目次 1. はじめに:なぜ B+木を学び直したのか
2. B+木が解く問題
2.1 ディスク I/O というボトルネック
2.2 二分探索木では足りない理由
3. B+木の定義と構造
3.1 葉ノードの性質
3.2 内部ノードの性質
3.3 平衡性
4. 検索アルゴリズム
4.1 単一キー検索
4.2 範囲検索
4.3 計算量
5. 挿入アルゴリズム
5.1 葉ノードへの挿入
5.2 ノードの分割
5.3 親への伝播
5.4 ルートの分割と木の成長
5.5 具体例
6. 削除アルゴリズム
6.1 葉ノードからの削除
6.2 再分配
6.3 併合
6.4 親への伝播
6.5 根ノードの縮約
6.6 具体例
7. 勉強会でのディスカッション
8. まとめ
9. おわりに
1. はじめに:なぜ B+木を学び直したのか Unyte でエンジニアをしている平野です。社内データを AI でどう活用するかに取り組んでいます。Unyteでは、毎週技術勉強会を開催しており、今回はグラフ理論とB+木がテーマでした。本記事はそのうちB+木に絞ってまとめたものです。
勉強会にこのテーマを選択した理由としては、まずグラフというコンピュータ分野でよく出てくるデータ構造についてイメージしやすくなってもらうことで、自社プロダクトにグラフDBを使用すべきかどうか等の技術選定がしやすくなり、またB+木について詳しく理解することでパフォーマンスチューニングに役立つのではないかと考えたためです。
リレーショナルデータベースを日常的に使うエンジニアであれば、 CREATE INDEX を書いた経験は誰しもあるはずです。しかしそのインデックスの内部で何が起きているかは、意外とわかっていない人が多いと思います。多くの主要なデータベース(MySQL、PostgreSQL、SQLite、Oracle など)がインデックスの実装に B+木を採用しているので、ここを押さえると、適切なインデックス設計・クエリチューニング・パフォーマンス問題の根本原因分析に直結します。
