

こんにちは。Quipper採用担当の鈴木です。今回の記事は、SREの@chaspyによる「Production Readiness Check のはじめかた」です!是非、ご覧ください!
こんにちは。SREの近藤(@chaspy)です。
新しいサービス、あるいは Microservices を 本番環境へリリースする際、私たちは何を注意すべきでしょうか。
今回は、Production Readiness CheckList と導入方法について説明します。
Production-Readiness Checklist とは
Service を本番環境へリリースする前の、信頼性観点でのチェックリストです。このチェックリストを事前に行うことによって、本番での Service 運用開始後の問題をなるべく引き起こさないようにする、あるいは起きたときに最善な手が打てることが期待できます。
Production-Ready Microservices (日本語版:プロダクションレディマイクロサービス ――運用に強い本番対応システムの実装と標準化 を読まれたひとも多いと思います。本書の付録に、本書のサマリともいえる Production-Readiness Checklistが掲載されており、後で紹介する、Quipper でのチェックリストも本書のものを参考にしました。
なぜやるのか
Quipper では アプリケーションプラットフォームとして Kubernetes を採用しており、Developer がビジネス要件に合わせて主体的に新しい Service を構築できる状況になっています。Quipper / StudySapuri のビジネス拡大に伴い、今では月に1つ以上新しい Service が増え続けています。
記事投稿日現在、StudySapuri / Quipper ともに Kubernetes Deployment 単位で40以上の Service*1 が動いており、このすべての詳細を SRE が把握することは今後ますます難しくなっていくでしょう。そのため、Developer が Ownership を持って Service を増やし続けながら、信頼性を高い水準で保つための何らかの仕組みが必要です。
Production Readiness Checklist を行うことで、本番環境に出てからはじめて問題が発生したり、問題発生時に一部の開発者以外誰もその Service のことを知らず調査ができない、といった事態が起きる可能性を低くすることができます。
このように、システムが信頼性を持つ上での最後の砦として、障害が発生しないように、事前に"仕組み"を構築し、標準化して広げることも SRE の大事な仕事の1つです。
Readiness Check の内容
早速、実際に中身を見てみましょう。前述の通り、Production-Ready Microservices をベースに、何度か改善を繰り返してきました。
CheckList は GitHub の Issue Template として管理されており、いつでも Pull-Request で改善を行うことができます。
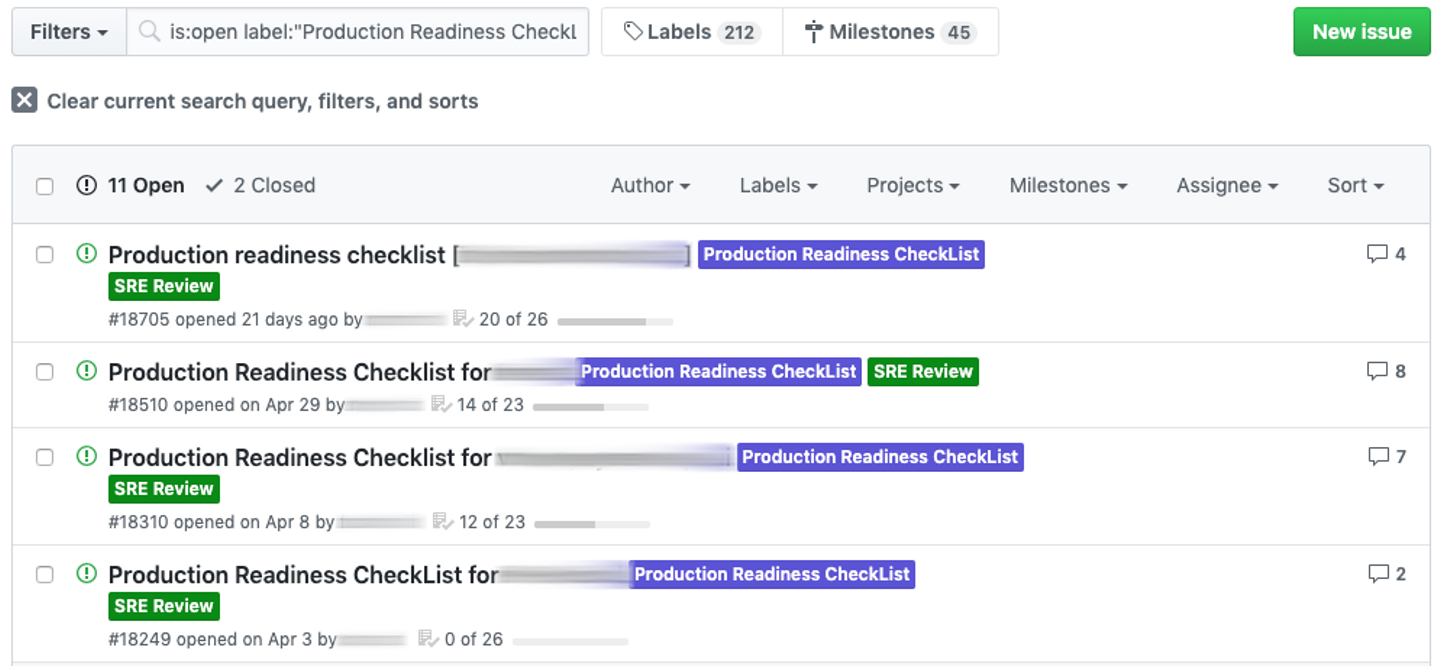
(なお、リリース済の Service に関しても見直しの意味をかねて、少しずつ実施しようとしているため、Openが多くなっています)
以下は、記事公開時現在の Quipper の Checklist です。
---
name: Production Readiness Checklist
about: This checklist is your guide to the best practices for ensuring stability, scalability, and reliability of a new service in the production environment.
