/assets/images/4569784/original/46f965d4-cc8c-4344-a2ce-9b004b3b9cb5?1580797425)


株式会社JDSC's job postings
- アプリケーションエンジニア
- 事業開発
- Consulting
- Other occupations (15)
- Development
- Business
- Other
★データ基盤エンジニアリングをこよなく愛する 4名で座談会を行いました★
目次
木村:
エンジニア部門長を務めています、木村です。JDSCに入る前は、大きめのweb系の会社やメーカーなどで10年ほどデータサイエンティストを名乗ってきており、その前はソフトウェア開発のエンジニアをやっておりました。これまで色んな会社でやってきた、データを活用したビジネスの立ち上げやデータサイエンスをするためのデータ基盤づくりの知見・経験のすべてを、現在の業務にいかしています。
秋本:
僕は木村さんと逆で、エンジニアからデータサイエンティストになった形ですね。2014年にゲーム会社でログデータ収集基盤の構築などに携わり、そこから分析基盤のキャリアがスタートしました。2017年にサービス会社に転職し、BigQueryを用いた分析基盤の構築・運用、機械学習基盤の構築に携わりました。データサイエンスをやってみたい想いがずっとあったので、2020年1月からデータサイエンティストとしてJDSCにジョインしています。
秋山:
私はSIer、Webアプリ開発会社でエンジニアとして働いた後、Webマーケティング会社でデータサイエンティスト兼データエンジニアとして活動していました。主にGCPを用いてKubernetesでデータパイプラインを使ったり分析基盤を作ったりしていた知見・経験を、今JDSCでいかしています。
石井:
私は他の皆さんのように開発がっつりというよりもプリセールスなどを中心にしてきたのですが、学生時代からコードを書くのが大好きだったこともあり、前職で少しデータに触れた機会をきっかけに、データエンジニアとしてJDSCに入社することにしました。
秋本:
まずはJDSCでのデータエンジニアとしての仕事の概要について、エンジニア部門長の木村さんからご紹介お願いします。
木村:
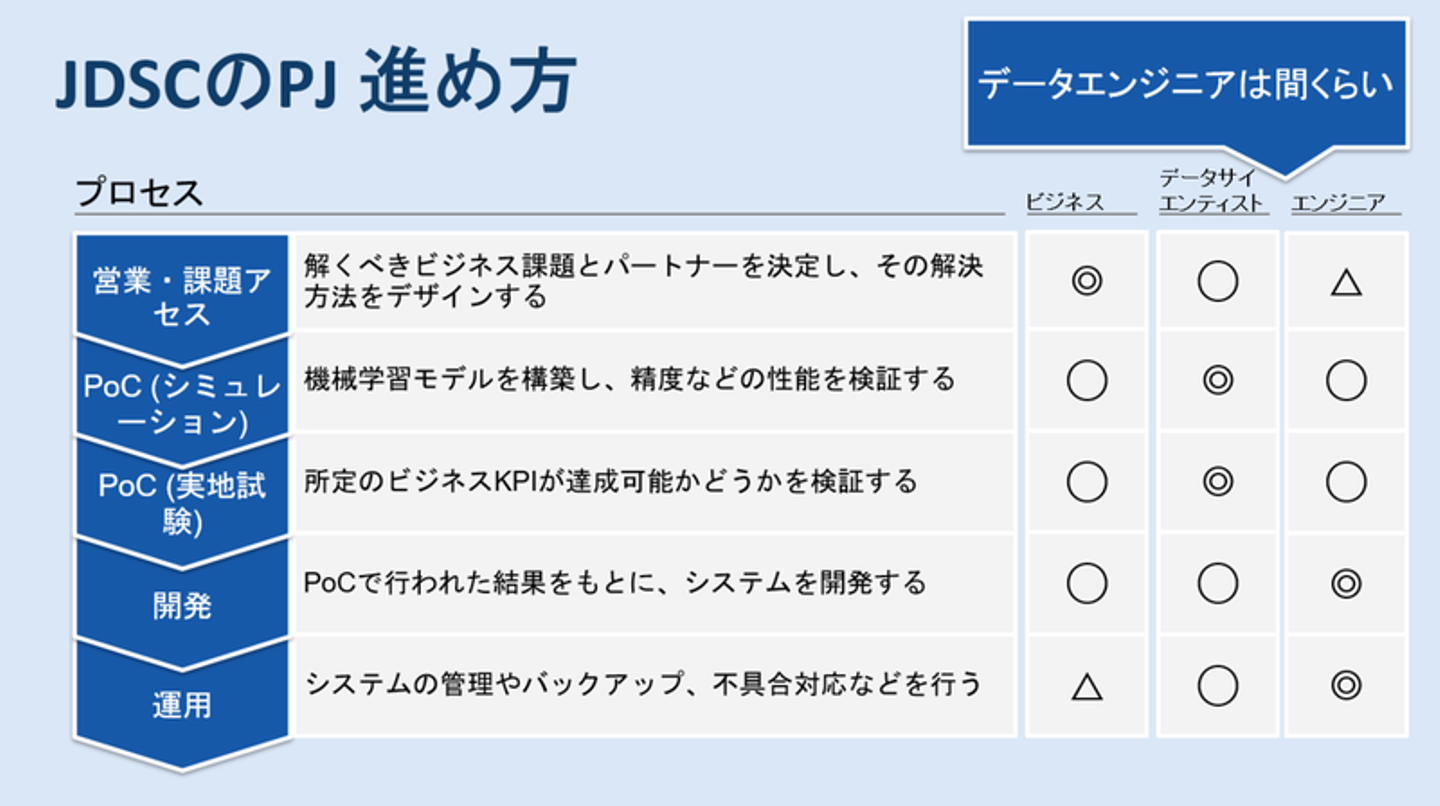
はい。JDSCは、いわゆる大企業のお客様からデータをいただいて機械学習モデルを作り、お客様の経営課題をちゃんと解決できるかをPoCというフェーズで確かめ、できると確認できたものについて業務適用いただいて、最終的にお客様の経営数値に対してインパクトを与えていくというプロジェクトを数多くやっている会社です。プロジェクトの進め方について標準の型があるので、ご紹介しますね。最初は営業・課題アセスメントとしてお客様の経営課題を把握し、その後PoCとして机上のシミュレーションと、我々が発見したアプローチがお客様の経営課題に対して効果があるのかを実地試験で検証していきます。そこでしっかり結果が出たものについて、業務適用するためのシステム開発・運用をやっていきます。