実際、僕も最近、自社で開発している RAG で、ある重要なクエリのレスポンスが想定より遅いという問題に当たりました。最終的には GIN という B+木とは別系統のインデックスを使って解決したのですが、振り返ってみると、B+木 の仕組みをちゃんと押さえていれば、「 B+木 でも対応できるのか、それとも GIN のような別系統が要るのか 」を最初から比較して選べたな、と感じています。
AI に実装を聞けば一瞬で答えが出てくる時代ですが、複数の選択肢を比較して根拠を持って選ぶ判断の部分は、結局自分の中にデータ構造のイメージがないと回らない。現状では、AIが毎回完璧な実装を行うとは限りません。それが原因でレビューの負荷が高くなっているとよく言われています。そのような時代だからこそ、こういう基礎の判断が大事だな、と改めて実感しました。
本記事では、B+木の定義から始め、検索・挿入・削除の各アルゴリズムを図解とともに解説します。前提知識としては、二分探索木と計算量(O 記法)の基本を理解していれば十分です。
2. B+木が解く問題 2.1 ディスク I/O というボトルネック データベースが扱うデータはメモリに収まらないことが多く、ディスク(あるいは SSD)といった二次記憶装置に格納されます。ディスクアクセスはメモリアクセスに比べて桁違いに遅いため、データ構造の評価軸は「比較回数」ではなく「I/O 回数」になります。
ディスクは通常、ページと呼ばれる単位で読み書きされます。したがって、目的のデータに到達するまでに何ページ読む必要があるか、が支配的なコストになります。
2.2 二分探索木では足りない理由 データベースのインデックスは、データベースの内容に更新が生じるとそれに伴い動的に更新しなければなりません。インデックスのデータ構造に二分探索木を使用すると、例えば新しいデータを追加するときに、現在の葉ノードから下向きに新たなノードを追加することになります。しかし、このような方法で更新に対処していると木構造のバランスが悪くなり、探索キーによってページアクセスにばらつきが出てしまいます。この問題を解決するためにB+木が考案されました。
