
GPT-4o は、OpenAIの人気のある大型マルチモーダルモデルGPT-4の3番目の主要なバージョンです。これは、GPT-4 with Visionの機能を拡張しています。新しくリリースされたモデルは、ChatGPTインターフェースを使用する場合、以前のバージョンよりもユーザーとシームレスに会話したり、視覚的な情報を理解したり、対話したりすることができるようになります。
GPT-4o の発表では、OpenAIはこのモデルが「より自然な人間とコンピュータの相互作用」を実現することに焦点を当てています。この記事では、GPT-4o とは何か、以前のモデルとの違い、性能評価、GPT-4o の活用事例について説明します。
- GPT-4o とは何ですか?
- GPT-4o の新機能とは?
- GPT-4o のテキスト評価
- GPT-4o のビデオ機能
- GPT-4o の音声機能
- GPT-4o の画像生成
- GPT-4o の視覚的な理解
- GPT-4o の活用事例
- GPT-4o へのアクセス
- まとめ
GPT-4o とは何ですか?
GPT-4o はOpenAIによって開発されたモデルです。GPT-4o は、2024年5月13日のライブストリームで発表され、デモンストレーションも行われました。「o」はomni(「すべての」または「普遍的な」という意味)を表しています。このモデルは、テキスト、ビジュアル、オーディオの入出力機能を持つマルチモーダルモデルであり、OpenAIのGPT-4 Turboを基にしています。GPT-4o は、複数のモダリティを扱うことができる単一のモデルであり、そのため非常に強力で高速な性能を発揮することができます。これにより、以前のGPT-4のバージョンよりも断片的な体験を生み出すことなく、異なるタスクに対応することができます。
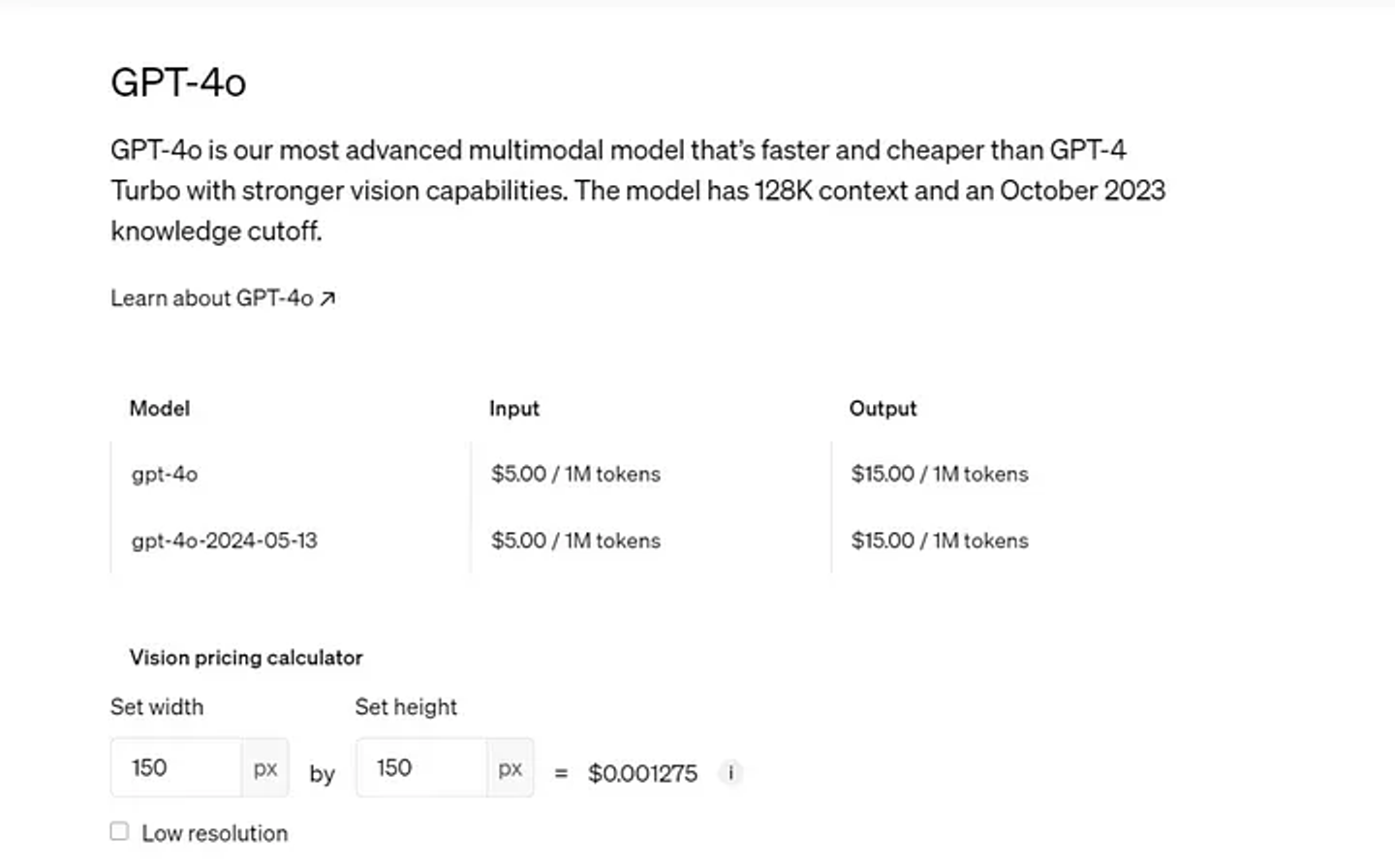
OpenAIは、GPT-4oがGPT-4Tと比較して2倍のスピードで動作し、入力トークン(100万個あたり500ドル)と出力トークン(100万個あたり1,500ドル)の両方で50%安くなり、レート制限が5倍(1分あたり最大1,000万トークン)になると主張しています。GPT-4oは128kのコンテキストウィンドウを持ち、2023年10月までナレッジカットオフが設定されています。一部の新機能は、現在、オンラインでChatGPTを通じて、またデスクトップとモバイルデバイスのChatGPTアプリを通じて、OpenAI APIを介して利用可能です。また、Microsoft Azureを通じても利用することができます。
GPT-4oは、テキスト、視覚、音声を含む能力を向上させる、GPT-4レベルの知能を提供しています。
OpenAIのCTOのミラ・ムラティ氏
GPT-4o の新機能とは?