初期フェーズではビジネス部門のメンバーが大きく関与し、プロジェクトが進むにつれてエンジニアの関与が大きくなっていくのは一般的な流れですが、JDSCではどのプロセスにおいても各部門のメンバーが一定程度関わっていくという体制を「三位一体」と呼んで推奨しています。今日のテーマであるデータエンジニアは、データサイエンティストとエンジニアの間くらいのポジションです。バックグラウンドの異なる3職種が「三位一体」の体制で協力してプロジェクトを進めていくためには、それぞれの境界領域にあたる部分でともすればこぼれ球となってしまうようなものをしっかり拾っていくことが、データエンジニアには求められています。
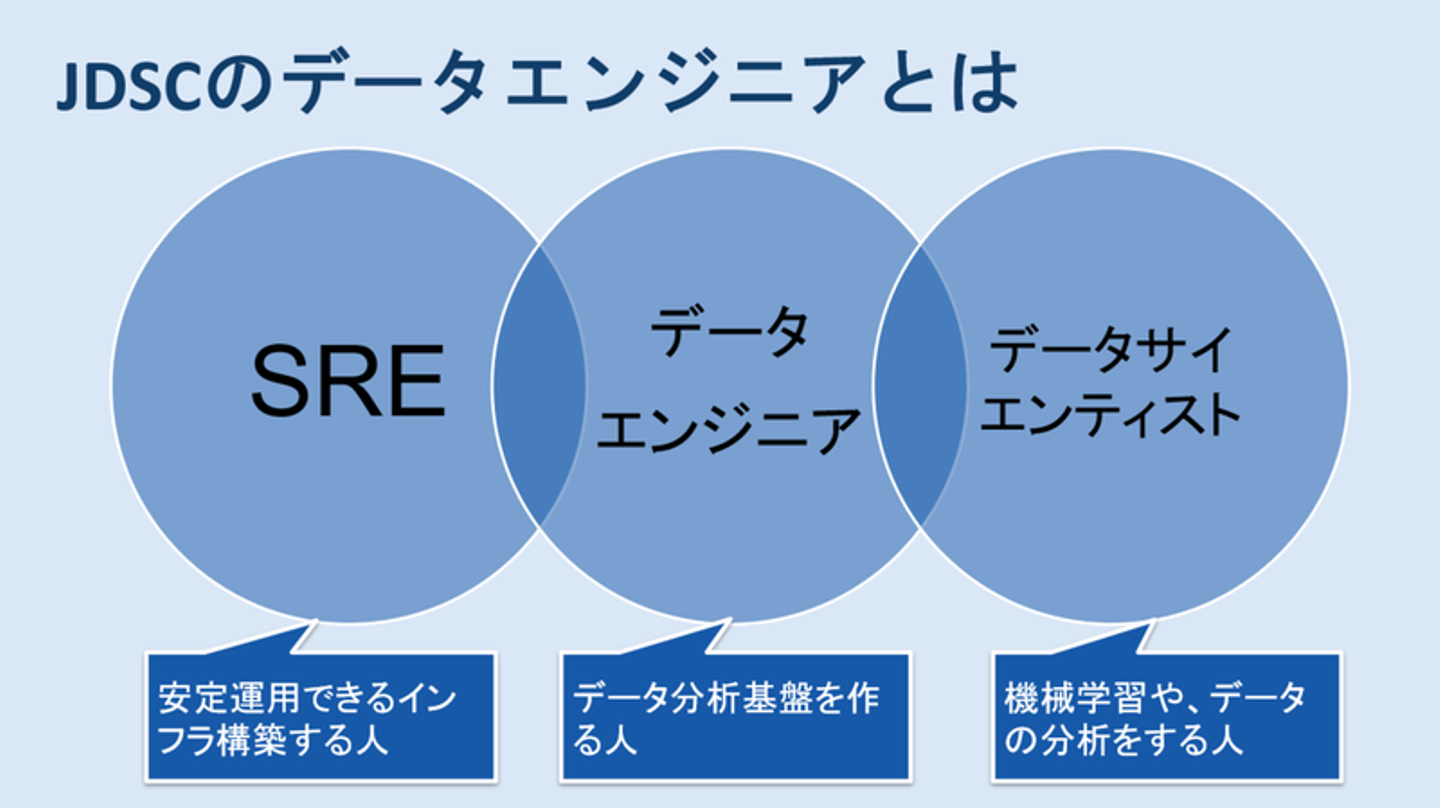
データエンジニアは、SREやインフラエンジニアのような職種と、機械学習やデータ分析をするデータサイエンティストのような職種のちょうど間くらいのポジションであるというお話をもう少し詳しくしますね。データサイエンティストはエンジニアリングに強い人やコンサルティングに強い人がいますが、エンジニアリングに強い人であれば、お客様からいただいたデータを自分でクラウドにあげて分析して機械学習モデルを作ったりします。