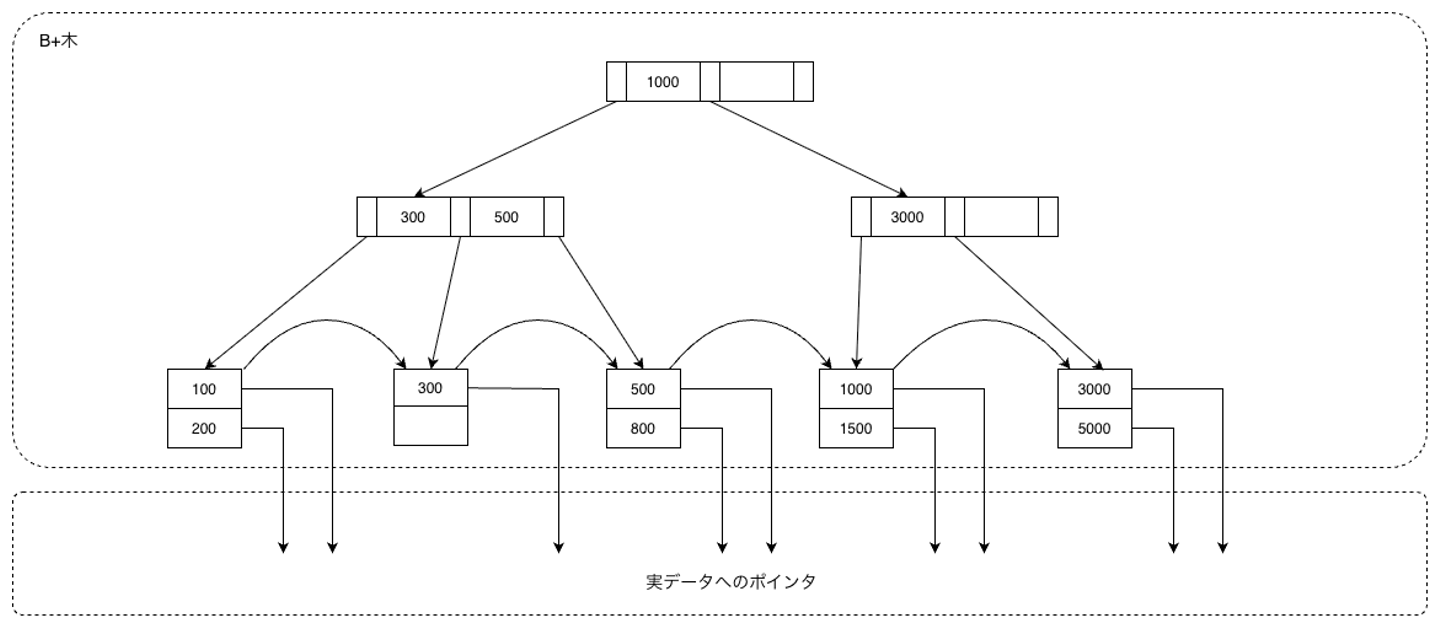
3. B+木の定義と構造 B+木は、データを実際に保持する 葉ノード と、葉への経路を提供する 内部ノード (中間ノードとも呼ぶ)からなる多分木です。また、木の頂点を 根ノード と呼びます。
1 ノードに格納できるキーの最大数を 次数 n と呼びます。次数はディスクのページサイズとキーサイズから決まる定数で、実用的には数百のオーダーになります。
3.1 葉ノードの性質 葉ノードはインデックスの実体を担い、次の性質を持ちます。
各エントリは インデックスキー と、対応するレコードを指す ポインタ (タプル ID やページ ID など)の組である エントリはキーの昇順にソートされて格納される 隣接する葉ノード同士は連結リストでつながれており、範囲検索を効率化する 各葉ノードは、容量の半分以上が常に埋まっている(最低充填率の保証) 3.2 内部ノードの性質 内部ノードは、目的の葉ノードへルーティングする役割を持ちます。
各ノードは、キーと子ポインタを交互に格納する。 k 個のキーを持つ内部ノードは k +1 個の子ポインタを持つ キー Ki は境界として働き、 i 番目の子ポインタの先にある部分木には Ki 未満のキーのみ、( i +1) 番目の子ポインタの先にある部分木には Ki 以上のキーのみが含まれる ルート以外の内部ノードは、葉ノードと同様に容量の半分以上が埋まっている 根ノードのみ例外で、最低 1 個のキーがあれば成立する 3.3 平衡性 B+木の最も重要な性質は、 ルートからすべての葉までの距離(高さ)が等しい ことです。
