/assets/images/3156150/original/c11f8a92-dd62-4530-87a0-2dfede136d16?1539566834)

ログリー株式会社's job postings
はじめに
こんにちは!LOGLY 開発グループでサーバサイド開発を担当している細野です。
日々主にRuby on Railsや Perl を用いた開発を行っていますが、昨年末あたりから4月までインフラ周りをメインで担当していたため、最近はTerraformやYAMLの記述量が多めになっています。
また昨年子供ができ、子育てに忙しい毎日を送っています。その中でいかにテクノロジーのキャッチアップを行うか、時間の効率的な使い方を絶賛模索中です。
2020年1月〜3月にかけて、当社開発チームメンバー6人で新バッチシステムを構築しました。
そこでせっかくの機会なので、今回は現状の課題と、課題を踏まえた新システムの技術選定過程をまとめました。
長くなったら申し訳ありませんが、お付き合いいただければ幸いです。
LOGLYバッチのいま
バッチ実行はcronで管理しています(約40件)。
$ crontab -l
3,33 * * * * sh /usr/local/path/to/cron/batch1.sh
23 11 * * 2 sh /usr/local/path/to/cron/batch2.sh
53 11 * * 2 sh /usr/local/path/to/cron/batch3.sh
0 5 * * * perl /usr/local/path/to/cron/batch4.pl
0 5 * * * perl /usr/local/path/to/cron/batch5.pl
0 5 * * * perl /usr/local/path/to/cron/batch6.pl
…
依存関係のあるジョブは一つのcronスクリプト内に収めていて、ジョブ成功通知はスクリプトの最後でファイルに出力しています(print “job succeeded”
など)。失敗の場合は途中でメッセージをファイル出力しその場でジョブを終了します。
また、これらバッチ実行は単一のEC2サーバで管理しています。
いまのバッチの問題点
ビジネス要件が複雑化し、cronやそれを単一サーバで管理するだけでは管理が難しくなったことがリプレイスを検討し始めた大きな要因ですが、ここを起点とした副次的な問題点が無視できなくなっていました。
(今回の取り組みで解消しない部分も一部含まれていますが、あくまで当社バッチの問題点として記載しています。)
- cronで管理している点
- バッチが増え、どのジョブが何をしているのか分からなくなって来た。
- 単体でもジョブが肥大化してきて、バッチの実行時間がどんどん長くなる傾向にあり、ジョブごとの依存関係を表現できないことが辛い。
- ジョブを切り出して時間をずらす手もあるが、いつ依存関係のあるジョブが終わるか厳密に分からないのでずらせない
- タスク成否の可視化、調査用ログ閲覧機構などを作っておらず、ほぼ何も出ていない
- プログラム上で【
batch start
/batch end
】をファイル出力するくらいしか書いていない
- プログラム上で【
- 既存コードが複雑怪奇
- ビジネス要件をどんどん書き足していった結果、読みづらさしかないコードにさらに読みづらいコードを書き足す状況が生まれ、理解を阻んでいる
- 単一サーバでの管理なので、柔軟な構成変更やリソース管理ができていない
- バッチを記述している言語がPerl
- 型安全に処理を記述することができない
- Perlへのメンバー各人の技術資産獲得モチベーションがそこまで高くない
- (これは今回の問題点を超えていますが)広告配信プログラムもPerlで記述されていて、数秒の処理の遅れが収益に影響するWeb広告を扱っているため、並行処理が得意でない言語から脱却し、処理速度の向上を少しでも図りたいという欲求が以前からあった。
これらの管理効率の悪い要素を取り除き、部分的でも良いので負債を解消していきたい、できればバッチをワークフロー管理して依存関係を見える化して通知もいい感じで実装していきたい、という声は前から上がっていたものの、中々既存業務の忙しさに勝てない状況が続き、改善が進んでいませんでした。
改善に向けて
訪れたチャンス
そんな中、2020年、チャンスが訪れます。
- 新機能開発に伴うデータ取込バッチを複数新設する必要が出てきました。
- 新設するバッチは複数存在し、かつどれも既存バッチとの依存関係を考える必要はそこまでない状況。
- バッチをワークフロー化するきっかけをこのプロジェクトで作っちゃおう!
