【Quipperブログ】SRE NEXT 2020 で「SLO Review」というタイトルで登壇しました #srenext


こんにちは。Quipper採用担当の鈴木です。今回の記事は、@chaspy による「SRE NEXT 2020 で「SLO Review」というタイトルで登壇しました #srenext」です!是非、ご覧ください!
こんにちは。SRE の @chaspy です。
先日行われた SRE NEXT 2020 にて、SLO Review というタイトルで発表してきました。
https://speakerdeck.com/chaspy/slo-review
本記事では、会場に来られた方には内容を追体験してもらえるように、来られなかった方には伝えたかった内容を持ち帰っていただけるように解説します。
来場者への質問

会場への質問
- SLO という言葉の意味を知っているひと:9割以上、ほとんど全員
- 自分のサービスに SLO を定めて運用をしているひと:2割程度
- Error Budget Policy を定めて、SLO 違反になった際にリリースを止めるなどをしているひと:2,3人
事前に予想した通りの比率でした。まさに僕の発表は 1 を満たしているが、2をこれからやる、というひとに対するヒントを提供する発表だったからです。
発表内容
本発表は大きく3つのパートで構成されています。
本セッションを聴きに来られている会場の方に、SLO に関する質問をしました。
発表内容
- SLI/SLO についての基本的な知識
- Quipper での SLO を適用する過程からの Case Study
- SLI/SLO を適用するために必要な Tips
事前の聴衆へのアンケートでもわかる通り、ほとんどのひとが 1. SLI/SLO についての基本的な知識
は理解しているので、2. Quipper での SLO を適用する過程からの Case Study
をメインに話しました。
結論
結論はいつでも当たり前のことですよね。

結論
- SLI/SLO を定義し、レビューすることそのものには価値がある
- SLI/SLO ははじめから完璧ではない
- プロセスをチームに導入する際には認知負荷を減らし、段階的に導入することが重要
それはそう、となったところで、具体的に何をしてきて、どんな失敗をしてきたのかを話していきましょう。
SLI/SLO についての基本的な知識
教科書的な意味はみなさん SRE 本を読んで理解しているでしょうから、あっさり紹介するに留めました。
What
2種類の SLO は Datadog が定義しているもので、この2つは少しだけ扱いが異なります。

Event based SLO
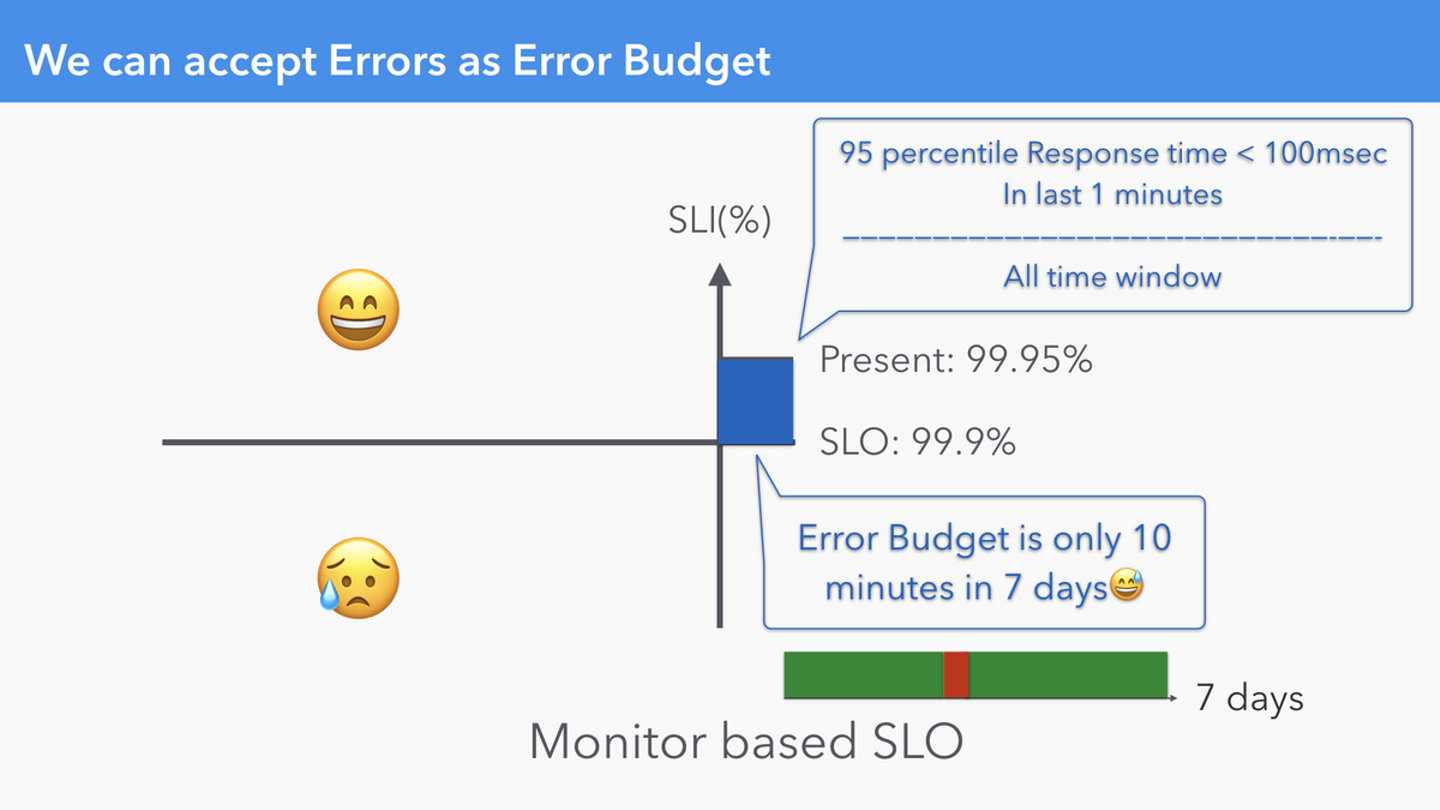
Monitor based SLO