この不変条件のおかげで、任意のキーへの検索コストが木の高さ h で抑えられ、 h = O (log n N ) となります( N は格納エントリ数、 n は次数)。後述する挿入・削除アルゴリズムは、いずれもこの不変条件を維持するように設計されています。
4. 検索アルゴリズム 4.1 単一キー検索 ルートから始めて、各内部ノードでキーを比較し、適切な子ポインタをたどります。葉ノードに到達したら、目的のキーを二分探索で探します。
木の高さを h とすると、ページ読み込みは h 回程度で済みます。実用的な次数(数百)では、数十億件のデータでも h は 3〜4 程度に収まります。
4.2 範囲検索 範囲検索は次の手順で行います。
範囲の下限キーを通常の検索で見つけ、対応する葉ノードに到達する その位置から葉ノードを兄弟ポインタでたどりながら、上限キーを超えるまでデータを返す 内部ノードを再訪する必要がない点が、B木に対する B+木の明確な優位点です。
4.3 計算量 検索: O (log n N ) 範囲検索: O (log n N + k )、ここで k は返されるレコード数 5. 挿入アルゴリズム B+木における挿入に対処する考え方を直感的に説明すると、木を下に成長させるのではなく、木構造自体を変更し、必要に応じて木を上に成長させるということになります。
5.1 葉ノードへの挿入 検索と同じ手順で、挿入先の葉ノードを特定します。葉ノードに空きがあればキーをソート順に挿入して終了です。
5.2 ノードの分割 葉ノードのキー数が上限を超えた場合、ノード分割 を行います。
挿入するキーと、その葉ノードにすでに存在するキーを合わせた全キーを 小さい前半分と大きい後半分の2 つに分ける 新しい葉ノードを作成し、後半のキーを移す 兄弟ポインタを張り直す 新しい葉ノードの最小キーを、親のノードに昇格させる 5.3 親への伝播 昇格したキーを受け取った親ノードも、結果としてキー数が上限を超える可能性があります。その場合、親ノードも同じ要領で分割し、さらに上の親へキーを昇格させます。
これは再帰的に、必要に応じてルートまで伝播します。
