グラフDBのneo4jを立ててみた

最近Facebookの広告にちょいイラ立ちを覚えることが多くなってきた林です。
スタイリィでは新しい機能を開発する際にできるだけフラットな考え方で、インフラやアーキテクチャを選択するようにしています。開発のスピードという点では過去に利用した方式に合わせた方が良いのですが、それを続けているとどんどん既存システムが時代に離れていき、軌道修正しようと思った頃にはだいぶ出血を伴う移行をしないといけなくなると思っています。
さて、先日スタッフに聞いて初めて知ったAWSのNeptune。
「人の好みを分析して、近い人を探そうとしているじぶん仲介にはグラフデータベースがあっているのではないか!」、「グラフデータベースがあれば、あるユーザーに嗜好が近い人を近い順に10人取ってくる」なんてことが簡単にできそう、などと思い使ってみようと思いましたが、まだリミテッドプレビュー状態。
使わせてよー、とAWSに登録しておきましたが、招待が来るのはいつのことやら。
そういえばAmazon Echoも4ヶ月も待たされたやんー。と思いつつ待ちきれないので、自分でグラフDBを立ててみてテストすることにしました。
利用したのはneo4j。
立ち上げる方法はqiitaとかにいっぱい載っているので割愛します。サンプルの映画データベースを取り込んで見ました。
MATCH (actor:Person)-[r:ACTED_IN]->(movie)
WHERE actor.name = "Keanu Reeves"
RETURN actor,movie