一般的に SLO といえば、特定の Time Window(i.e. 7 Days, 14 Days, 30 Days etc.)の中で、「あとどれだけエラーを許容できるのか」という観点でエラーバジェットを扱います。これを踏まえると、前者の Event based SLO は分母である Valid Event も増えるので、同じ Time Window の中でもバジェットは増えたり減ったりします。一方、後者の Monitor based SLO は分母の Valid Event はその Time Window 全体となるので、1つの Time Window の中で考えると、バジェットは減る一方です。Availability Table が適用できるのも後者です。どちらが良い悪いではなく、微妙に挙動が異なることは理解しておきましょう。
いずれにしても本格的に運用するには Burn Rate / Threshold による Alert が必要です。(Datadog による実装を期待しています)
Cookpad @tatanabe_w さんの発表 - Designing fault-tolerant microservices with SRE and circuit breaker centric architecture ではこのあたりが紹介されていましたね。
Why
なぜ必要か、についてはよくある Dev と Ops それぞれの限定合理性に伴う対立問題を解消するための DevOps が登場したシーンを紹介しながら、Fact Based Decision Making のためである、という風に僕は解釈しています。

Reliability と Agility どちらにコストを投資するかの境界を Fact Based で決定するためのに SLO が必要
Reliability(Stablity と言われたりもする)と Agility(Productivity と言われたりもする)のどちらを優先するのか、その意思決定をするためのツール・考え方です。
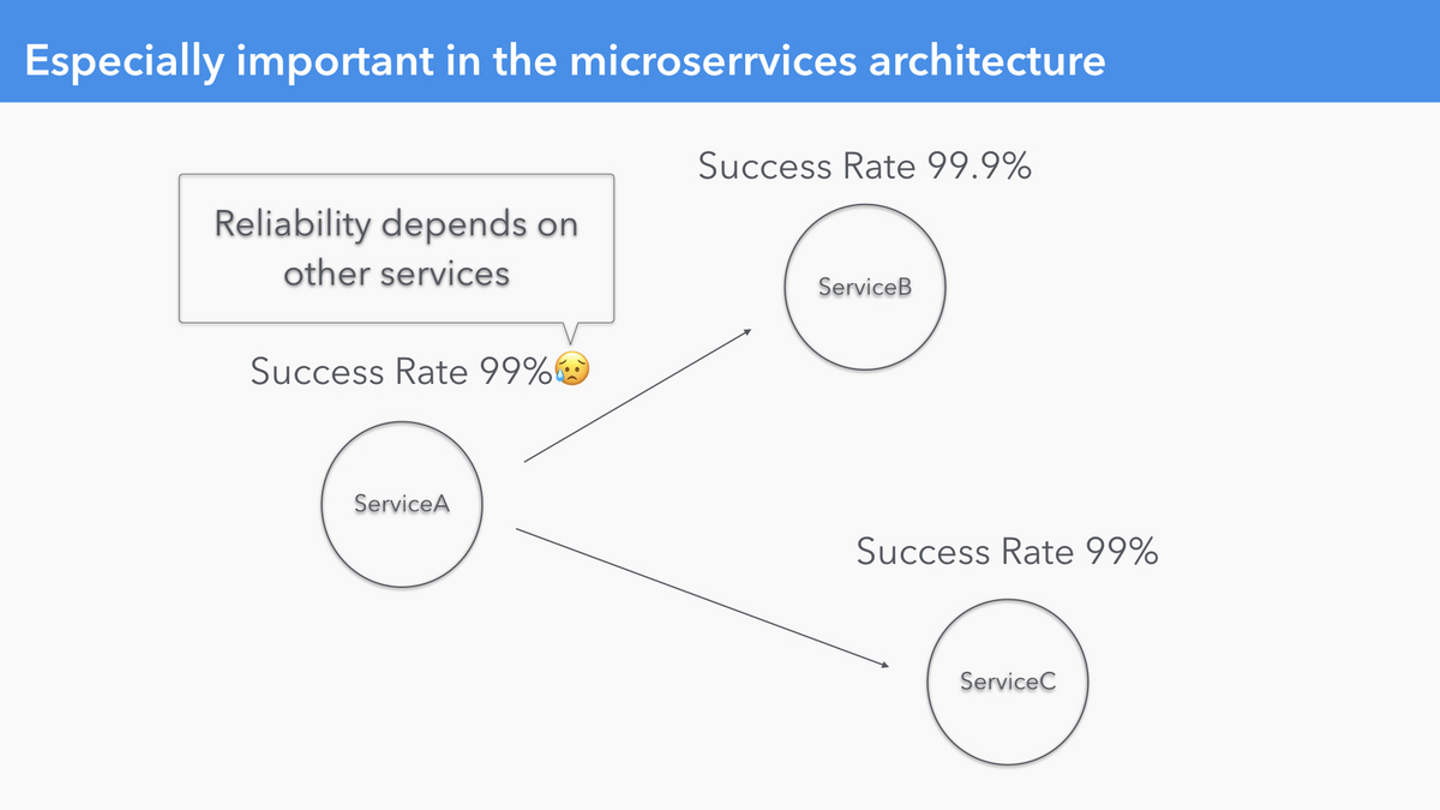
特にマイクロサービスアーキテクチャではサービスの信頼性は他のサービスの信頼性に依存する
特に、Microservices Architecture を採用しようとすると、サービスの信頼性は依存先のサービスの信頼性に影響を受けるため、各サービスで SLO を定義していなければ、自分のサービスの信頼性を分析・改善することができなくなってしまいます。そのため、(Quipperもそうですが)Microservices Architecture を採用する場合は SLI/SLO の定義と運用はもはや必須だと考えています。
Where
これは単に視点を提供しただけに過ぎませんが、信頼性を「どこで」計測するか、は非常に重要です。