5.4 ルートの分割と木の成長 根ノードが分割された場合、新しいルートが作られ、元のルートと分割で生まれた新ノードがその子になります。B+木が高さを増やすのは、このタイミングだけです。
すべての葉が同じ深さに保たれるという不変条件は、この「ルートからしか伸びない」性質によって自然に維持されます。
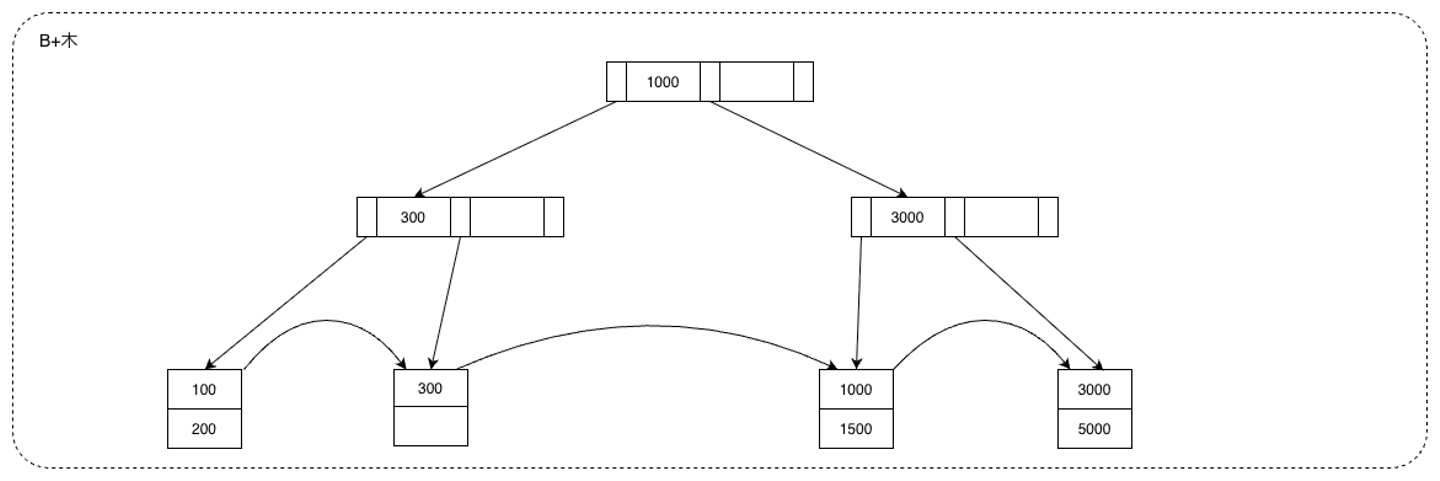
5.5 具体例 図1のB+木に、索引キーが700のデータを挿入する例を考えます。
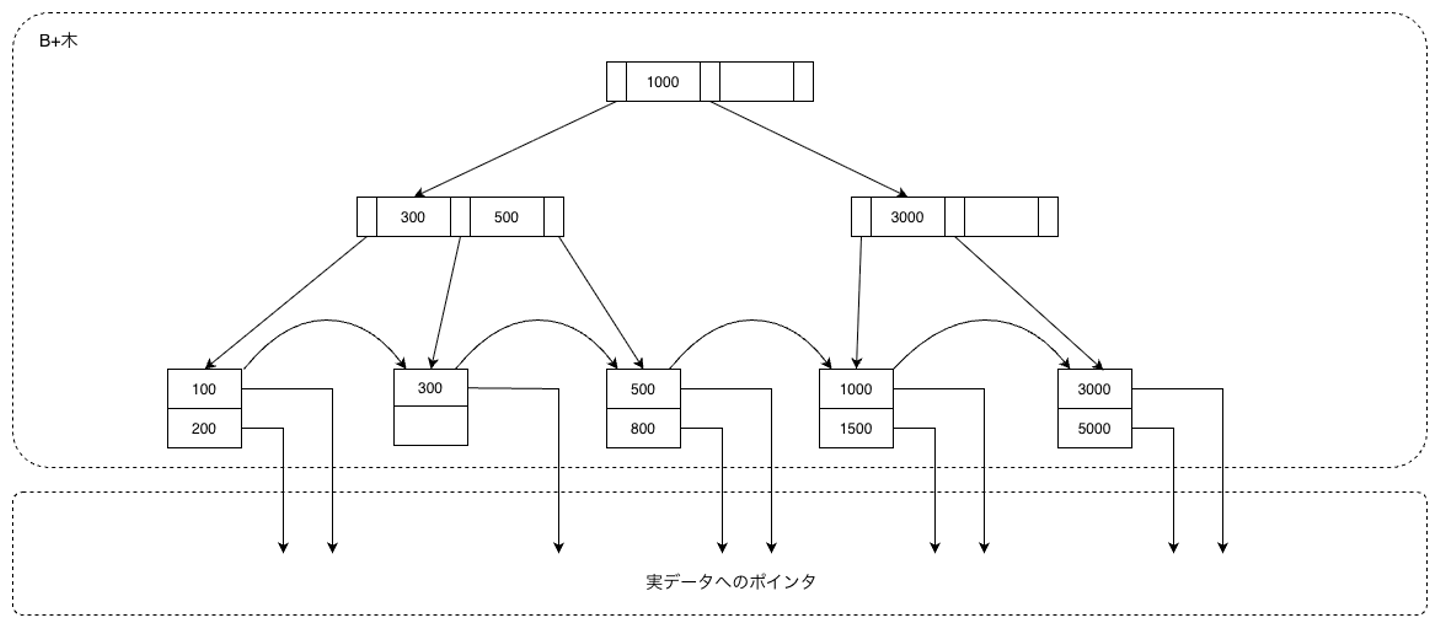
まず、挿入すべき葉ノードは左から3つめの葉ノードであることが分かります。葉ノードに空きがないので、ステップ2に進みます。 500, 700が前半のキーなので、500, 700は既存の葉ノードにそのまま格納します。後半分である800を格納するための新たな葉ノードを作成します。そして新しい葉ノードの最小キーである800を親のノードに昇格させます。 親のノードにも空きが無いので同様に分割を行います。最終的に図2のようになります。 6. 削除アルゴリズム 削除は挿入の逆で、「葉から削除 → 必要なら再分配・併合を上に伝播」という流れです。挿入より場合分けが多く、実装上のバグが生まれやすい部分でもあります。
6.1 葉ノードからの削除 検索で対象の葉ノードを特定し、キーを削除します。削除後も対象の葉ノードの収容スペースの半分以上が使われていればそれで終了です。
6.2 再分配 削除後にキー数が下限を下回った場合、まず 再分配 を試みます。
隣接する左の兄弟ノード(左に兄弟ノードがなければ右の兄弟ノード)に余裕があれば、そこから 1 つキーを借りてきます。借りたキーを反映するため、親ノードのキーも更新します。
6.3 併合 兄弟ノードにも余裕がない場合、ノード併合 を行います。