GPT-4oのリリース・デモでは、視覚と音声の機能しか紹介されていませんでした。しかし、リリース・ブログには、これまでのGPT-4の機能をはるかに超える例が掲載されています。GPT-4oは、以前のリリースと同様に、テキストと視覚の機能を備えていますが、ビデオを含む、サポートされているすべてのモダリティをネイティブに理解し、生成する機能も備えています。
サム・アルトマンは個人ブログで指摘していますが、最もエキサイティングな進歩はモデルのスピードです。特に、モデルが音声でコミュニケーションしているときのスピードに注目されます。応答遅延はほぼゼロになり、GPT-4oとの対話は人との日常会話と同じように行えます。
GPT-4 with Visionがリリースされてから1年足らずで、OpenAIはパフォーマンスとスピードの面で、見逃せない有意義な進歩を遂げました。
さっそく始めましょう!
GPT-4o のテキスト評価
OpenAIが独自に発表したベンチマーク結果によると、GPT-4oは以前のGPT-4、AnthropicのClaude 3 Opus、GoogleのGemini、MetaのLlama3と比較して、テキストに関しては若干改善したか、同等のスコアを示しています。
なお、提供されたテキスト評価のベンチマーク結果では、OpenAIはMetaのLlama3の400bバリアントと比較しています。公表時点では、Metaは400bバリアントモデルのトレーニングを終えていません。