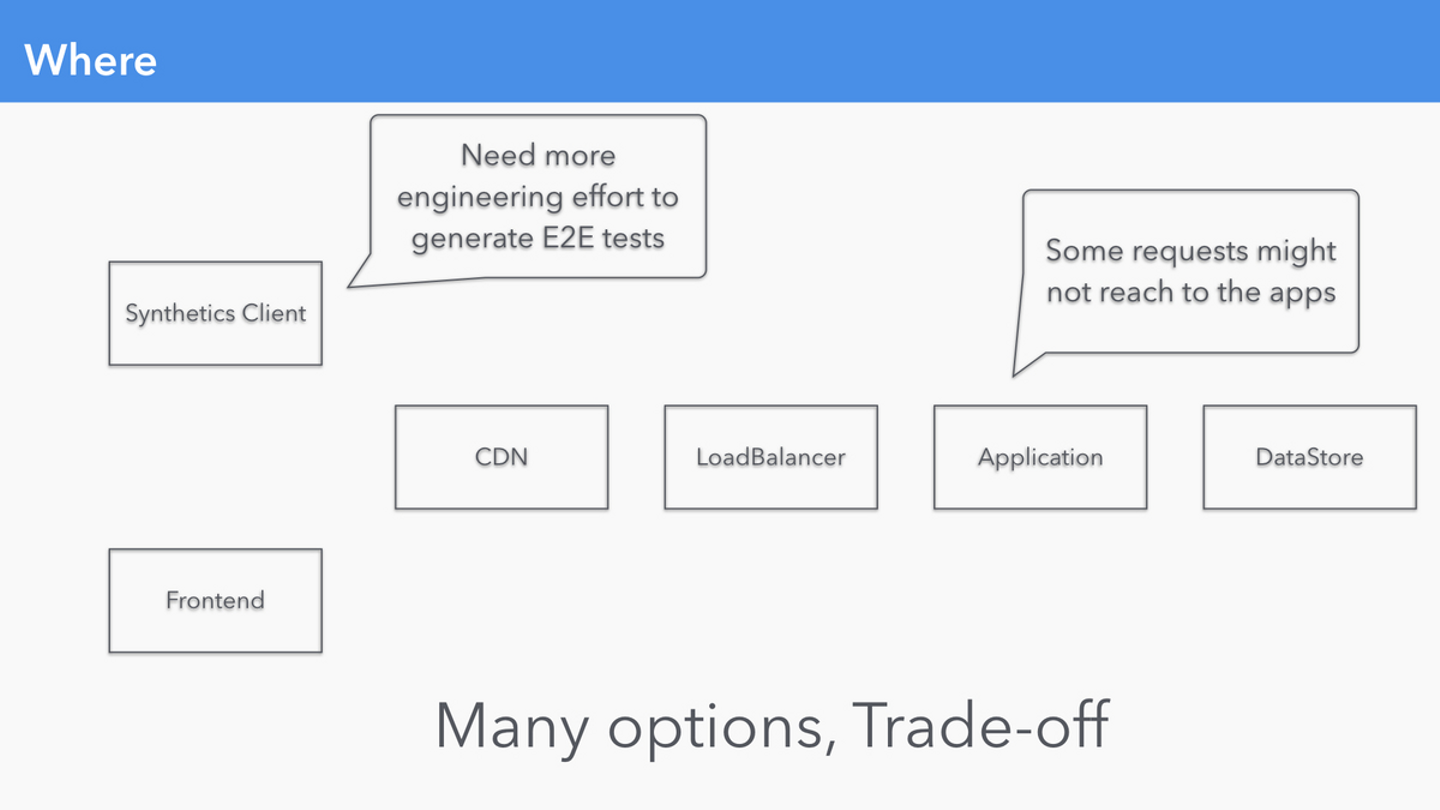
どこで SLI となる Metrics を計測するかでトレードオフが存在する
SLO を定める前に、計測可能な SLI が存在していなければ話になりません。
自分のサービスで SLI/SLO を定義しはじめる前に、アーキテクチャのどの部分で、何が計測しているかを最初に確認すると、不足している点を洗い出すのに役立つでしょう。
Quipper での SLO を適用する過程からの Case Study
さて、はじめになぜ Quipper という組織で SLI/SLO を推進する必要があったのか、その背景について説明させてください。
Self-Contained / 開発チームの自己完結化を目指して

2020年の SRE Team の Mission
2020年の SRE Team のテーマは "Self-Contained" / 自己完結化です。
開発チームが価値を提供するために必要なことを、開発チーム内で解決できるようにすることで、プロダクトの仮説検証を爆速で行えるようにすることを目指します。
これまでも、これらを支える仕組みとして、Design Doc, Production Readiness Checklist, Infrastructure Management(Terraform)の委譲などをしてきており、SLI/SLO もその施策の一環です。
さて、そういう流れで SLI/SLO を定義し、レビューすることを決めましたが、今回は以下の4ステップで徐々に進めることにしました。
- システムと組織を紐付け、オーナーシップを決める・決められる仕組みを作る
- 1人でプロセスをまわし、実現方法を確立する
- Developer と一緒に SLI/SLO を定義し、プロセスをまわす
- Error Budget Policy を定義して、それに従う
なぜこのようなステップを取ったのでしょうか。
スムーズに進めるためには以下のような前提条件が必要です。
- 定めた SLI/SLO が適切である
- 開発チーム自身で運用できる
Error Budget Policy を適用するためには、SLI/SLO が適切でなければそれを適用する説得力もないでしょう。しかし、はじめる段階では、何を、どのぐらいの目標値で、どのぐらいの時間間隔でサイクルをまわすのかの知見もまったくありませんでした。僕自身学びながらやる必要があったため、ある程度時間がかかるだろうという考えがありました。
後者に関しても、対象のサービス・チームは1つではありません。最終的には Japan / Global 双方で合計15のチームへ導入しました。このような状態では僕1人ですべてやるのももちろん現実的ではありませんし、かといって手順が確立していない状態でいきなり「やってみて」では広がるものも広がりません。そのために、対象を見極め、手順を確立し、少しずつ広げていくというアプローチを取りました。
