのか等のルールが定められており、プロダクトマネージャーと開発チームのマネージャー(ホラクラシー的にはCircle Lead)と相談しながら詳細を詰めていきました。ここの合意ができていないと、運用開始後にSLO違反が発生しても「とはいえ今機能開発止めるのは現実的ではないよね…」というような話になり、形だけのSLO運用になってしまう危険性があります。全員が納得できるようになるまで、SLOの値かエラーバジェットポリシーの変更が必要です。その際に大事な観点は"顧客の体験"です。このSLOを下回ったら許容できる顧客体験の範囲を下回るので、新規機能開発よりも既存機能の改善(バグ修正など)の方が重要だと合理的に考えられる値を探しに行きましょう。例えば、可用性が50%で半分の時間はアクセスできないサービスがあったとしたら誰でも新規機能開発するよりも可用性の改善をすべきだと思うはずです。ではどれだけの時間までだったらサービスが落ちていても許容できる?と聞いてみましょう。きっと妥当な値が返ってきて、自然と適切なSLOが決まるはずです。
全社向けには難しい資料は用意しておらず、社内ドキュメント共有ツールにSLOはなぜ必要なのかを簡単に説明したものを準備しただけです。他チームのメンバーでSLOという言葉を知らない人が言葉を耳にした時に参照するためのドキュメントとして用意しました。どのような指標も100%を目指すことは現実的ではなくとてつもないコストがかかるということ、エラーバジェットがあることで効果的にイノベーションと信頼性のバランスを取ることが可能になることなどを書きました。
半年運用した結果
1つのサービスの可用性の計測から運用が始まりましたが、半年後の今ではこれだけの指標に増えました。
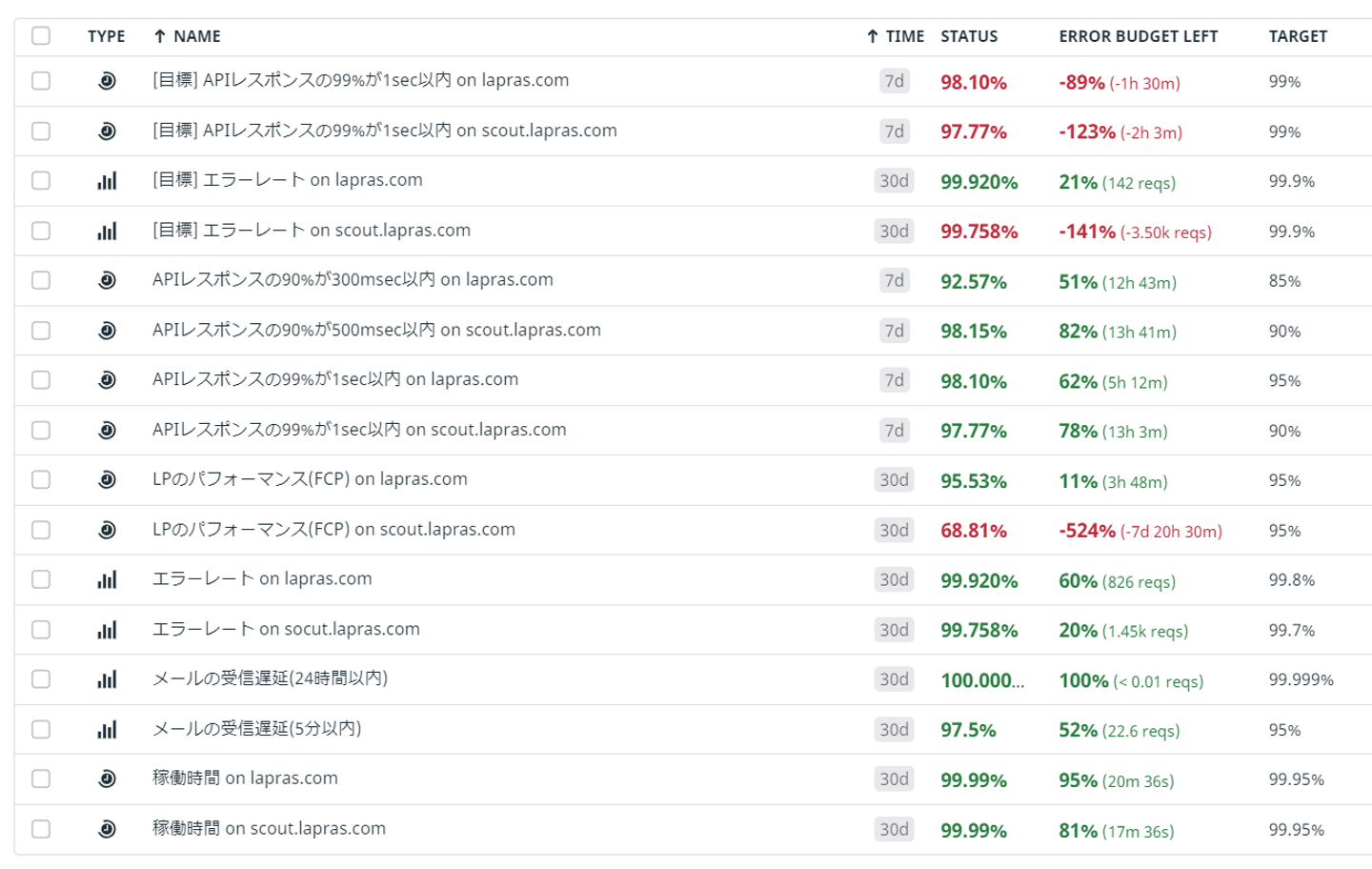
(具体的な数字公開して大丈夫?と思われる方もいらっしゃると思うので念の為に書いておきますが、LAPRAS 社では機密情報でない限り経験から得られた技術的なノウハウや現状を積極的にオープンにしています)
現在では有効なSLOが12個あり、運用の対象ではないが目標として設定しているSLOが4個あります。scout.lapras.com の LP のパフォーマンスがSLO違反しておりますが、SLIとして設定している計測方法が良くなく、人間がブラウザからアクセスすると期待するレスポンス速度で返ってきますが、SLIとしてはエラーを返してしまっています。この課題に関しては後述します。