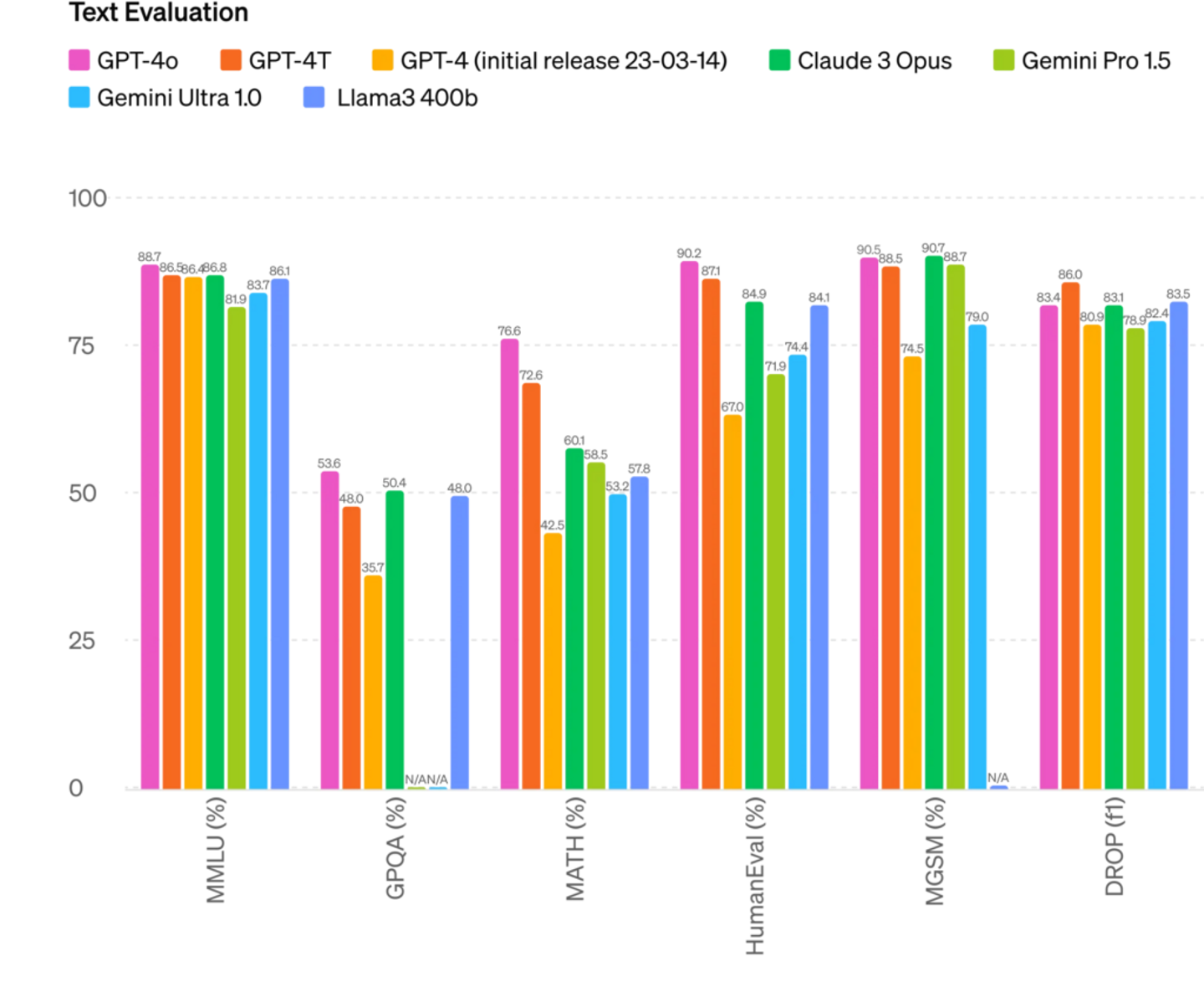
画像出典:OpenAI
言語のトークン化
これらの20の言語は、異なる言語ファミリーにまたがる新しいトークナイザーの例として選ばれました。日本語も含まれています。
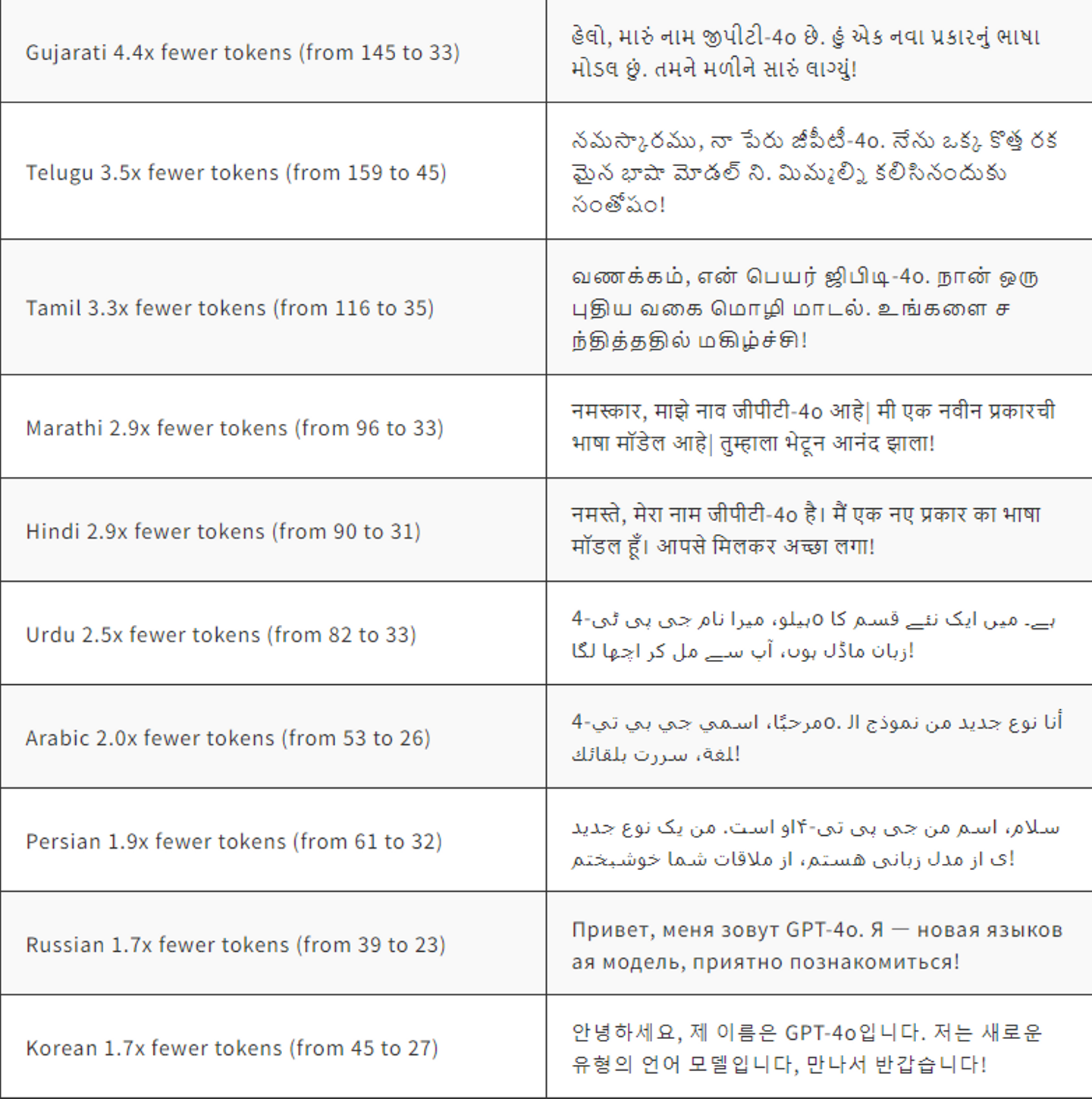
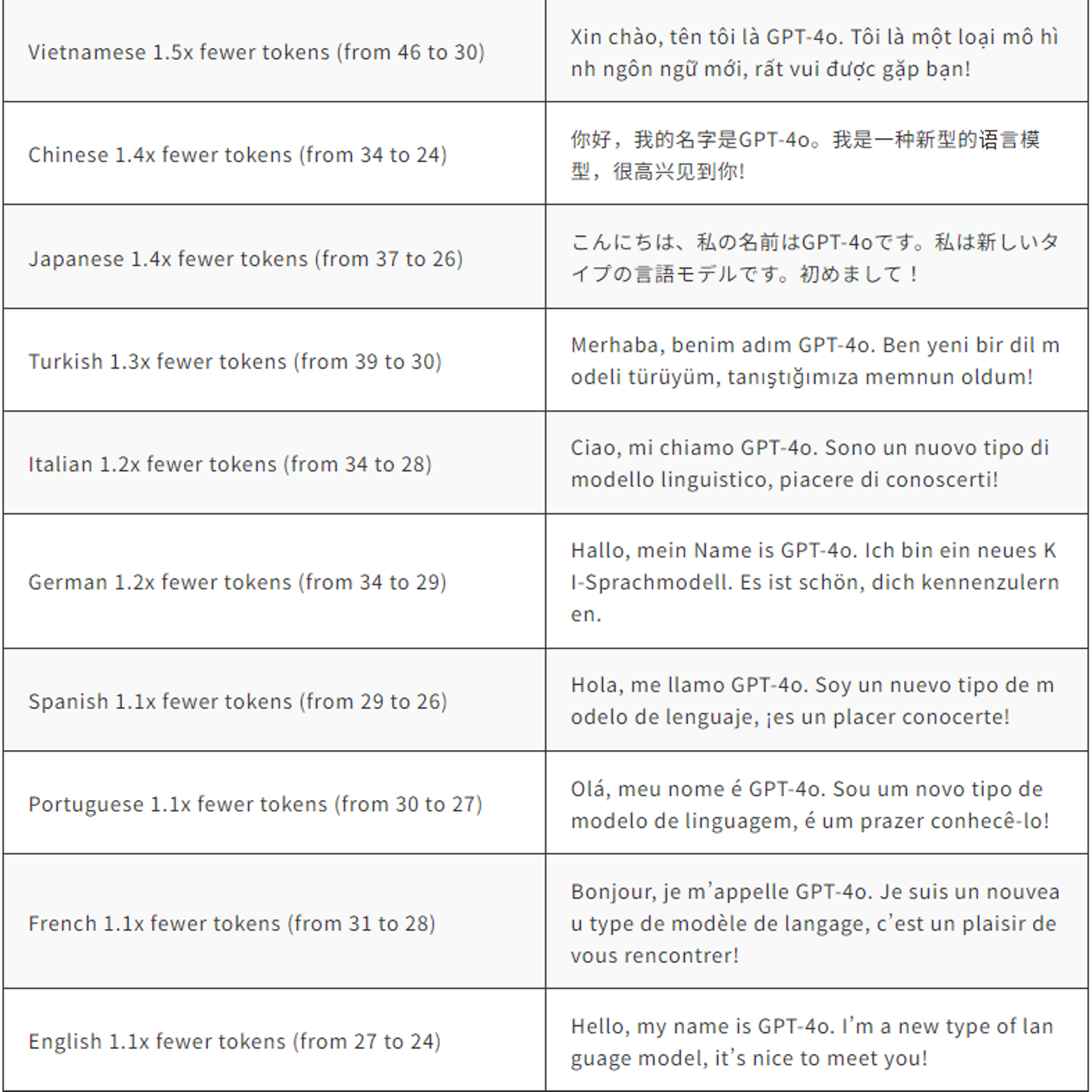
出典:OpenAI
GPT-4o のビデオ機能
APIリリースノートから、ビデオでの使用に関する重要な注意事項を引用します:
「APIにおけるGPT-4oは、視覚機能によってビデオ(音声なし)を理解することをサポートしています。具体的には、動画はモデルに入力するためにフレームに変換される必要があります。(2-4フレーム/秒、均一にサンプリングされるか、キーフレーム選択アルゴリズムを介して)」
ビデオを入力として使用する方法とリリースの制限をよりよく理解するために、ビジョンのためのOpenAI Cook Bookを使用してください。
GPT-4oは、アップロードされたビデオファイルからビデオとオーディオを表示し理解する能力と、短いビデオを生成する能力の両方を持つことが実証されています。