システムのオーナーシップを決める・決められる仕組みを作る
この頃には、Ownership が明確でないサービスがいくつもありました。また、Owner を決められない - 共通で使っているサービスも少なくありませんでした。サービスのオーナーが決まっていなければ、SLI/SLO を推進するといってもどのチームにアプローチをしていくべきか決めることもできません。
最初に、既存のシステムに関しては VPoE, Product Manager にヒアリングをしてオーナーを決めました。また、決められないものは決められない状態であることを把握しました。
また、新規にサービス(Microservices)を作成する際には、Design Doc(以前は Production Readiness Check に項目があったが、設計部分を最近分離しました)の Stakeholders の項目に記入してもらうことにしました。これにより、「これは誰がオーナーなの?」という発言をよく聞くようになり、サービスにはオーナーシップが必要だという価値観はある程度共有されたように思えます。
1人でプロセスをまわし、実現方法を確立する
さて、「SLI/SLO を定義してレビューサイクルをまわす」と言っても、わからないものはたくさんあります。何を、どのぐらいの目標値で、どの期間でまわすのか、そして Green のとき、Red のときそれぞれのアクションは何か、どう考えればよいのか、どのように調査すればいいのか。これらすべてを明らかにするために、まずはいくつかのサービスに絞り、7日間隔ではじめました。
この頃、ちょうど Datadog から SLO Widget が Beta としてリリースされ、もともと Datadog に Metrics は集約していたため、SLO も Datadog で見ていくことにしました。
残念なことに、(今のところ)SLO に違反したときのアラートも、リッチでキュートな記録システムも存在しません。非常に単純ですが、とりあえずはじめる上では Slack の Reminder で毎週知らせて、Datadog Dashboard を確認して、結果を GitHub Issue に記録するという形を取りました。
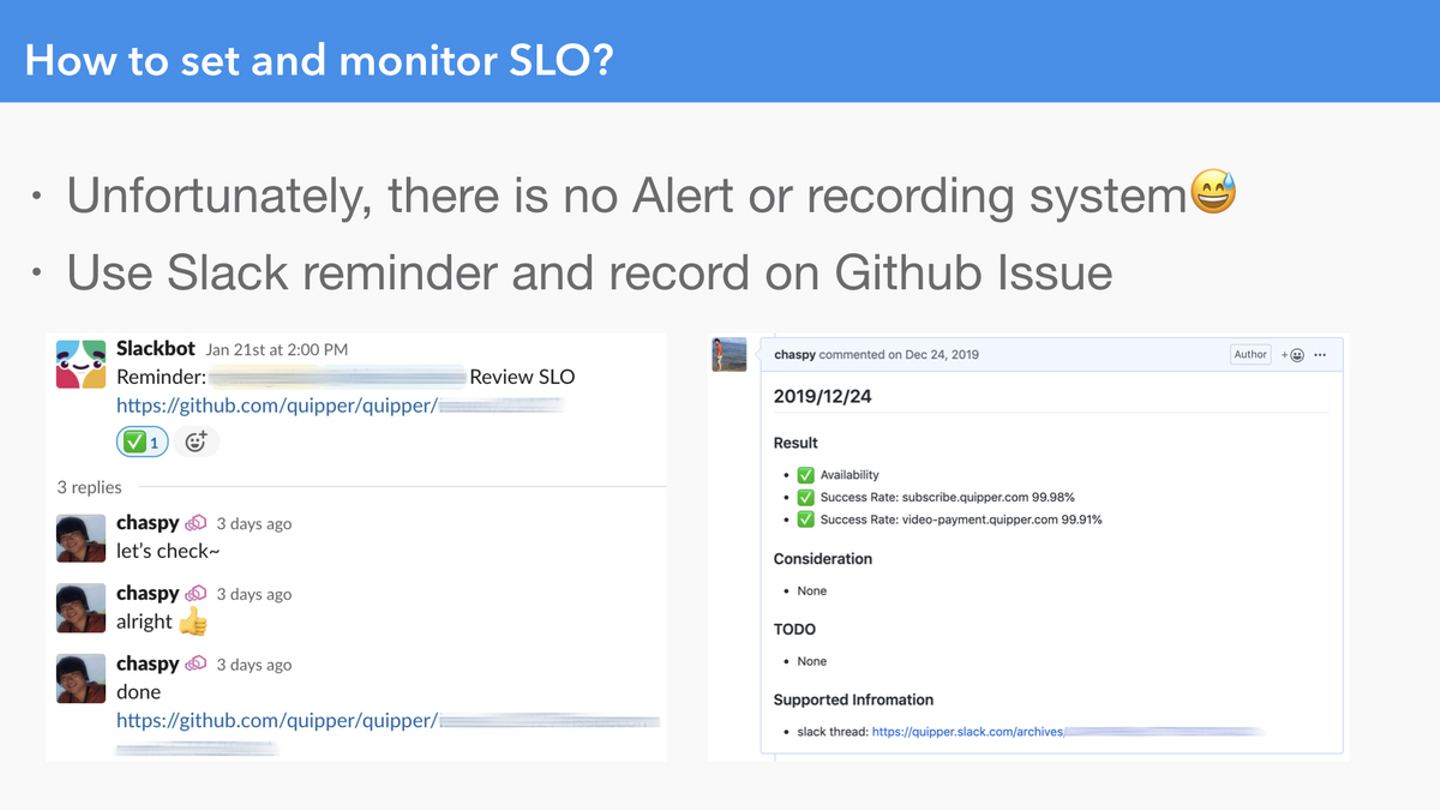
週1 の Slack Reminder に関係するチームメンションと GitHub Issue を Link するだけ。
観察結果は GitHub Issue に記録していく。
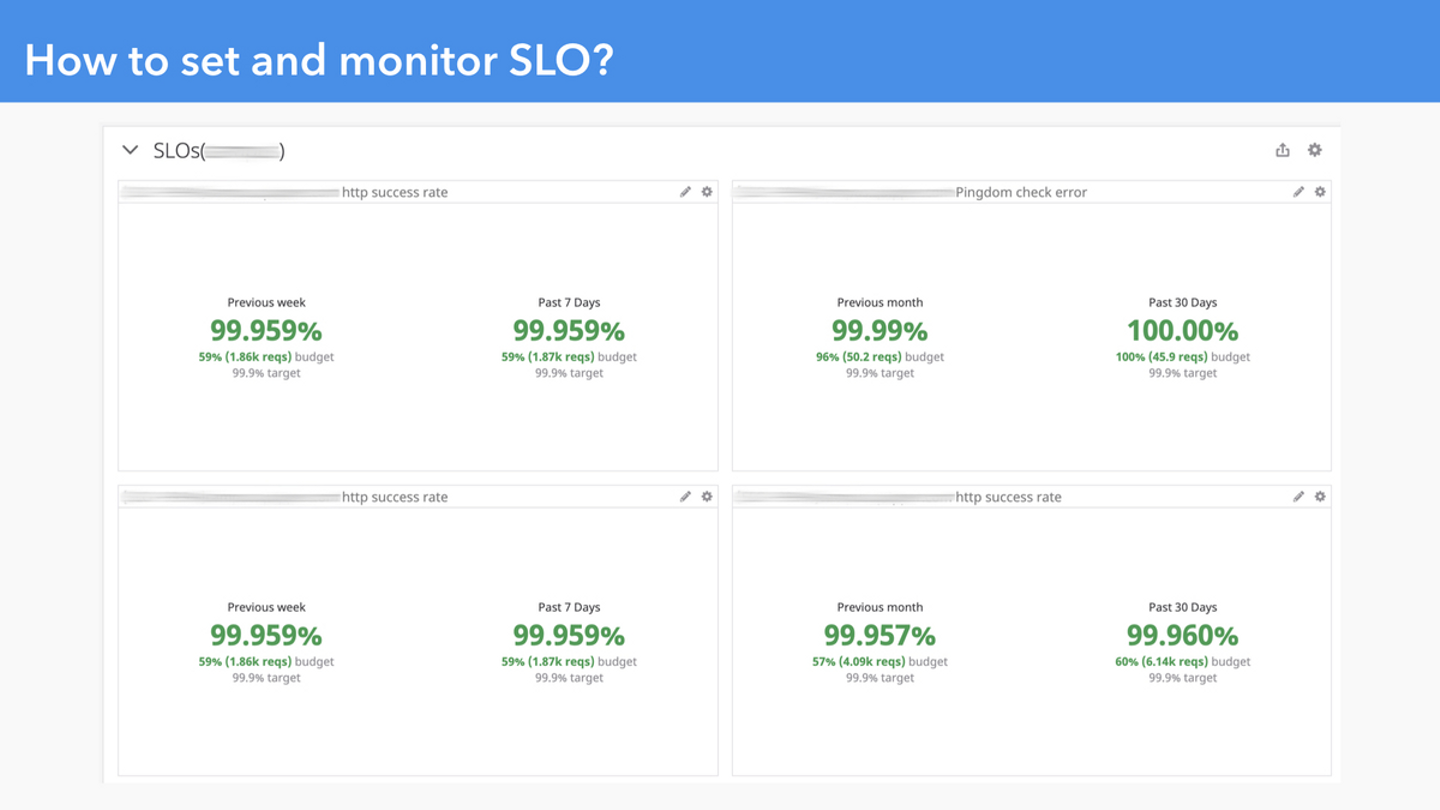
Datadog の SLO Widget を Team ごとの Dashboard に追加している