自ノードと兄弟ノードを 1 つにまとめる 兄弟ポインタを張り直す 親ノードから、両者を分けていたキーを削除する 6.4 親への伝播 親ノードからキーが削除された結果、親もまた下限を割る可能性があります。その場合は親に対しても同じく再分配または併合を行い、必要に応じて根ノードまで伝播させます。
6.5 根ノードの縮約 伝播の結果根ノードに到達し、根ノードの探索キーが0個の場合は、根ノードを削除して終了します。
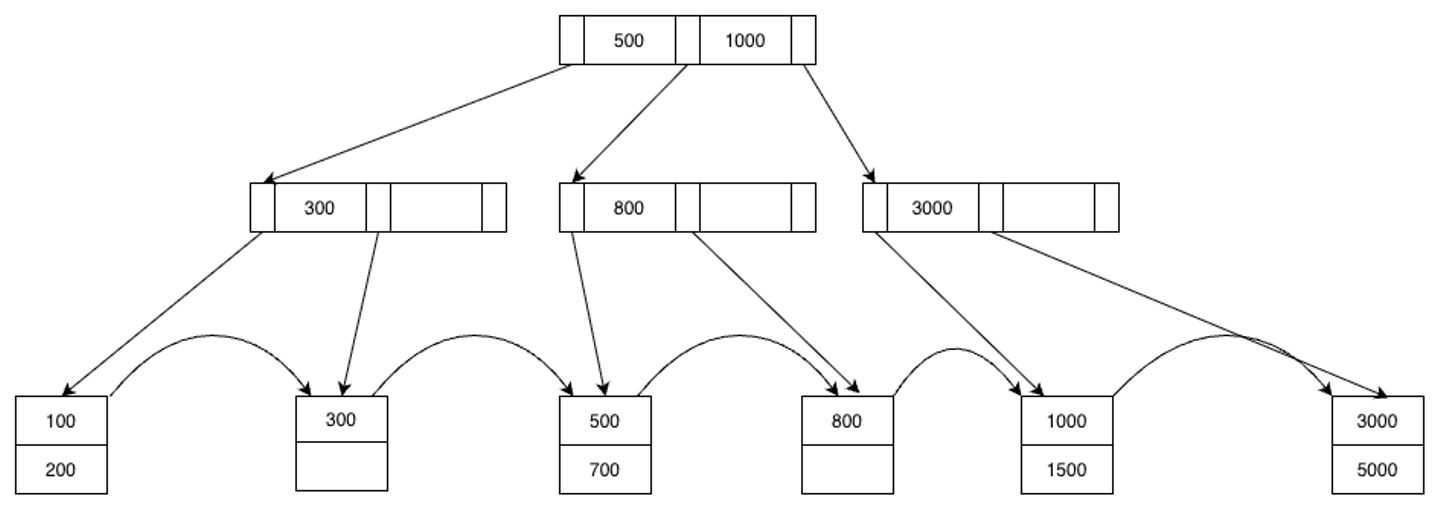
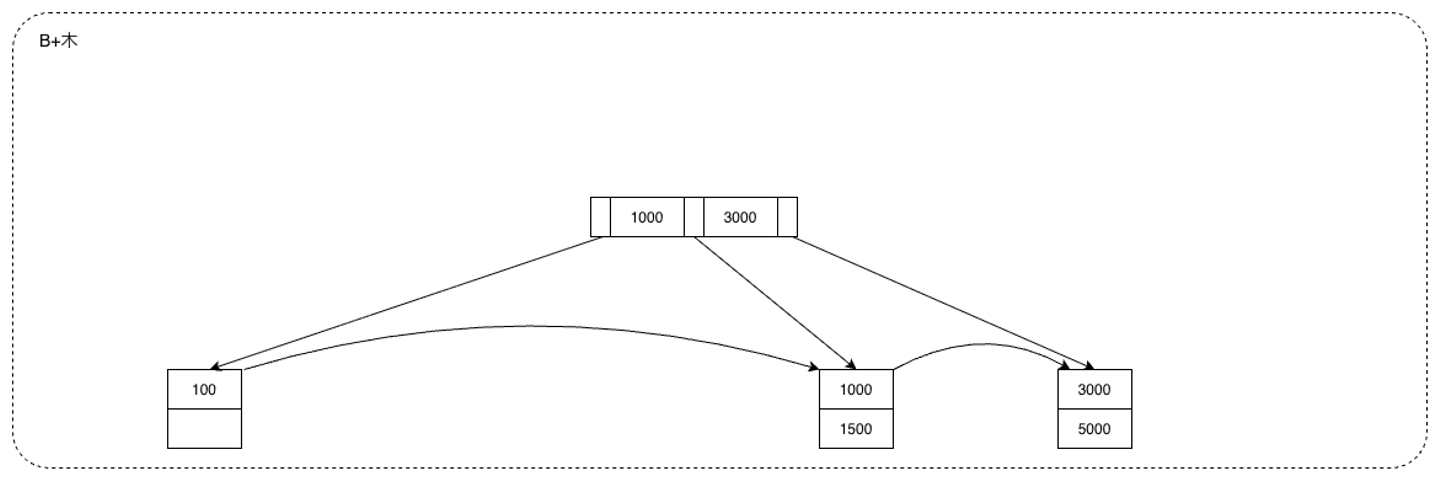
6.6 具体例 今回も図1のB+木で考えてみましょう。まず、800を削除します。800が格納されていた葉ノードはまだ半分以上使用されているので、6.1に従い終了します。
つづけて500を削除します。そうすると左から3番目のノードが使用されなくなったので、まず再分配を試みます。左の兄弟ノードはキーを借りると半分以上使用されなくなってしまう(=余裕がない)ので、次に併合を試みます。
自ノードと兄弟ノードを1つにまとめます。今回の場合自ノードは空、兄弟ノードは300が格納されるので、まとめて、[300]というひとつのノードになります。 兄弟ポインタを張り直します。500が格納されていたノードが削除されるので、300が格納されているノードから、[1000, 1500]が格納されているノードにリンクを張ります。 親ノードから、両者を分けていたキーを削除します。ここでいう両者とは削除対象の500と、兄弟ノードに格納されていた300なので、これらを区別していた500を削除します。 親ノードは500を削除してもまだ半分以上使われている(300が残っている)のでここで終了します。この時点でB+木は図3のようになります。
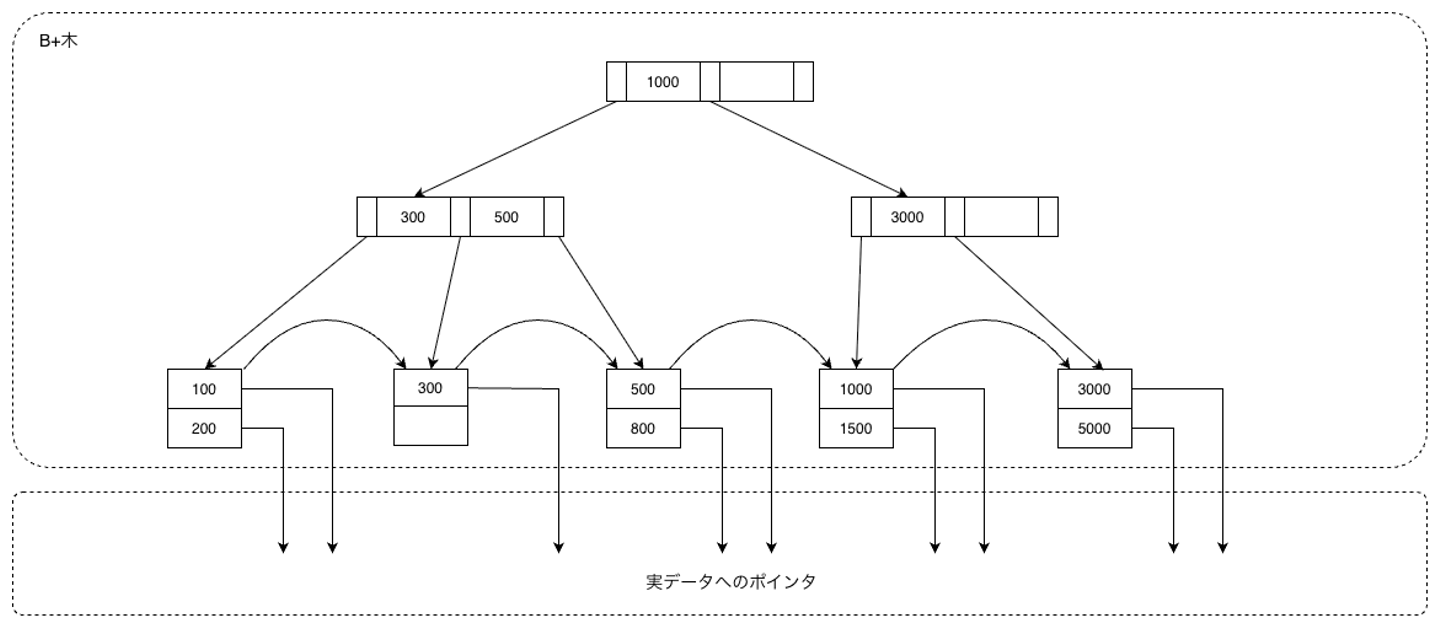