Datadog だけだと時系列による変化が見にくいため、定期的にDatadogのAPIを叩いてその値をデータベースに保存し、Redashで時系列の変化を見ています。
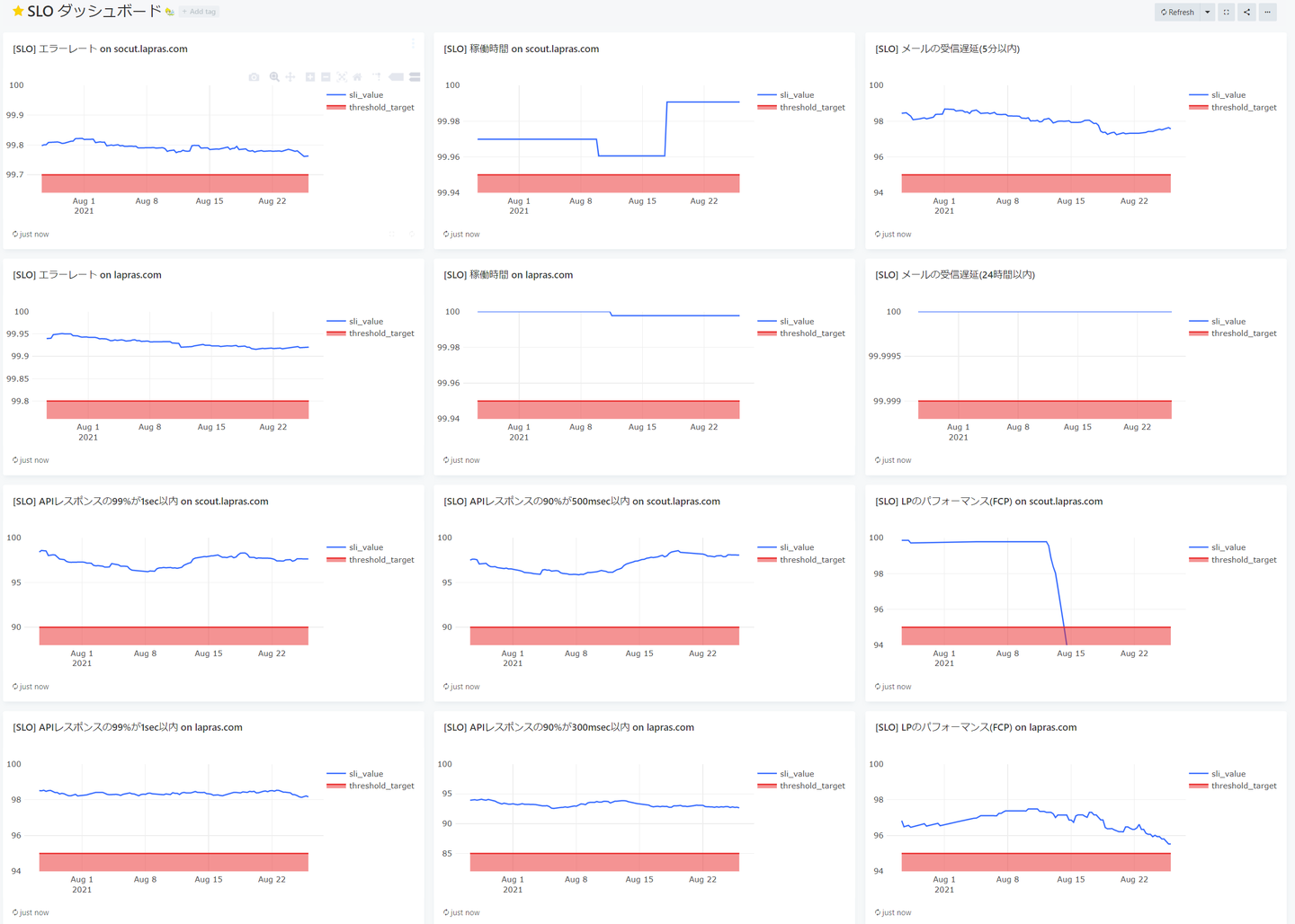
毎日朝会でSLOを確認していますが、エラーバジェットの残数よりもエラーバジェットの変化の方が気になるため、DatadogよりもRedashを見ることが多いです。(右中央のグラフを見ると、前述の問題により8月13日ぐらいからSLO違反していることがわかります)
計測対象を広げていく時には、まずはDatadogで取れる値から優先的に追加していきました。例えば、レスポンスタイムはAPMから、エラーレートはAWS ELBのメトリクスから取得しています。その次に外部からDatadogに対してデータを送信することで計測可能になる指標を追加しており、メールの受信遅延時間はアプリケーションからDatadogのAPIを叩いてデータを送っています。
また、この半年の間でSLOを更新したものもあります。アプリケーションのエラーレートは当初99.5%を設定していましたが、現在では各サービスで99.7%、99.8%と設定されています。運用開始当初は過去の実績的に99.6%程度であったため、いきなり99.8%を設定することは現実的ではなかったためです。運用開始後に積極的にバグ修正がされていった影響で値が改善し、常時99.5%を大きく上回る状態に変化したため、SLOもそれに合わせて上方修正しました。上のSLO一覧を見ると「[目標] エラーレート」というSLIがあり、SLOは99.9%と設定されています。将来的には99.9%をSLOとすることを目標としており、改善状況に応じて徐々にSLOをあげていく予定です。目標に合わせて徐々にSLOをあげていく方法は サイトリライアビリティワークブック にも書かれています。この本はSREの実践方法についてよく書かれているのでオススメです。
運用して気付いたこと