このやり方自体が最高だとも思いませんが、試験期間であることと、一刻も早くサイクルをまわしはじめて経験を積むことのほうが重要だと考えました。
このプロセスにおいては、現状取れている Nginx の Metrics を SLI としてまず採用し、SLO として 99% を設定してはじめてみました。しかし Availability Table を見るとわかる通り、99% は低すぎることは感覚的にも理解できますが、実際にやってみてもそうでした。かといって、99.99% は厳しすぎます。AWS EC2 で返金が一部で発生しはじめるのが 99.99% であることを考えると、その上で動くサービスが 99.99% 以上で動くことはできないでしょう。AWS に限らず、SLO は依存している Platform や外部サービスのそれを超えられない、という当たり前のことも温度感を持って理解できました。
このフェーズを3ヶ月ほどやってみて、もちろん手順自体を確立したこともあるのですが、「SLI/SLO を定義してレビューを繰り返すことは良い習慣である」ということに気づきました。SLO 導入の目的であった「Fact Based Decision Making」をするためには当然 Error Budget Policy が必要不可欠ではあるのですが、それがない状態で実際に観察をするだけでも良いことだな、と思えたのです。ここでいう良い習慣というのは、効果を定量的に判断できるわけではないが、ペアプログラミングやユニットテストのように、行動様式としてインストールすることで高い効果を感じるようなものに近いと感じています。

SLO を定義してレビューするサイクルを1人でやってみることで、それが良い習慣だということが分かった
信頼性を計測しようとすることで、実は計測できていない Metrics があることに気づきます。計測できてない Metrics を計測できるようにすることも、地道ながら大事な作業です。
また、日々流れてきては気づいたら復旧していたようなアラートに、モヤモヤしたりはしませんか。ちゃんと計測しているということは、都度対応して燃え尽きることを防ぐとともに、毎週見ることで現状の信頼性を計測できていることに安心して日々を過ごせます。
そして計測しはじめることで、信頼性を阻害する要因がたくさん存在していることに気づきました。実は共通で使っているプラットフォームのキャパシティが不足していて時々 50x を返していたり、毎週同じ時間に Push 通知によって Resouce が不足していたり、Rolling Update が実は Graceful ではなかったりといったことがありました。
このように、計測しはじめること自体が良いことだと確信した(それまでは本当に僕らに必要なものか、自分自身でも半信半疑だった)ので、各チームに展開して一緒にやっていくことに舵を切りました。
Developer と一緒に SLI/SLO を定義し、プロセスをまわす