最初のデモでは、GPT-4oが視覚的な要素にコメントしたり反応したりする場面が多く見られました。しかし、Geminiの最初の観察と同様に、モデルがリアルタイム情報を「見ている」ときに、ビデオを受信しているのか、画像をキャプチャしているのかが明確ではありませんでした。特に、最初のデモでは、GPT-4oが画像をキャプチャしていなかったため、以前にキャプチャされた画像を見ていた可能性があります。
YouTubeにアップされているこのデモビデオでは、GPT-4oがグレッグ・ブロックマンの背後でウサギの耳を作っている人物に「気づいています」。目に見える携帯電話の画面には、効果音と共に「まばたき」のアニメーションが表示されています。これは、GPT-4oがGeminiと同様のアプローチをビデオに対しても使用している可能性を示唆しており、ビデオの抽出された画像フレームと音声が処理されていることを意味します。

これは、GPT-4oによる「まばたき」するアニメーションのデモビデオの一部を切り取ったものです。
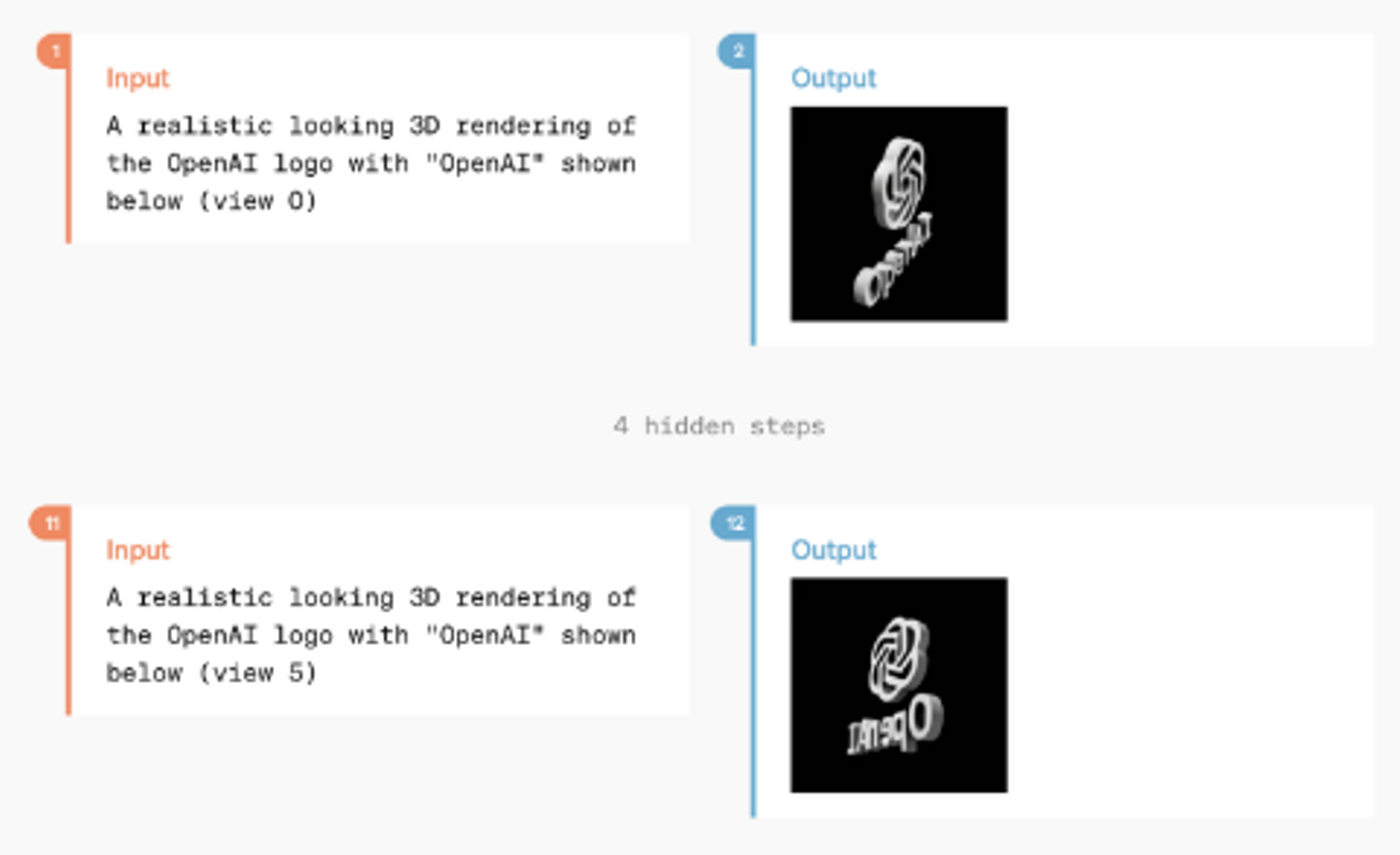
動画生成のデモは、3Dモデルの動画再構成に限定されていますが、これによってより複雑な動画を生成する能力があるかもしれないと推測されています。
GPT-4o の音声機能
GPT-4oは、ビデオや画像と同様に、音声ファイルの処理と生成が可能です。