それを実際にお客様の業務に適用する段階になると、その機械学習モデルの生成やデータ連携から変換処理もきちんと運用可能な方法で作っていく必要があります。一般的なアプリケーション開発ではデータ処理関連技術に特化したSREが担うような領域ですが、ここになぜデータエンジニアが必要になるかというと、データの中身もある程度把握しつつ、それをきちんと運用可能なシステムに落とし込む力が求められるからですね。ここがJDSCの強みとして打ち出しているところです。
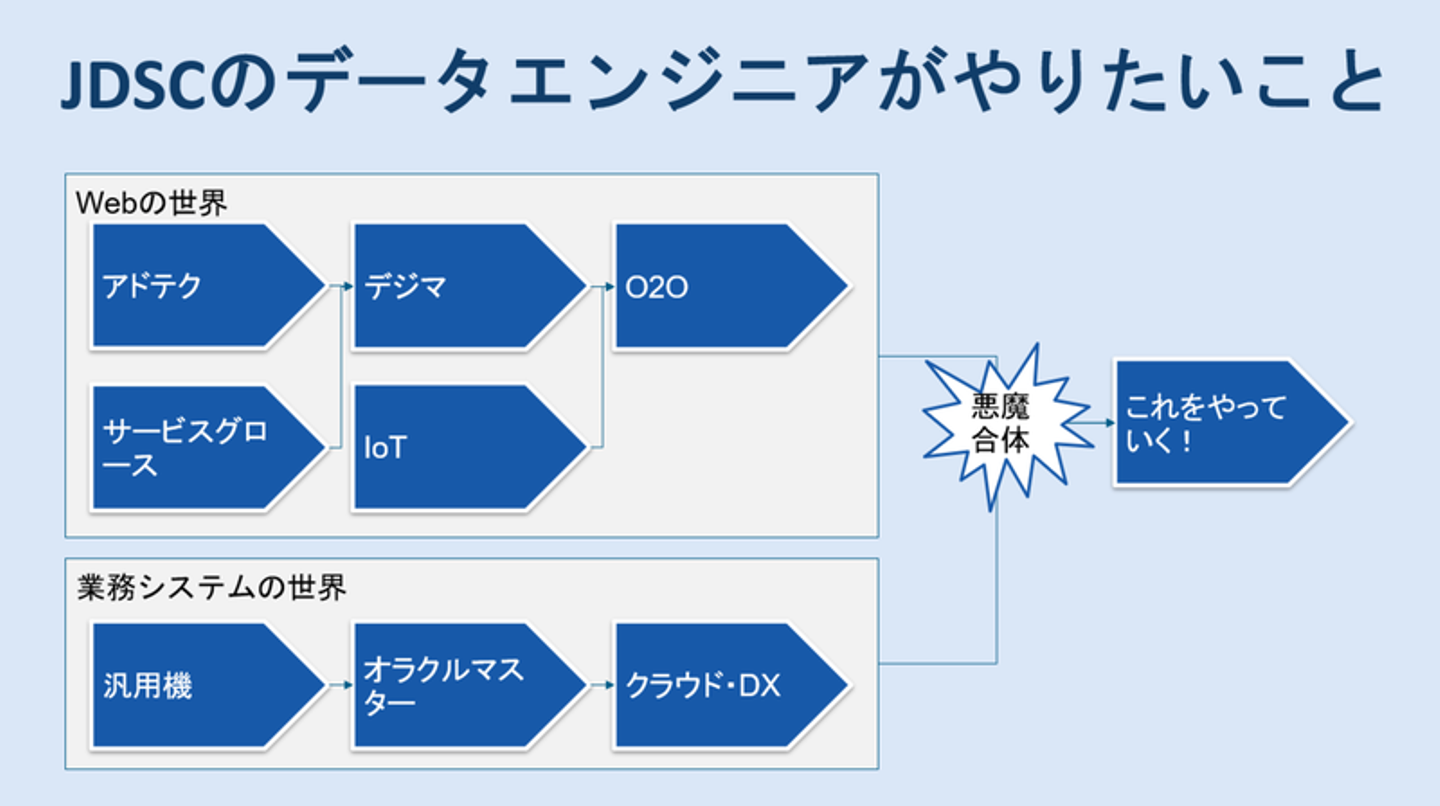
私の10年くらいの経験でお話すると、Webの世界ではだいたいアドテクやサービスグロースの文脈から始まり、デジタルマーケティングやIoTの要素が出てきて、O2Oをやったりしながらだんだんデータマネタイジングしていくというのが一般的な流れだったんですよね。ただ言葉を選ばずに言うと、これは結構「虚業」と言いますか、実際にお金にする部分がかなり難しいんですよね。一方で業務システムの世界も、1980年代の汎用機の時代から2000年代のオープン化を経て、近年のクラウド・DXの流れになっていますよね。ここには30年分のビジネスのデータが溜まっているので、そこにWebの世界の技術を悪魔合体させることで、今までなしえなかったような新しい価値を作っていくのが我々のやりたいことなんです。
秋本:
ではそのような仕事の中で使っている具体的な技術スタックについて、お話していきましょうか。秋山さん、今アツいと感じている技術って何かありますか?