一番効果を感じたのはエラーバジェットの存在で、イノベーションと信頼性のバランスを取ることができるようになったと感じました。今までは3分サービスが落ちただけでも、原因究明をしてその問題を修正しにいく動きをしていましたが、SLOが明示されることで、原因究明をした結果それが偶発的に起きる事象でありこのまま放置してもエラーバジェットが十分に残ることが推測されれば、その解決を後回しにしてよりクリエイティブなことに時間を使う意思決定ができるようになりました。
似たような観点ですが、SLOという品質の拠り所になる指標ができたことで、それを満たしている状態であれば自分たちは十分な品質のサービスを提供できているという自信を持つこともできるようになりました。自社サービスの品質に不安を抱いている状態だと、エンジニアの精神的にも負担になり、またバグ修正と機能開発の時間の割り振り方も適切に判断ができません。SLOを導入してからは「エラーバジェットが減ってきたから〇〇のバグ修正のタスクの優先順位をあげよう」という意思決定ができるようになり、大きな武器を得たような感覚になります。
一方で課題として感じている点は、適切なSLIを設定することの難しさです。ユーザの体験を主眼においてSLIを設定すべきですが、計測基盤のことを考えるとそこから少しずれた指標を設定しなければならないことがあります。例えば、先ほど取り上げたSLO違反しているLPのレスポンスタイムのSLIについては、理想に近いSLIは「日本国内で一般的な家庭に敷かれているインターネット回線を利用して、よく使われているPCのスペックでブラウザからアクセスした時のFCP(First Contentful Paint)」でしょう。しかしLAPRASで設定しているSLIは「GitHub ActionでPuppeteerを起動して、LightHouse の機能より計測したFCP」です。その結果人間がブラウザから見る分には問題ないと感じる速度でレスポンスが返ってきているにも関わらず、SLIの計測方法ではエラーが返ってきてしまうという問題が起きてしまっています。
また、サービスのパフォーマンスに関するSLOでも似たような問題があります。LAPRASはSPAでサービスを提供していますが、パフォーマンスのSLIとして設定しているのは「DatadogのAPMで計測したAPIレスポンスタイムの99%タイルが 1sec 以内である時間」です。ユーザの視点で考えればAPI単位ではなく、ページ単位でFCPやLCP(Largest Contentful Paint)を見るのがベターでしょう。この場合、APIのレスポンスは十分に早いのに、一部の遅いAPIのレスポンスが画面の描画をブロックしていてユーザ体験を損ねている。というような事が起きないように気をつける必要があります。