このモデルでは、生成される音声の微調整が可能であり、通信速度の変更や音色の変更、さらには歌唱など、リクエストに応じた要素を追加することができます。GPT-4oは出力の制御だけでなく、入力された音声を理解する能力も備えており、追加のコンテキストを持ったリクエストにも対応できます。デモでは、GPT-4oが中国語を話す人に対して音色のフィードバックを行ったり、呼吸訓練中の人の息の速さに対するフィードバックを行ったりしています。
公表されたベンチマークによると、GPT-4oはOpenAI独自の最先端の自動音声認識(ASR)モデルであるWhisper-v3を超え、さらにMetaやGoogleの他の音声翻訳モデルよりも優れているとされています。
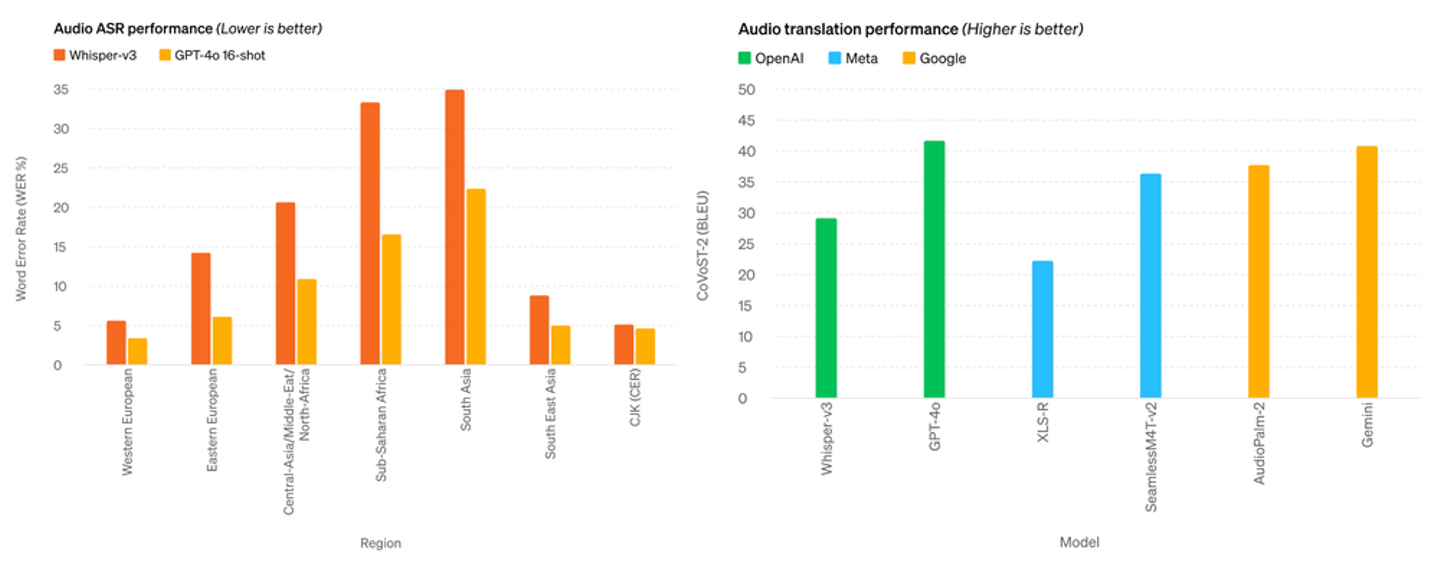
画像出典:OpenAI
GPT-4o の画像生成
GPT-4oは強力な画像生成能力を持ち、ワンショットのリファレンスベースの画像生成や正確なテキスト描写のデモンストレーションが可能です。
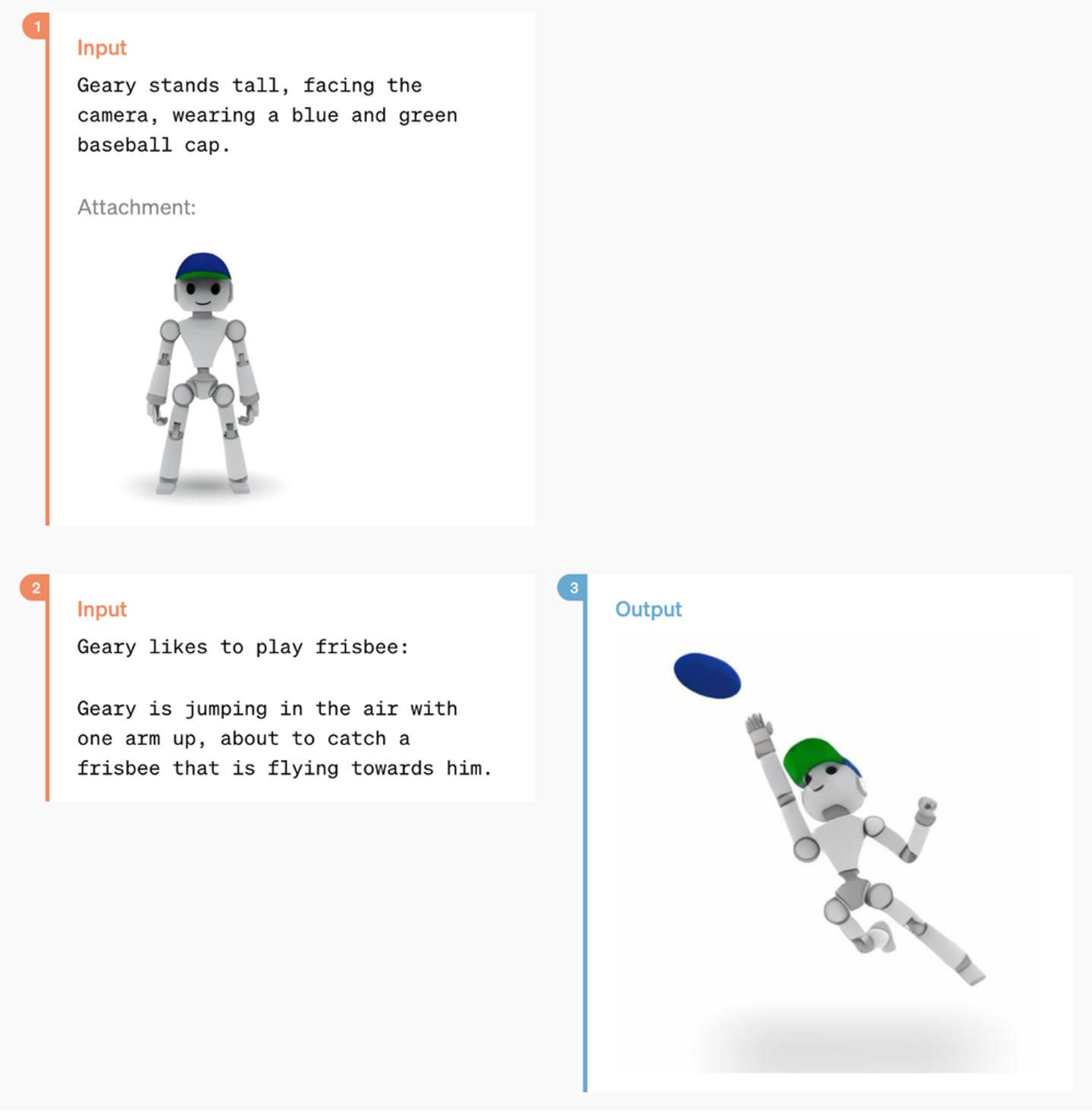
ユーザーとGPT-4oの画像生成のやり取り(画像出典:OpenAI)
以下の画像は、特定の単語を保持し、別のビジュアルデザインに変換するという要求を考慮すると、特に印象的です。このスキルは、GPT-4oのカスタムフォントを作成する能力に合致しています。

様々なプロンプトからのGPT-4oの出力例(画像出典:OpenAI)
GPT-4o の視覚的な理解
GPT-4oはGemini、Claudeに対していくつかの視覚的理解ベンチマークで最先端の技術を実現しています。