秋山:
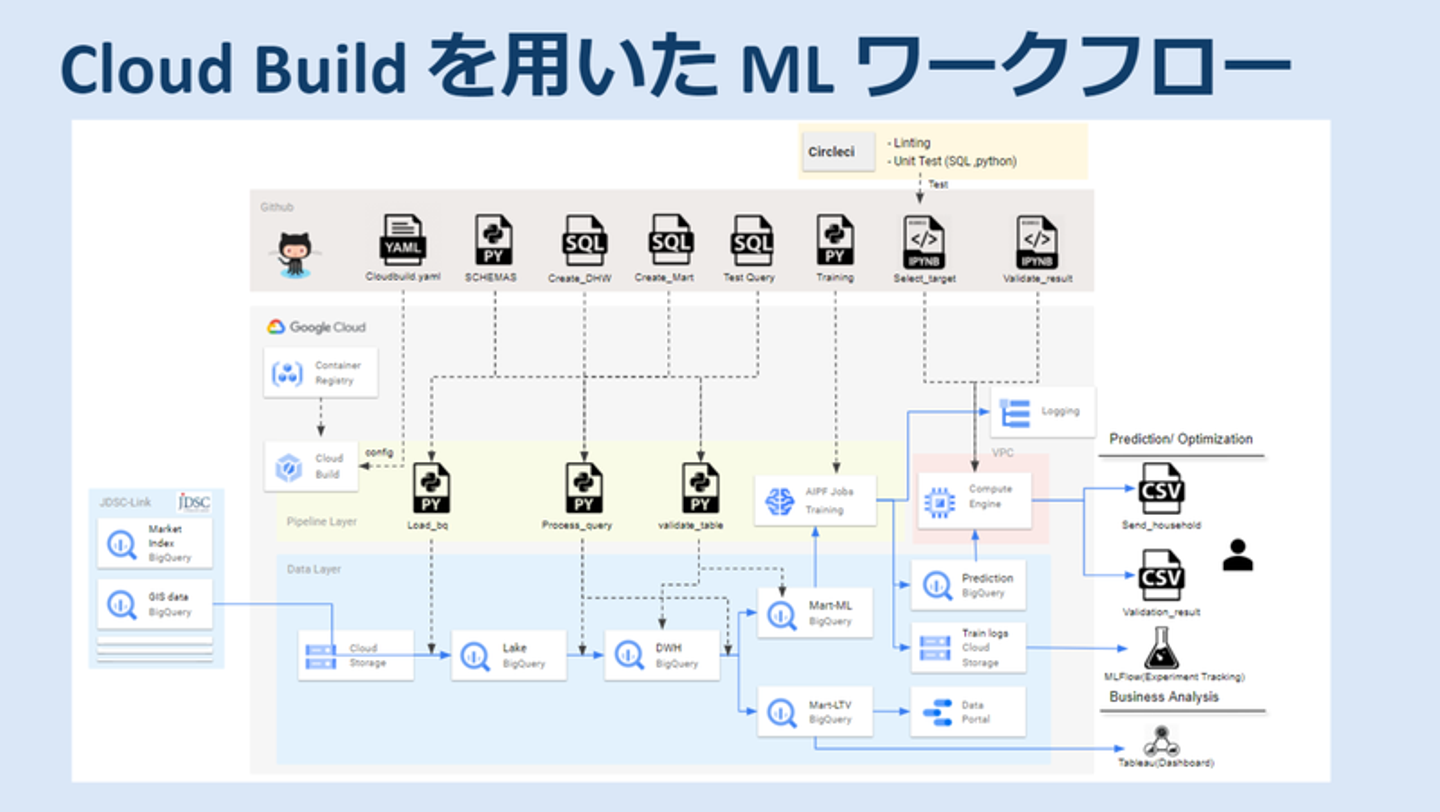
今私は石井さんと同じチームでデータパイプラインを作っていて、そこではワークフローエンジンを乗せたCloud Composerを使っています。このCloud ComposerはDAGが固定された状態で運用するには良いのですが、Cloud Composer上はUTCのタイムゾーンで固定されているのでJSTで動かすことができないなど、マネージドサービスならではの制限があり、開発には向かないんですよね。そこでCloud ComposerはただのUIとして使って、実際のバックエンジンはBigQueryをもとにSQLでパイプラインを処理していくやり方をしています。そうするとCloud Composer自体のメリットはだんだん薄れていくので、JDSCが開発しているalpha SQLに完全移行する方法を考えているところです。
秋本:
Cloud ComposerにSQL間の依存関係はなく、純粋なワークフローツールですよね。DataformであればSQLのまとまりから依存関係が抽出できてDAGができるんですよね?