この時期より前にも「こういう SLI/SLO っていうものがあるよ」というのは一部のチームに説明したことがありましたが、このフェーズで改めてチームごとに説明し、実現できそうなイメージが持てるかどうかを確認し、一緒に SLI を考えたり、レビュープロセスを一緒に行うチームを少しずつ増やしていきました。(今月前半に行った海外出張でも各国の Developer にあらためて説明をしました)
このフェーズではいくつかの技術的な問題にぶつかりました。
Dos Detector が 503 を返すため、信頼性を守っているにもかかわらず、http success rate の SLI を劣化させてしまう
いくつかのサービスでは Internet Facing に存在する Nginx での http success rate を SLI として採用していました。
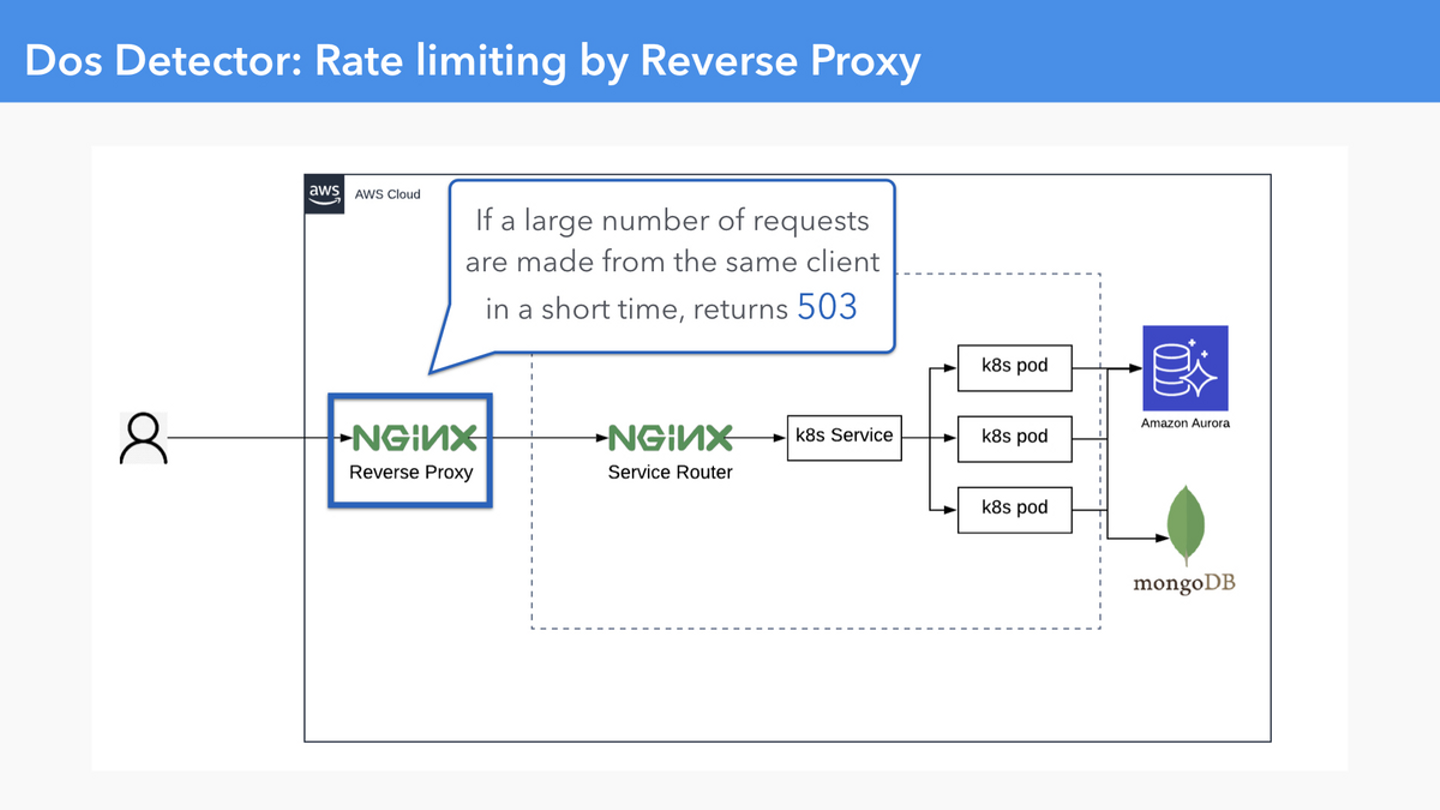
Nginx の Rate Limiting の機能が 503 を返すことで SLI を意図しない形で劣化させていた
弊社では Dos Detector という同一 Client から短時間で大量のアクセスがあったときに、一定時間 503 を返却する機能を ngx_mruby で実装しています。もしこれがない場合、悪意のある攻撃によって Backend の Computing Resource や Nginx の Connection を使い果たしてしまい、Service Down を招いてしまうかもしれません。それを避けるための仕組みであるのにかかわらず、現状の SLI の定義方法では SLI が劣化してしまう、ノイズとなってしまう問題がありました。
というわけでこのような Rate Limiting をするのにちょうどいいステータスコード 429 Too Many Requests に変更することにしました。単純に以下のような書き換えをします。

しかし、ngx_mruby がこの定数をサポートしていなかったので、ngx_mruby に PR を送りました。Support HTTP_TOO_MANY_REQUESTS #445 この修正が入った ngx_mruby v2.2.0 がリリースされたので早速導入したのですが、同時にmruby が v2.1.0 になったことで、使用している mrb である matsumotory/mruby-userdata が動かなくなってPRを送ったりしていろいろ大変でしたが、無事に 429 に変更され、Product Team が Dos Detector 発動の影響かを気にしなくてよくなりました。(レビューしていただいた @matsumotory さん、ruby-jp でアドバイスをいただいた _shuujii さんありがとうございました!)