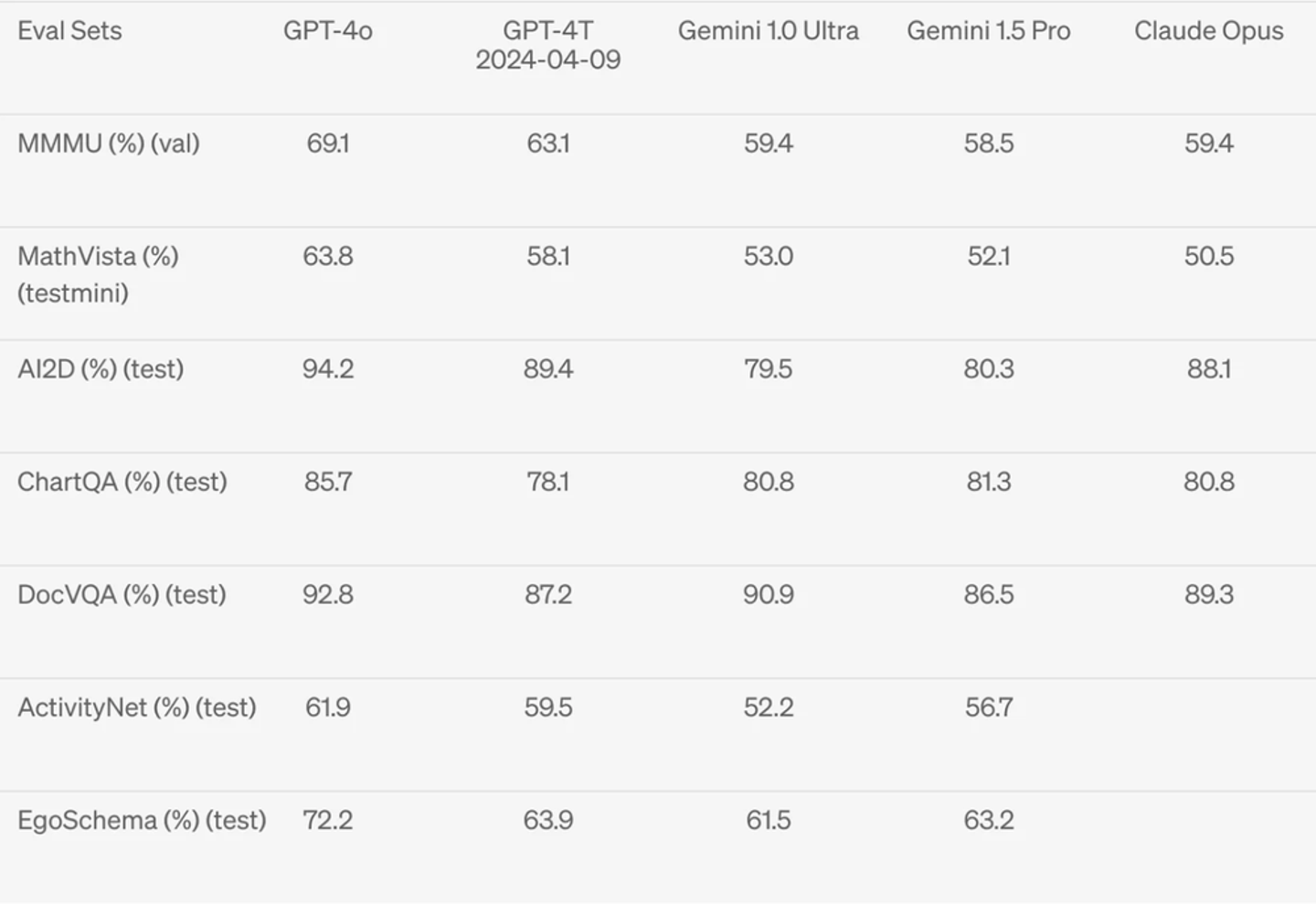
画像出典:OpenAI
GPT-4oのOCR機能はOpenAIによって公開されていませんが、将来的に評価される予定です。
GPT-4o の活用事例
OpenAIはGPT-4の機能を拡張し続け、最終的にGPT-5をリリースするにつれて、活用事例は指数関数的に拡大するでしょう。GPT-4oのリリースにより、画像の分類とタグ付けが非常に簡単になりましたが、OpenAIのオープンソースCLIPモデルも同様の機能をより安価に提供しています。ビジョン機能を追加することで、GPT-4oをコンピュータビジョンパイプラインの他のモデルと組み合わせることが可能になり、オープンソースモデルをGPT-4で補強することで、ビジョンを使用したより完全な機能を備えたカスタムアプリケーションを実現する機会が生まれました。
GPT-4oのいくつかの重要な要素は、以前は不可能だった別の活用事例を切り開くものであり、これらの活用事例はいずれもベンチマークでのモデル性能向上とは関係ありません。サム・アルトマンの個人ブログには、「AIを作り、それを他の人々が使って、我々全員が恩恵を受けるような様々な素晴らしいものを作る」という明確な意図が書かれています。もしOpenAIのゴールがコストを下げ続け、パフォーマンスを向上させることだとしたら、そのゴールはどこにあるのでしょうか?