labels: SRE Review,Production Readiness CheckList
---
# Production Readiness CheckList for {NEW SERVICE}
## Stakeholders
- [ ] Stakeholders
- [ ] Service Owner: # Set @github-group as Technical responsibility of the service
- [ ] Product Owner: # Set @service-unit as Business responsibility of the service
- [ ] Reliability: @quipper/sre
- [ ] End Users: # i.e Students or Teachers. Please describe as much as possible.
## Architecture
- [ ] Create architecture diagram
- Please determine the traffic pattern.
- Who is end user?
- What components does the service depend on?
- Include it as component in the diagram
- Application(Pod)
- Datastore(RDS/Erastic Search)
- Reverse Proxy
- CDN
- Jenkins
- Object Storage(S3)
- [ ] Update `<service name>/microservices/service.yaml` for Service Dependency graph
- [ ] app1
- [ ] app2
- [ ] Architecture review with SRE
## Monitoring / Logging
- [ ] Synthetic: Notify a synthetics error(Pingdom) (@quipper/sre)
- Is it published on internet? yes / no
- Endpoint: https://foobar.quipper.com/ping
- [ ] Application: Notify an application error(Sentry)
- url:
- [ ] Application Monitorin(NewRelic)
- Production url:
- Staging url:
- [ ] Create datadog dashboard
- url:
## Compute Resources
- [ ] Access load is predicted: yes / no
- [ ] comment:
- [ ] Set Resource(Memory/CPU) limit/request of pods
- [ ] Set ReadinessProbe / LivenessProbe
- [ ] Set appropriate database connection
- [ ] Load test
## SLO (Service-level objective)
SLO is an availability goal. It is expressed in percentage like `99%`, `99.9%`, `99.99%`.
SLO is a measure for end users. It should be related to the end users' behavior.
- [ ] Product: # SLO as a whole product that calls this service
- [ ] Service1: # SLO of this service. It can be decided more than one.
- [Sample] Success rate is more than 99.9%
- [Sample] Response times smaller than 100 msec is more than 99.99%
- [ ] Service2: # SLO of this service.
- [ ] Set Monitor for SLO and Add SLO widget to Dashboard
## Fault Tolerance
- [ ] Circuit breaker is implemented on the caller side: yes / no
## Release Cycle
Choose one:
- [ ] Same Weekly Release with sapuri/quipper
- [ ] Individually / Arbitrarily Release
## Deployment Strategy
- [ ] Ramped (aka rolling-update)
NOTE: If you wish to use a different deployment strategy (e.g., canary), please request it to SRE.