共有されているサービスの SLI を path で区別できない
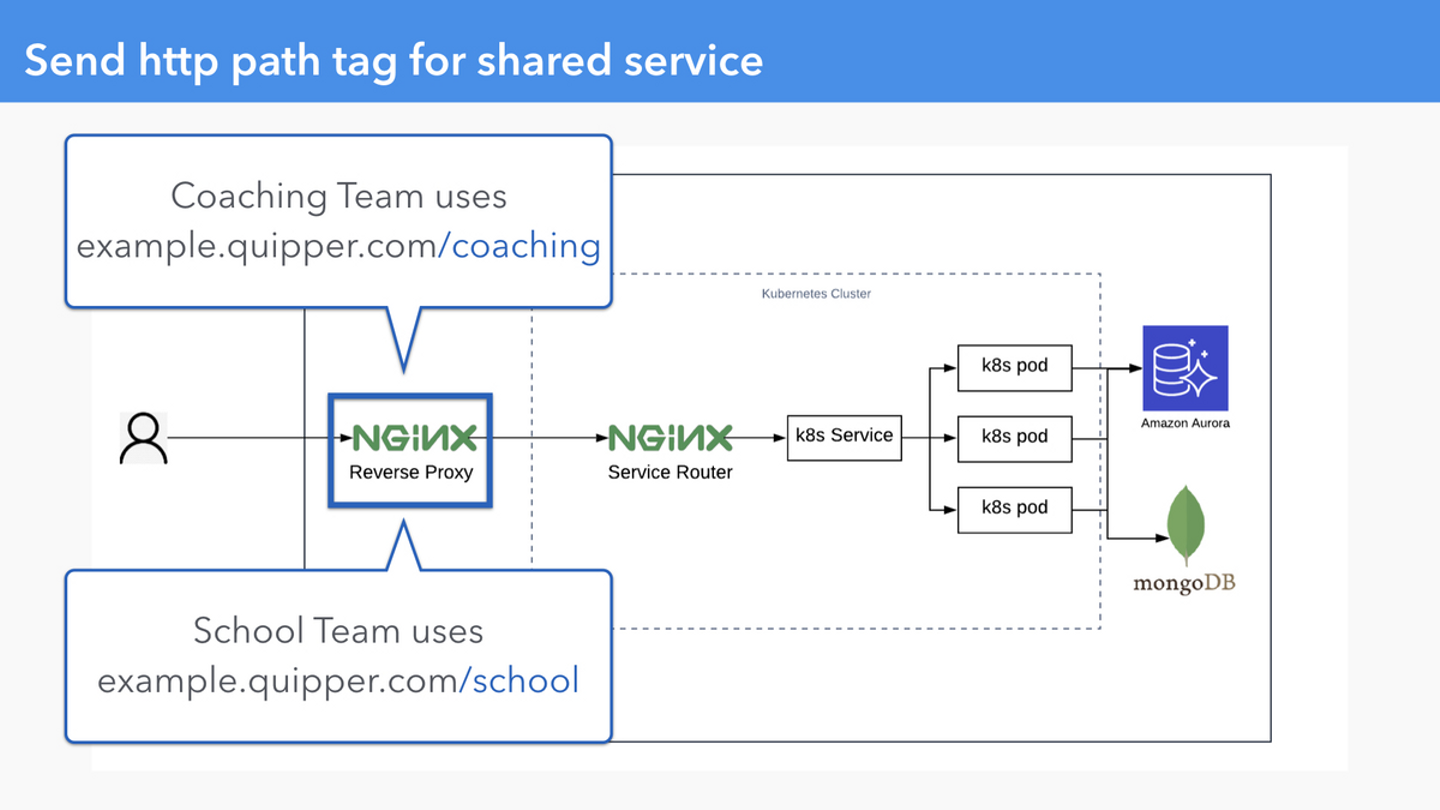
同一のサブドメインからアクセスされるサービスが複数のチームから使用されていた
example.quipper.com を2つのチームで利用している場合、example.quipper.com 全体の http success rate や latency を計測したとしても、それが目標値を満たせなかったとき、どちらのチームが調査するのを決めることができません。
Quipper では Nginx の log は fluentd で log-aggregator というサーバに送ったあと、filtering や metrics の生成などの処理をした結果、Datadog や BigQuery などのデータストアに送る仕組みがあります。
今回はこの処理の過程で fluentd の Filter Plugin である record_transformer を使用している箇所で、path を tag として送ることにしました。しかし、path には UUID や Object ID など含まれていたため、カーディナリティが高くなってしまい、Datadog のクエリが遅くなってしまったため、これらを _
に mask し、Normalize する処理をいれました。

この他にも、同じ Path でも GET と POST では異なる Latency SLI を持ちたい、という要望もあったため、それらも Tag として送る変更をいれました。このようなことも実際に Product Team を一緒にはじめるまで気づけなかったことでした。
直接サービス間通信をするサービスの SLI となる Metrics が存在しない
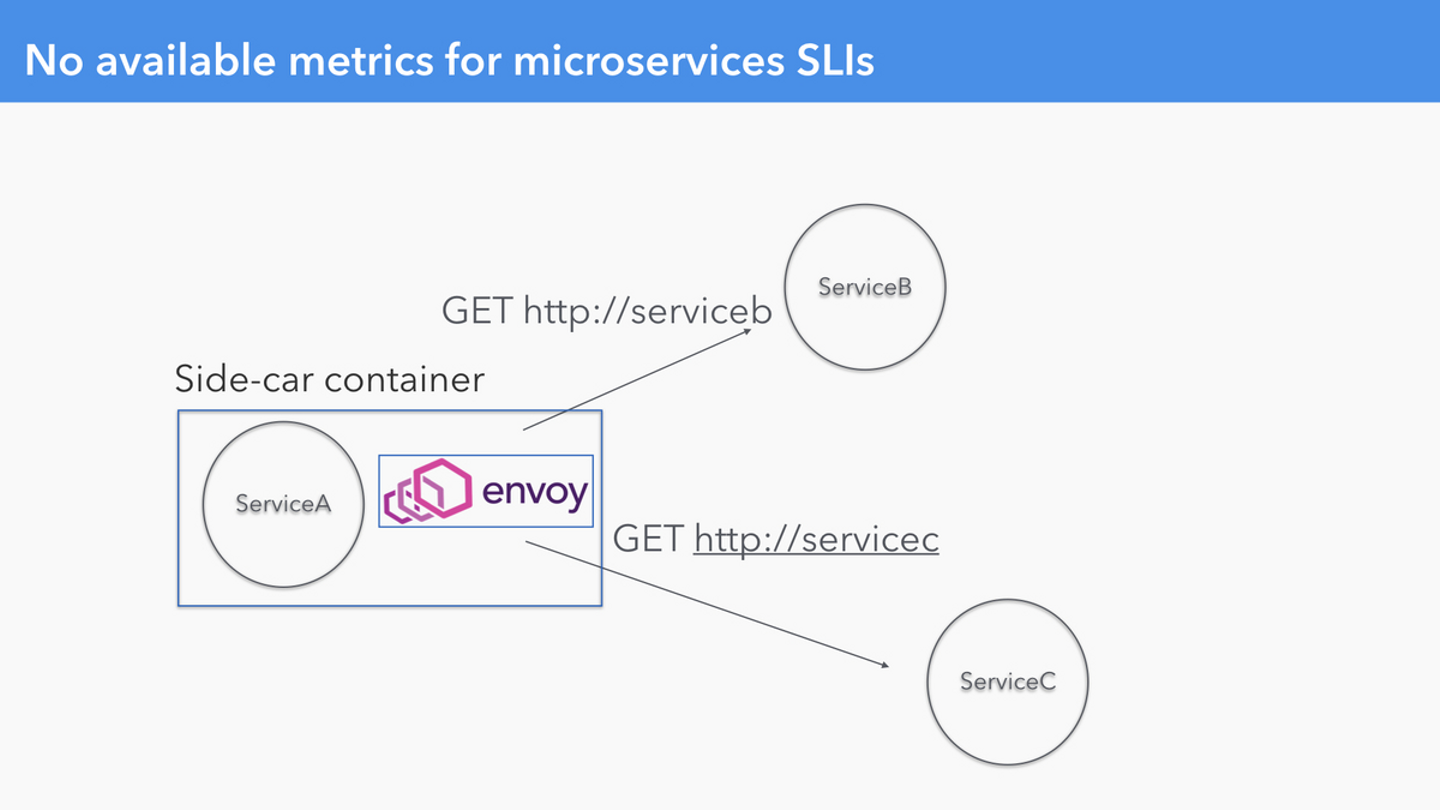
サービス間通信に Envoy Proxy を挟むことで Metrics を取得した
Quipper では Microservices がいくつか存在し、それらのサービスは別のサービスから直接呼ばれています。そのため、各サービス内の APM 以外では一切の Metrics が取れていませんでした。
そのため Envoy Proxy をサービス間通信に経由させることで、Metrics を収集し、それらを Availability / Latency SLI として採用できました。
Error Budget Policy を定義して、それに従う
このように、最初からシステムは綺麗に分割されているわけでもなければ、必要な Metrics が取得できているわけでもないでしょう。また、採用する SLI や、決定した SLO が各チームで納得できるまではある程度の期間が必要だと思います。
そしてその納得感が得られたところで、Developer / Product Manager / Product Owner の合意を得て Error Budget Policy を制定していく未来が見えてきます。まだまだそこまで行くにはもう少し時間がかかるかもしれませんが、次のステップとしてこのフェーズを目指しています。
SLI/SLO を適用するために必要な Tips
さて、半年ほど試行錯誤してきた中で、次同じことをみなさんがやるとしたら、知っておいたほうがいいと思うことをいくつか説明します。
標準化されたSLIを提供する
今回、Developer と一緒に SLI を考えはじめてからあれがないこれがないとバタバタ用意しはじめましたが、実際はサービスのアーキテクチャを考えればこのようなパターンがあることは予期できたように思えます。
SLI は User Happiness を表すべきであり、それを一番知っているのは Product Team なので、Product Team が決めるべき、という考えが当初はありました。これはこれで間違ってはいませんが、いきなり Product Team がはじめるにはハードルが高いでしょう。