いくつかの新しい活用事例を考えてみましょう。
リアルタイムコンピュータビジョンの活用事例
新しい高速化技術と映像・音声の同期によって、GPT-4oのリアルタイムでの使用が可能になりました。周囲の世界をリアルタイムで表示し、GPT-4oと会話できるため、迅速に情報を収集し、意思決定ができるようになります。これにより、ナビゲーション、翻訳、案内、複雑な視覚データの理解など、さまざまな用途に役立ちます。
GPT-4oとの対話は、非常に優秀な人間と会話するのと同じくらい迅速です。そのため、テキスト入力にかかる時間が短縮され、AIがあなたのニーズをサポートし、周囲の世界との対話時間を増やすことができます。
たとえば、GPT-4oが文字がたくさん書かれた画像から重要な情報を抽出する能力を評価します。レシートを見せて「私はいくら税金を払いましたか?」と尋ねたり、ピザメニューを見せて「パストラミピザの値段はいくらですか?」と尋ねたりすると、GPT-4oはどちらの質問にも正しく答えます。
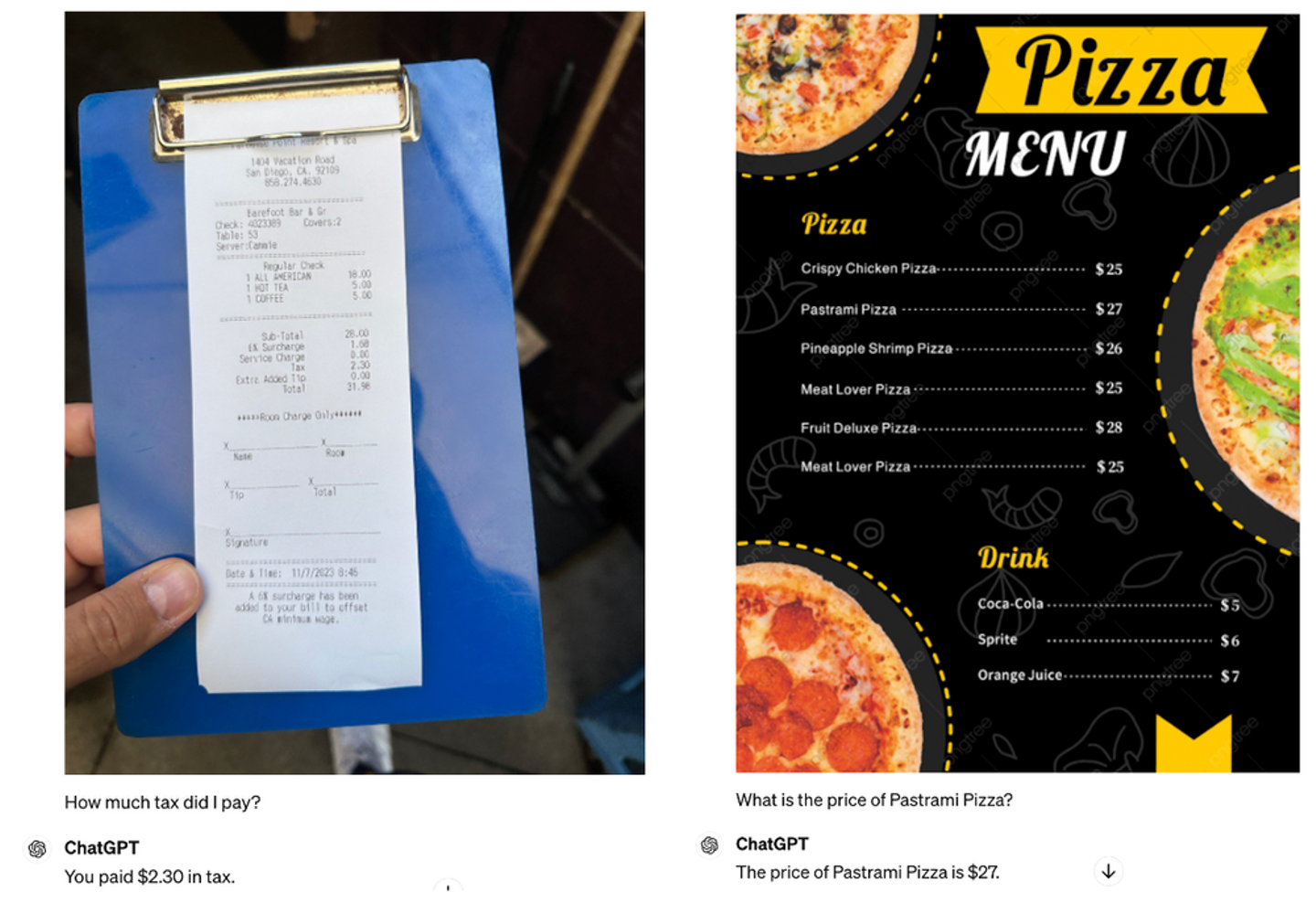
画像出典:RoboFlow
これは、以前のGPT-4 with Visionではレシートから税金を抽出するのに失敗した点からの改善です。
一つのデバイスのマルチモーダル活用事例
GPT-4oをデスクトップやモバイルデバイス(さらに将来的にはApple VisionProのようなウェアラブルデバイス)で使用することで、多くのタスクを1つのインターフェースで解決できます。テキストを入力して回答を求める代わりに、デスクトップ画面を直接表示できます。ChatGPTウィンドウに内容をコピーペーストする代わりに、質問しながら視覚情報も提供できます。これにより、複数の画面やモデル間を切り替える必要が減り、統合された体験が実現します。
GPT-4oのマルチモーダルモデルは、入力方法を簡素化し、速度を向上させ、モデルとの対話をスムーズにします。
企業向け応用全般
GPT-4oは、多様なモダリティを1つのモデルに統合することで、特定の用途に対するパフォーマンスを向上させることができます。これにより、カスタムデータの微調整を必要としない企業向けの応用が可能になります。オープンソースのモデルを使うよりも高価ですが、その分高速なパフォーマンスを提供するため、カスタムビジョンアプリケーションの構築に適しています。
GPT-4oは、オープンソースモデルや微調整されたモデルがまだない場合に利用できます。これにより、複雑なワークフローのプロトタイピングを迅速に開始でき、さまざまなユースケースで柔軟に対応できます。
