
今日は、日本語の会話音声認識(ASR)を「テストタイムコンピュート」で改善できるかを試した内容についての報告です。
テストタイムコンピュート(的なアイデア)を活用しての精度向上は、コードネーム: オポッサムとして検証していたものです
背景
OpenAIのWhisperは高精度なASRモデルですが、日本語の雑談や固有名詞、表記ゆれなどでは、ちょこちょこと誤りが残ります。
学習データを追加して再学習(ファインチューニング)するのはコストもリスクも高いので、もっと手軽に精度を上げたい──そこで使ったのが Test-Time Compute(TTC) という発想です。
TTCとは、モデルを再学習せずに「推論時に計算を上乗せして精度を上げる」方法です。今回は、このTTCをWhisperの出力に対してLLMで後段補正する形で試しました。
ところで、テストタイムコンピュートという名称について一言。
研究者視点だと、pretrainingとfine-tuningがあり、最後に性能をテストするところがtestなので、学習を伴わない最後の最後の工夫で精度を上げるテクニックという意味でtest-tme-compute という名前になっています。
ソフトウェアエンジニアの視点では、既にあるモデルを活用してプロダクション環境で性能向上を狙える技術なので、テストという名称はあんまり(実際、inference-time-computeと呼ばれることもあります)だと思いますが、それをそれで…
アプローチ
試したアプローチは2つです。
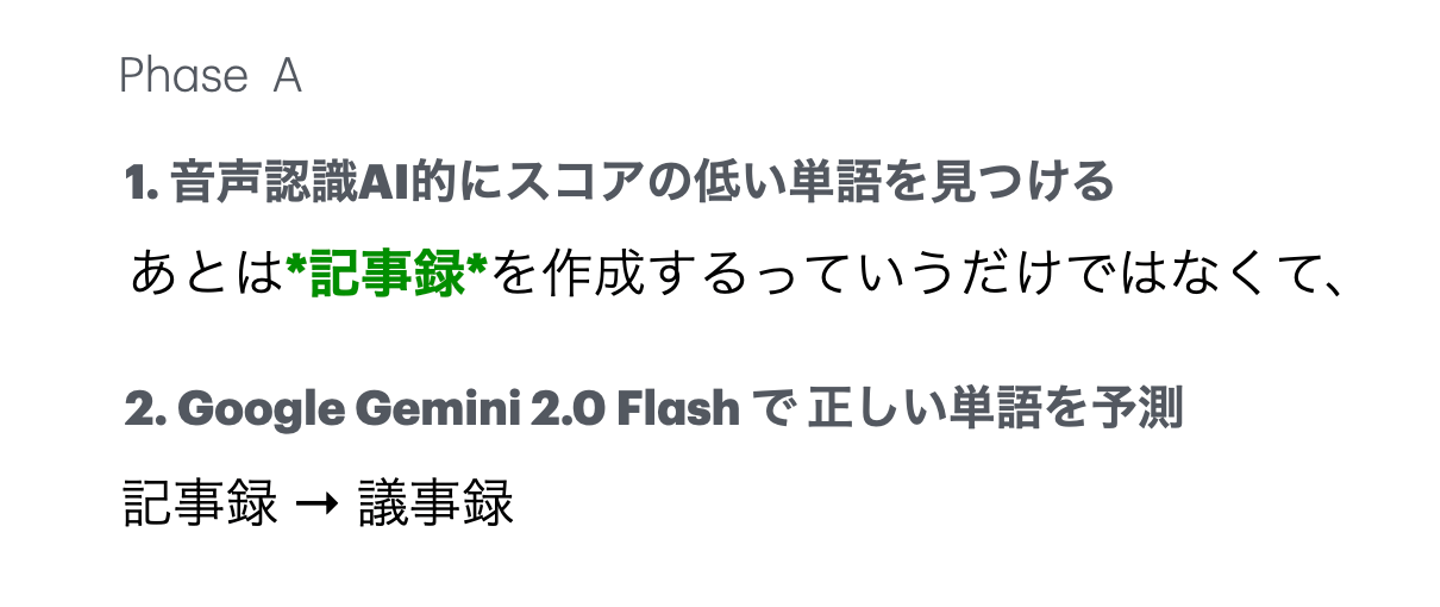
局所修正(Phase A)
Whisperの信頼度スコアが低い単語だけを、Gemini 2.0 Flashで最小限修正。
例:固有名詞や聞き取りづらい単語をピンポイントで直す。
全文ベース修正(Phase B)
全文を要約+原文セットでOpenAI o3系モデルに渡し、文脈全体を見て誤り候補を抽出&置換。
例:低信頼扱いされなかったけど、文脈的におかしい語を修正。
両方とも「指定された部分以外は変えない」「最小限の変更だけ」というルールを厳守しました。過修正(余計な言い換え)を防ぐための安全装置もいくつも入れています。