## Release date
- must: 20yy/mm/dd
- want: 20yy/mm/dd簡単に各項目について説明します。
Stakeholders
この Service の Stakeholders を記載します。障害が発生したときに誰が困るのか、誰が責任を持って対応するのかを明らかにするために記入してもらっています。
Architecture
Traffic Flow がわかるように、図を書いてもらっています。問題発生時、この図があるとないとでは解決のスピードが大きく異なるでしょう。また、Service 間の Dependency がある場合、特定のファイルに記入することで、自動的に Graphが生成される仕組みがあり、そのための項目もあります。
End User から、pod、また Data Store や Jenkins などの Pipeline などを書いてもらっています。これはどちらかというと Documentation の文脈が強く、将来1年後、3年後に Developer が入れ替わったときでも対応できるように書いてもらっている狙いがあります。将来的にはこの内容から Document が自動生成されるようにする予定です。
Monitoring / Logging
Quipper で使用している Monitoring / Logging tool の SetUpが終わっているかどうかを確認するセクションです。現在、この点は以下のような課題を感じています。
- DataDog DashBoard の Template のようなものがないため、SRE が Support している
- NewRelic / Sentry の Install は各 Service の Developer が手動で毎回入れている、提携作業のため自動化の余地がある
Compute Resources
いわゆる Capacity Planning を行うセクションです。Service の負荷特性を事前に説明してもらい、(例えば生徒が使うから夜がピークとか、学校の先生が使うから日中のみとか)それを元に Load Test を行ないます。Load Test はそれだけで大きなトピックであり、これは別の機会に書ければと思いますが、Load Test の結果を元に Compute Resource が十分かどうかを確認します。
SLO (Service-level objective)
必要な Monitoring / Logging の準備が整い、Load Test を行ったあとに、SLO を決定します。SLO がどういうものなのか、あとで何度も変更することができること、今後も Developer 主体で機能開発と信頼性向上のどちらを行うかを選択する指標として活用してほしい、ということを説明します。 SLO はまず決めて、サイクルをまわすことが大切です。
Fault Tolerance
現在 Quipper の Kubernetes Cluster には Cluster Level で Circuit Breaker を行うことができません。該当の Services までのアクセスが複数の Pod を経由する場合、可能な限り呼び出し側で Circuit Breaker が実装できないかどうかを検討してもらっています。
Service に障害が発生したときに、それが二次災害、三次災害を引き起こすことを避けるために、必要な観点です。Quipper では実際いくつかの Service に Cucuit Breaker が実装されており、障害発生時には手動で呼び出し元の Service でそれ以上後続の Service に通信を行わずにエラーを返すことができます。
Release Cycle
現在、Quipper / StudySapuri は週次でリリースをしていますが、一部のサービスはそれ単体でリリースできるような仕組みが整っています。新しくできる Service に関しては後者の単体でのリリースを取ることが多いです。
Deployment Strategy
現在私たちは Ramped(Rolling Update) を行っています。他の Strategy については ContainerSolutions/k8s-deployment-strategies を参照ください。
Release date
この Checklist をいつまでに終わらせる必要があるのかを知るためにセクションです。一応目安として一ヶ月前にはこのListをはじめてね、という風に Developer にお願いしています。
運用方法
この Checklist 自体は GitHub の Issue Template となっているので、誰でも Pull-Request で改善可能です。実際に初版を公開してから5回ほど改善をしています。
新しい Service を公開したい Developer は、まずこの Template を選択して Issue を作ります。現状は30分程度時間をとって、Developer と SRE の誰かで Meeting を行ない、Architecture のラフな絵をホワイトボードに書きながら、この Service がどういうものなのかの大枠を説明してもらいます。その後、項目を上から簡単に説明し、TODO を明らかにしたあとは、Developer 主体で進めてもらい、Checklist が全部埋まれば Close されます。
この Checklist をやらなければいけないということを知らせるために、新しい Service が追加される Pull-Request が作成された際に、GitHub Actions と Danger により作成を促す注意文を投稿しています。
まとめ
Application Platform を Kubernetes に移行したおかげで、Capacity Planning や Load Test, Monitoring / Logging も同一の仕組みを使うことができることに非常に大きなメリットを感じています。
ビジネスや組織をスケールさせるために、Checklist として標準化をすることで事前に必要な準備を Developer が主体的に行うことができるので、非常に有益な取り組みです。まずは Issue Template を作り、新しい Service に対してチェックリストをはじめてみましょう。
おわりに
Quipper では "完成"のない Production Readiness Checklist をさらに効果的なものに改善し、 Microservices の信頼性・安定性を向上させたいSenior SREもしくはそれ以外を募集しています。
*1:一部は Microservices として動いているが、すべてがそうではありません。また、Application ごとに Worker が複数存在し、それも異なる Deployment として動いているため、単純に40以上の Serviceが動いているわけではありません。

/assets/images/8020079/original/f5632a6b-81e7-484b-87e8-9a2dd6aeeee7?1635733533)




/assets/images/8499187/original/1944cc29-7cbf-49e3-a0e7-345d3a36e4b1?1642059254)