秋山:
はい。Dataformの良いところは、例えばテーブルのメタ情報をSQLXという新しいフォーマットで書くことができて、さらにユニットテストも作ることができるというところで、かなり画期的なんですよね。
秋本:
SQLを登録するとカタログになるのが良いですよね。メタデータ管理が今後大切になってくると思うので、GCPをメインに使っているJDSCでは、将来的にGCPのData Catalogなども連携できると良いなと思います。Cloud Composer自体にコストがかかるという辛さについても、大きい会社だと許容される場合もあるかもしれませんが、JDSCだとプロジェクト単位でコスト管理する形になるので、いかに安価なパイプラインを組めるかというのが大事なポイントになってきますよね。
石井:
そうですね。お客様からいただくデータの規模にもよりますが、ストレージに入ってきたデータに問題がないかなど、データのバリデーションまでちゃんと見ながら設定する場合は、パイプラインの構築にそれなりの時間がかかります。あと私がアツいテーマと感じているところで言うと、BigQueryを使っているとデータのバージョニングができなかったりするので、最近はそこに苦心してますね。
秋本:
僕もデータサイエンティストとして共感します。「こういう通知が出ました」とお客様にお見せするときに、データのバージョンとGithubのコードのバージョンを必ずパラメーターで管理しないといけないですが、特にデータのバージョン管理をどのようにするかは大きな課題ですよね。
石井:
そうなんです。最近少しずつそのあたりの技術も出てきているものの、BigQueryでも7日分程度のデータしか遡れなかったりとまだ制限は色々あるので、考えないといけないことは多いですよね。
木村:
私は10年くらいデータサイエンティストをやってきたとお話しましたが、データサイエンスの黎明期って、そもそもデータを扱うための基盤を作るところから始まっていったんですよね。当時はオンプレがメインだったので自社のデータ基盤を作っていたのですが、データ基盤って一度作ると”御守り”のフェーズに入ってしまって、技術革新についていくのが難しいという側面がありました。新しい技術にふれるために転職をすると、またその会社のデータ基盤を作り、また同じことが起こって転職するということになるんですよね。それに対してJDSCは、色んなお客様からデータをいただいてそれを活用していくというビジネスをしている会社なので、一社にいながら色んな会社のデータ基盤を作ることができるんです。これは自分自身のキャリア設計の上でも非常に魅力的に感じていますね。
秋本:
すごくよく分かります。一般的な会社では基盤が安定してくると運用ばかりになって、新しいことがしづらくなるんですよね。
木村:
そうなんです。あとは、Webの世界でデータサイエンスをしていると、結局オチがデジタルマーケティングやアドテクになるんですが、このあたりはあまり儲からないし、そればかりだと飽きてくるんですよね。その点JDSCでは、これまでWebでは全然想像していなかったような色んな業界に特化した流通の仕組みや、電力データのようなインフラデータのように、ビジネス規模が大きくあまりプレーヤーがいない領域でデータサイエンスをやっていけるので、データエンジニアとしてもすごく楽しめるところなんじゃないかなと思います。
秋本:
JDSCに応募してきてくださる方からも「エンジニアとしてどういうソリューションを提供すれば良いかという観点で、色んなビジネスに関わりたい」という志望動機をよくいただきますね。
石井:
そうですね。あと私は、処理技術・基盤技術を色々試すことができることもやりがいに感じています。例えばクラウドも色んな種類がある中、会社によって使えるものが決まっていたりしますよね。その点JDSCは、GCPメインと言いつつプロジェクトによってはAWSを使っていたりするので、色々試すことができます。加えて既存のクラウドサービスを使うだけでなく、先ほど秋山さんからお話があったように、自社で開発・標準化していくことができるのも結構面白いなと思っていますね。AWS部という部活動もあって、業務外のところで皆で色々試すこともできるんですよ。
秋山:
AWS部、この間発足してましたよね(笑)。個人的には、もともとデータサイエンスをやりたいと思ってJDSCに入社したのですが、データエンジニアとしてのスキルを研鑽していくにつれて考えが変わってきました。データサイエンティストの仕事も素敵ですが、毎日モデルに向き合っていかないといけない、という大変さがありますよね。私自身は怠け癖があって、「いかに楽してAIを開発していくか」というところで、いくらでも頑張れるタイプなんです。JDSCでは、他の会社よりもデータエンジニアとして良い意味で”怠け癖”を求められていると感じるので、自分に合っているなと思っています。まだまだ未整備の状態が多いので、自分の裁量をもって整備された状態にしていくことに、かなりわくわくして取り組んでいますね。シニアエンジニアのメンバーも多いので、それについて壁打ちに付き合ってもらったりしながら効率的な手法を学んでいけるという環境も楽しいです。
秋本:
整備されていないということは、色んな技術を試せるチャンスでもありますよね。社内の優秀なエンジニアと一緒に組み立てていくプロセスは、0から1を作っていくことが好きな人にはすごく良いなと思っています。”怠け癖”というお話についても、僕もなるべく楽してコードを書きたいと思うので、秋山さんの気持ちは共感できますね。あと僕自身については、プロジェクトによってデータエンジニアとして参画したりデータサイエンティストとして参画したりしているのですが、それもやりがいに感じています。データエンジニアとして皆さんが使いやすい綺麗なデータ基盤を作りたいという想いも達成できるし、データサイエンティストとしてより良いモデルを作ってお客様のためにインパクトを出したいという想いも叶えられるので、自分のキャリア設計の観点からもすごく良いなと思っていますね。
木村:
JDSCは、今は個社のお客様からデータをいただいて価値提供するということをしていますが、社名の”C”はもともと”コンソーシアム”の”C”なんですよね。つまり、本当にやりたかったことはお客様の壁を越えてデータを価値化することなんです。例えば特定の三社くらいに寡占されている商品があったとして、それに関わる情報を”コンソーシアム”の座組で持ってビジネスを組み立てていくことで、その産業自体の生産性があがり、ゼロサムゲームではない形となり、三社全ての利益があがる、ということです。このように、すべての企業のより多くのデータを価値化して、さらにその機械学習モデルを他にも展開して価値化することができますよね。あわせて業界をリードするデータ基盤技術を開発していきたいということも考えています。データサイエンスだけでなく「データ基盤開発といえばJDSC」と言ってもらえる状態を目指していきたいです。
★皆さん本日はありがとうございました!JDSCはこれからもデータエンジニアの方はじめ、たくさんの方のご入社をお待ちしております★
/assets/images/4569784/original/46f965d4-cc8c-4344-a2ce-9b004b3b9cb5?1580797425)


/assets/images/4569784/original/46f965d4-cc8c-4344-a2ce-9b004b3b9cb5?1580797425)

![]()

/assets/images/4569784/original/46f965d4-cc8c-4344-a2ce-9b004b3b9cb5?1580797425)