こんな感じでクエリを打つと、キアヌリーブスの出演している映画がグラフィカルに取得できます。
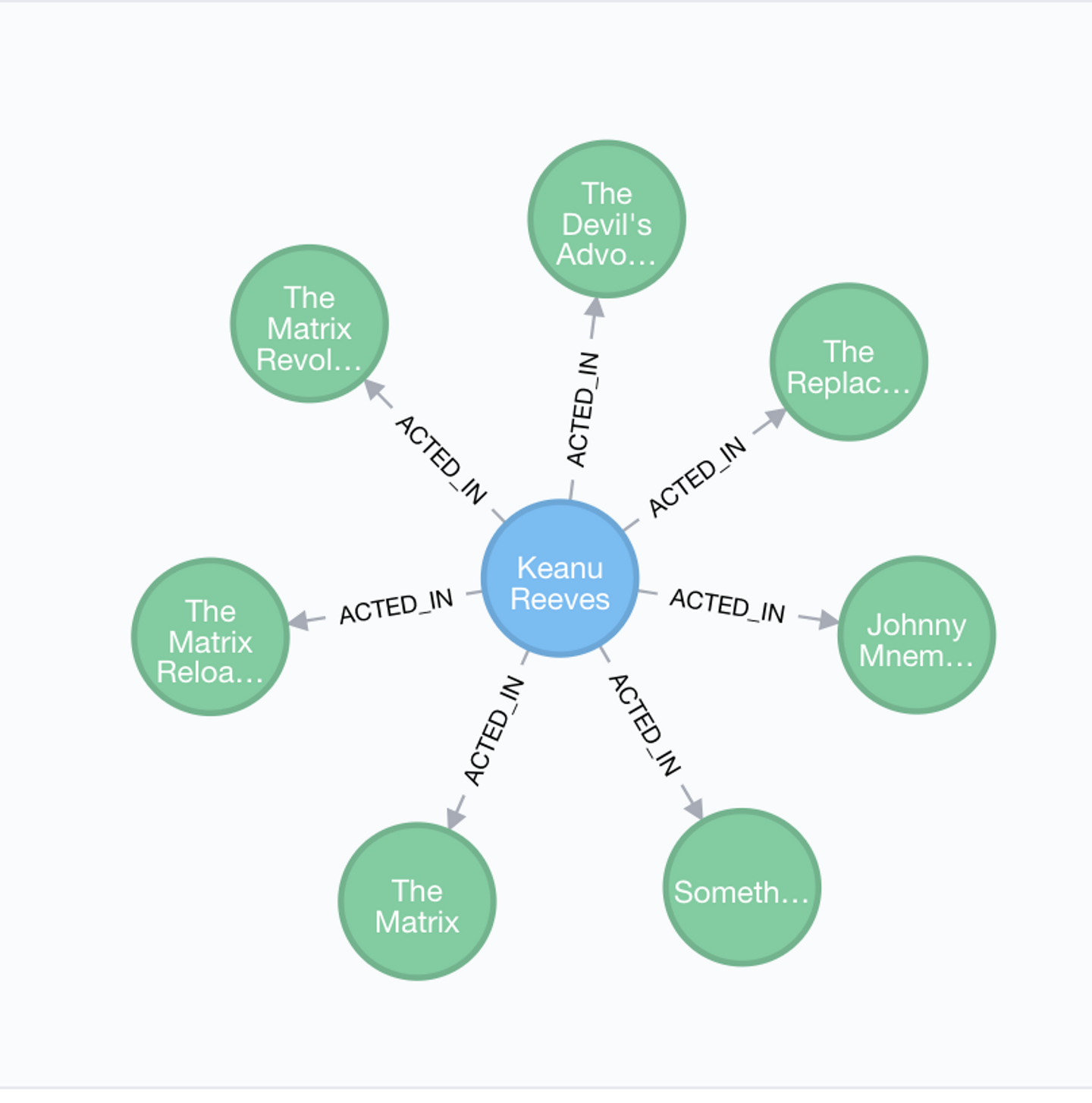
すごいですね。でもこんなクエリしか使わないならRDBでもデータ保持&取り出しできそうです。
キアヌリーブスとトムクルーズをつなぐ最も短いパスを表示するクエリはこちら。
match (keanu: Person { name: "Keanu Reeves" }), (tom: Person {name: "Tom Cruise" }),
path=allShortestPaths((keanu)-[*]-(tom))
return keanu, tom, path;
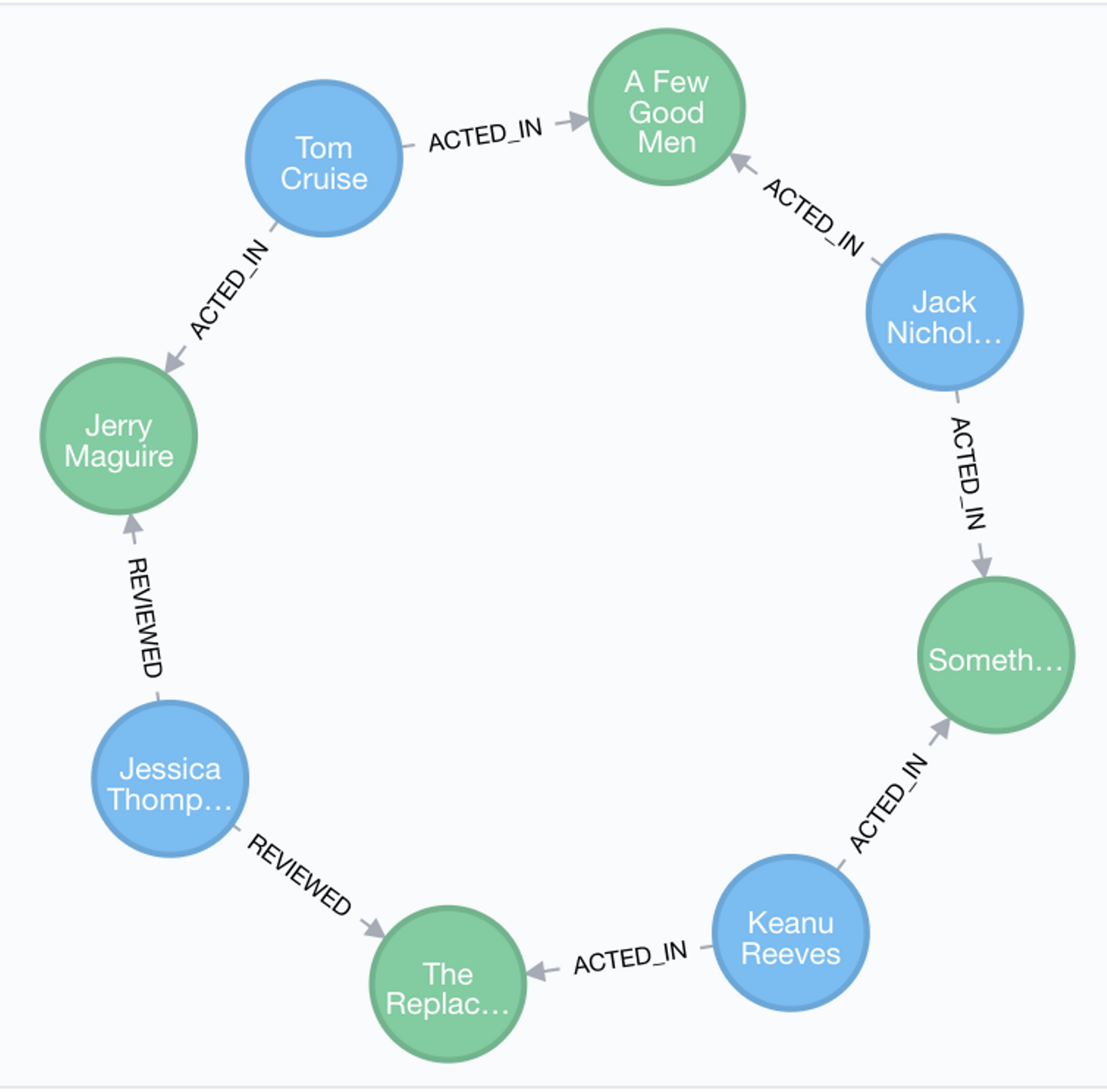
ここまで来ると普通のSQLでは抜いて来るのは大変そうです。
これで少しお勉強して見たいと思います。
ちなみにneo4jを商用利用する場合は、AGPLv3ライセンスに基づき全てのソースコードを公開する必要があるようなので注意が必要。商用ライセンスで利用する必要があります。もちろんソース公開してもいいぜ!というサービス開発者は商用ライセンスなしに使えます。

/assets/images/121522/original/2a94a436-59c2-46d8-833d-088fe9f73f3d.jpeg?1429980824)
/assets/images/121522/original/2a94a436-59c2-46d8-833d-088fe9f73f3d.jpeg?1429980824)