その他の気付きとしては、SLOは増やしすぎると何が大事な指標なのかフォーカスがぶれてしまうので、10個前後ぐらいが適切そうだと感じています。それ以上増やすのであれば、SLOにPriorityをつけてPriorityに応じてエラーバジェットポリシーの厳しさも変更していくと良いのかなと思います。
結局SLOの導入はオススメ?
結論からいうとオススメです。冒頭でも書いたように、エンジニア10名程度の規模の組織ですが、そこまで運用のコストがかかっていない一方で、エラーバジェットの仕組みの恩恵を得られており、信頼性に対する自信も得られています。どこまでバグ修正の優先順位を上げればよいのか迷っている、機能リリースの度にバグが発見されていて最近ユーザの信頼を失っているような気がする、というような課題を持っている組織には特に向いていると思います。
一方で、専任のSREあるいはインフラエンジニアがいないようなアーリーステージなサービスであればこのような仕組みを整えるよりもガンガン機能開発をしてPDCAを回していくべきだと思っています。一定数以上のユーザがついて、彼らに継続的にサービスを利用してもらう事が重要になったフェーズでSLI, SLOを導入するのが良いタイミングではないでしょうか。
おわりに
SLAとは違い、SLOが内部的な指標であることもあり、公開されているSLO運用事例はあまり多くありません。個人的には他社の運用事例も見て勉強したいと思っているのですが、なかなか情報がないのでみなさんぜひ記事を書いてください!
LAPRASでは近々SREの採用ポジションを開ける予定ですので、興味を持って頂けた方はぜひそちらの方を楽しみにお待ち下さいませ。では。

/assets/images/1698386/original/821abe46-7e4c-4e35-bbcc-c4f459678505?1680567510)





/assets/images/1698386/original/821abe46-7e4c-4e35-bbcc-c4f459678505?1680567510)