さらにここから200、300を削除することを考えます。200を削除したとき、左端の葉ノードには100がのこっているのでそこで終了します。つづけて300を削除すると、左から二番目の葉ノードは使用されてなくなるので、左の兄弟ノードとの併合を試みます。その結果先程と同様に、葉ノードは[100]のみの一つの葉ノードにまとめられ、100, 300を区別していた親ノードの探索キーである300が削除されます。そうすると左端の内部ノードが使われなくなるので、ここでも兄弟ノードが一つにまとまり、親ノード(根ノード)の探索キーが削除されます。最終的に根ノードが削除され、図4のようになります。
以上のようなアルゴリズムを使用することで、B+木の定義の一部である
全ての中間ノードは常に半分以上の領域が使用されている 根ノードから葉ノードまでの距離が常に一定 を厳密に守ることができ、結果として効率よく探索が行えることになります。
7. 勉強会でのディスカッション 勉強会では、本文で扱った内容のほかに、こんなトピックも話題に上がりました。
複合インデックスはどのようなデータ構造になっているのか プロダクト開発時、インデックスがうまく効かず遅くなっていたクエリを確認してみて原因を考える 中間ノードに、葉ノードにない探索キーが残るケースがありうるが、それは問題ないのか インデックスを張りすぎると、その分メモリを消費することになるがそれは実用上問題ないのか 参加したメンバーからは「直接探索が早いのは理解していたけど、範囲検索も早くなる理由があまりわかっていなかったので勉強になった」「挿入・削除処理を行っても木の高さが保たれ、探索回数が一定になるのは知らなかった」といった声がありました。
そこから自然に、冒頭で触れたグラフDBをいつ使うべきか、という話にも流れていきました。
グラフDBを活用した実サービスにはどのようなものがあるのか? グラフDBにおけるエッジは、RDBにおける外部参照として表現できるのでは? 最近よく耳にする GraphRAG は、本当に精度が高いのか? このあたりは、その場では決着がつかないまま「次回はちゃんと調べよう」というテーマとして残りました。新しい知見を得た上に、次に調べたいテーマまで議論の中で現れた、とても有意義な勉強会になったと思います。