実験
対象は13分〜57分の日本語会話音声4本(合計約127分)。
結果は以下の通りです。
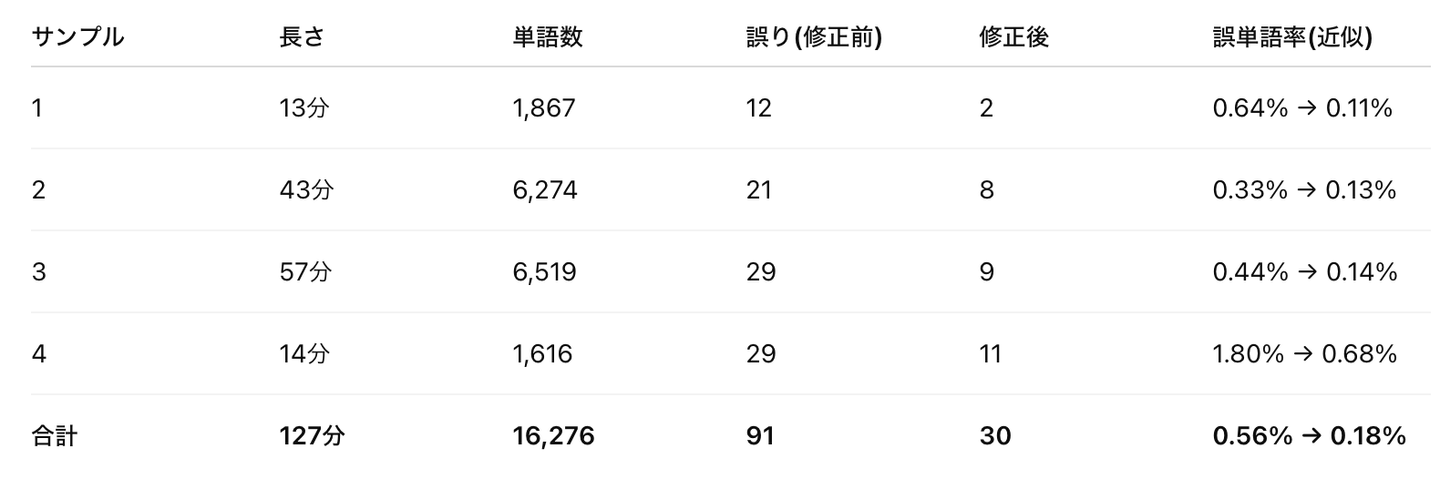
全体では誤単語率が 0.56% → 0.18%(相対67%減) に。
ベースがかなり高精度でも、まだ残っていた誤りをしっかり拾えました。
気づき(普通)
低信頼語ピンポイント修正は寄与が限定的(ただし固有名詞には強い)。
全文ベース修正は拾い残しをかなり減らせる。
過修正を防ぐルール設計は必須。
数分〜1時間級の会話音声でも、現実的な処理コストで導入可能。
気づき(ぶっちゃけ)
音声認識のスコアが低い単語を検出し、直前のテキストと合わせて修正案をださせる方法は効果が薄い。これはGemini 2.0 flashがダメなのかも
一方で、議事録と全文を見せ、全体を通して認識ミスを思われる単語と修正案のリストを一発で出させる方法は効果が高かったです。これはOpenAI o3の性能によるものと思われますね。
まとめ
学習なし・推論時だけの追加計算で、Whisperの日本語認識精度を実用的に改善できました。
特に、固有名詞や表記ゆれの多い会話では効果的です。
AI関連は100%AIが正しいことを言えるわけではないということもあり、 human AI interactionが重要なので、人が気持ちよく使えるUI/UXを模索したいと思います。
ところで、もっと大量のデータに対してきちんとアノテーションを行い、検証をちゃんとやれば論文としてもいけるかなと思うのですが、なかなかそこまでの時間はとれず、論文と呼べるほどのものではないかもですが、所感レポートを作成したので、zenodoにアップロードしてみました。
https://zenodo.org/records/16881446

/assets/images/4253484/original/bc157435-6796-4d99-8745-f0e0679ce08f?1573106296)
/assets/images/4253484/original/bc157435-6796-4d99-8745-f0e0679ce08f?1573106296)