まずはじめてみることも大事ですが、それよりも「最初はここからはじめる」という標準的な・推奨する SLI を提供しておけば今よりももっと早く進められたんじゃないか、という反省があります。はじめたあと、少しずつ必要なだけ変更を加える、という方法を取ることができます。
また、今後 Microservices 化を進めていくに従い、サービスごとの SLO を比較するためには、SLI は標準化されていくことになると思います。この点からも、最初に標準化された SLI(特に、Availability / Latency)を用意しておくことはこのプロセスを広げていくために価値があると私は思います。
設定は早い段階でコード化する
Product Team と一緒にやりはじめるフェーズで、(もともと Terraform には慣れていたこともあって)なんとなく Datadog SLO を Terraform 化しましたが、これも早い段階でやっておくべきでした。
もちろん GUI でポチポチ設定をすることもできるのですが、僕1人でやっていたフェーズですら作業負荷が無視できなくなりました。Product Team に広げていく段階では GUI の操作方法を説明するよりは、コード化されているものを真似して作ってもらうなり、すでに作られているものの目標値やクエリを1行変更することはとても容易です。

SLO は一度コード化してしまえば、設定変更は誰でも簡単にできる
実際に、コード化することでいろんな Team の Developer が興味を持ち、「ここをこうすればいいよ!」と伝えるだけで Pull Request を送ってくれるようになったように感じます。
なお同様に Datadog Dashboard はいまだにコード化されておらず、近日中に行う予定です。
学習曲線を急勾配にする
これは SLI/SLO だけに閉じた話ではありません。前半で紹介したように、Design Doc, Production Readiness Checklist, Terrform の委譲, Postmortem といった SRE の Practice を組織に広げていくためには、これらに対する認知負荷を低くし、少ない時間で高い効果を得られるような心がけが必要です。
そのためには Document を書くことはとても重要です。今回はこれを作成するのが僕自身遅れてしまったことが反省点の1つです。
SRE は、上でも下でもなく、Product Team の横を並走するような役割だと僕は思っています。時には安全のために制約を課したりすることはありますが、自己完結化を目指すためには、SRE にしかできないことを極力なくしていくことが必要です。そのために Quipper では、作業を単に Product Team に押し付けるのではなく、作業負荷が増える Product Team が楽に習得できるように、良いドキュメントの整備は当たり前として、トレーニングセッションや、ペアワークなどを積極的に行っています。チームごとの密なコミュニケーションがなければこの状態にはたどり着けなかったと思います。
謝辞
貴重な発表の機会を作っていただいたSRE NEXT 2020 運営スタッフのみなさんに心から感謝します。
このプロセスを一緒に進めた Quipper Product Team のみんなに心から感謝します。
このプロセスを進める上で Review や相談で力になってくれた Quipper SRE Team のみんなに心から感謝します。
おわりに
Quipper では世界の果てまで学びを届けたい仲間を募集しています。カジュアル面談もお気軽にどうぞ。

/assets/images/8020079/original/f5632a6b-81e7-484b-87e8-9a2dd6aeeee7?1635733533)


/assets/images/8499187/original/1944cc29-7cbf-49e3-a0e7-345d3a36e4b1?1642059254)