8. まとめ ここまで B+木 の構造、検索、挿入、削除のアルゴリズムを追ってきました。最後に押さえておきたい性質をまとめると:
内部ノードはルーティング、葉ノードがデータを保持する 葉ノードを連結リストでつなぐことで範囲検索を効率化する 挿入では分割が、削除では再分配と併合が、ノードの均衡を保つ 結果として、検索・挿入・削除・範囲スキャンのすべてが対数時間で実現できる インデックスが思うように効かない、というのはパフォーマンスの課題で非常によくあるケースだと思います。冒頭で触れたように、選択肢には B+木 のほかにも GIN のような別系統があって、どれを選ぶかは結局それぞれの内部構造を理解しているかにかかってきます。AI に実装は聞ける時代になったぶん、こういう「 選択肢を比較して根拠を持って選ぶ判断 」の重みはむしろ増している気がしていて、その出発点として、B+木 の知識は長く使えるはずです。
9. おわりに Unyte ではいま AI プロダクト開発のエンジニアを募集中 です。AI 周りのデータ基盤や検索を、流行りに流されずデータ構造のレベルまで降りて考えるのが好きな人と一緒に働いてみたいと思っています。興味があればぜひ以下からカジュアル面談を申し込んでください。



/assets/images/23470125/original/7ea6868f-33ce-4df4-99b0-e6db9c9b0654?1775529819)

/assets/images/19784268/original/3258c855-9b82-40af-909c-63fb2f53a28a?1732434099)
/assets/images/19784268/original/3258c855-9b82-40af-909c-63fb2f53a28a?1732434099)