GPT-4o へのアクセス
GPT-4oへのアクセスは簡単で、さまざまなユーザー層やニーズに合わせたオプションが用意されています。
GPT-4o へのアップグレード
すでにChatGPT PlusまたはTeamにご契約の方は、GPT-4oにアップグレードすることで、より強化された機能をご利用いただけます。
アップグレードの手順は以下の通りです。
1. ページ上部のドロップダウンメニューをクリックします。
2. 利用可能なモデルのリストからGPT-4oを選択します。PlusまたはTeamユーザーとして、無料ティアと比較して、より高いメッセージ上限とより速い応答時間をお楽しみいただけます。
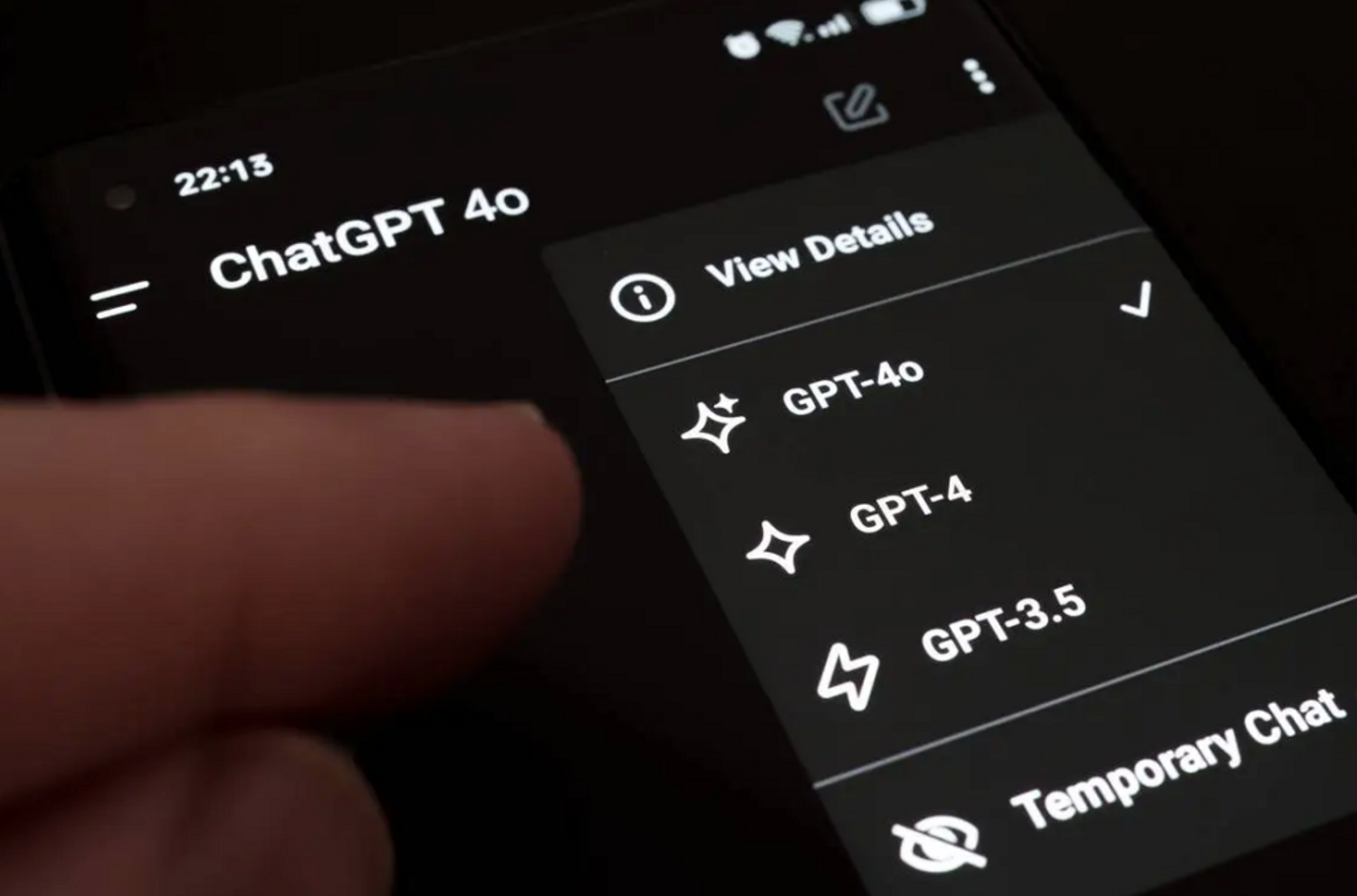
画像出典:RoboFlow
開発者向けGPT-4o API
開発者はAPIを通じてGPT-4oにアクセスすることができます。
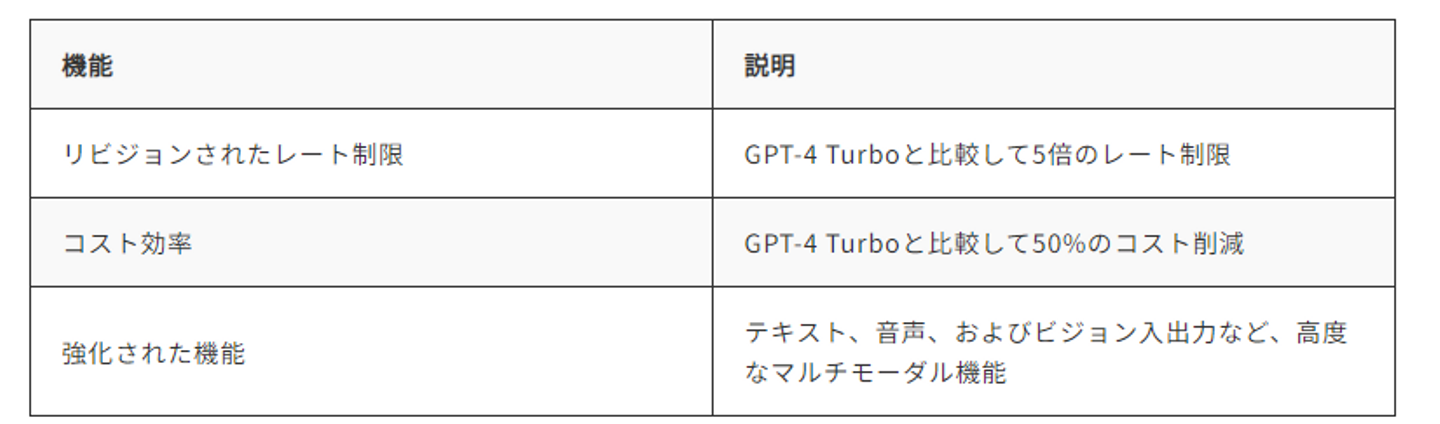
GPT-4oの利用費用が引き下げられました。
以下は、GPT-4o APIを使い始めるための手順です。
1. OpenAIのアカウントにサインアップします。
2. APIキーを取得します。
3. APIドキュメントに従って、GPT-4oをプロジェクトに統合します。
まとめ
GPT-4oの最新の改良点は、2倍の速さ、50%の低価格、5倍のレート制限、128Kのコンテキスト・ウィンドウ、単一のマルチモーダル・モデルです。これはAIアプリケーションを構築する人々にとってエキサイティングな進歩です。AIで解決するのに適したユースケースがますます増えており、複数の入力によってシームレスなインターフェースが可能になります。
より高速なパフォーマンスと画像/ビデオ入力は、GPT-4o がエンタープライズ・アプリケーションを作成するためのカスタム微調整モデルや事前訓練されたオープンソースモデルと並んで、コンピュータ・ビジョンのワークフローで使用できることを意味します。
ChatGPTの大躍進により、テックジャイアント間でのAI競争が加速し、多くの企業内でもこれまで以上に新たな技術に対する迅速な対応姿勢が強く問われています。

/assets/images/7203977/original/591ad233-7d6b-4ce9-a6bc-19b3912ee5ce?1626396008)
/assets/images/7203977/original/591ad233-7d6b-4ce9-a6bc-19b3912ee5ce?1626396008)