ということで、急転直下、新バッチシステム導入に向けたプロジェクトが始まりました!
バッチシステム構成こうする案を考える
【ワークフロー化】【脱Perl】を軸にバッチのアーキテクチャを考案しました。それぞれの技術採用理由については後述しますが、今回のプロジェクトでは、外部事業者からデータをAPI or S3経由で取り込むバッチを作成するためのアーキテクチャを設計していきました。
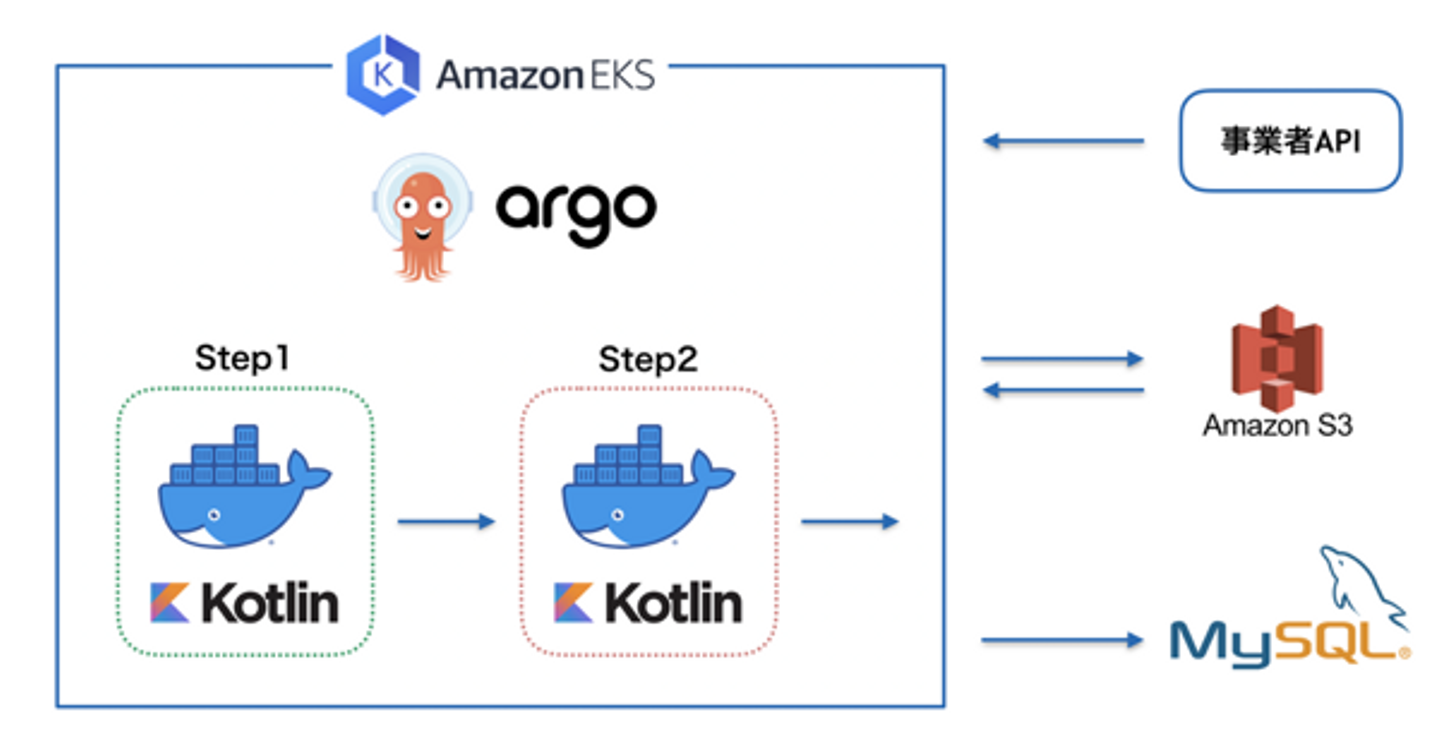
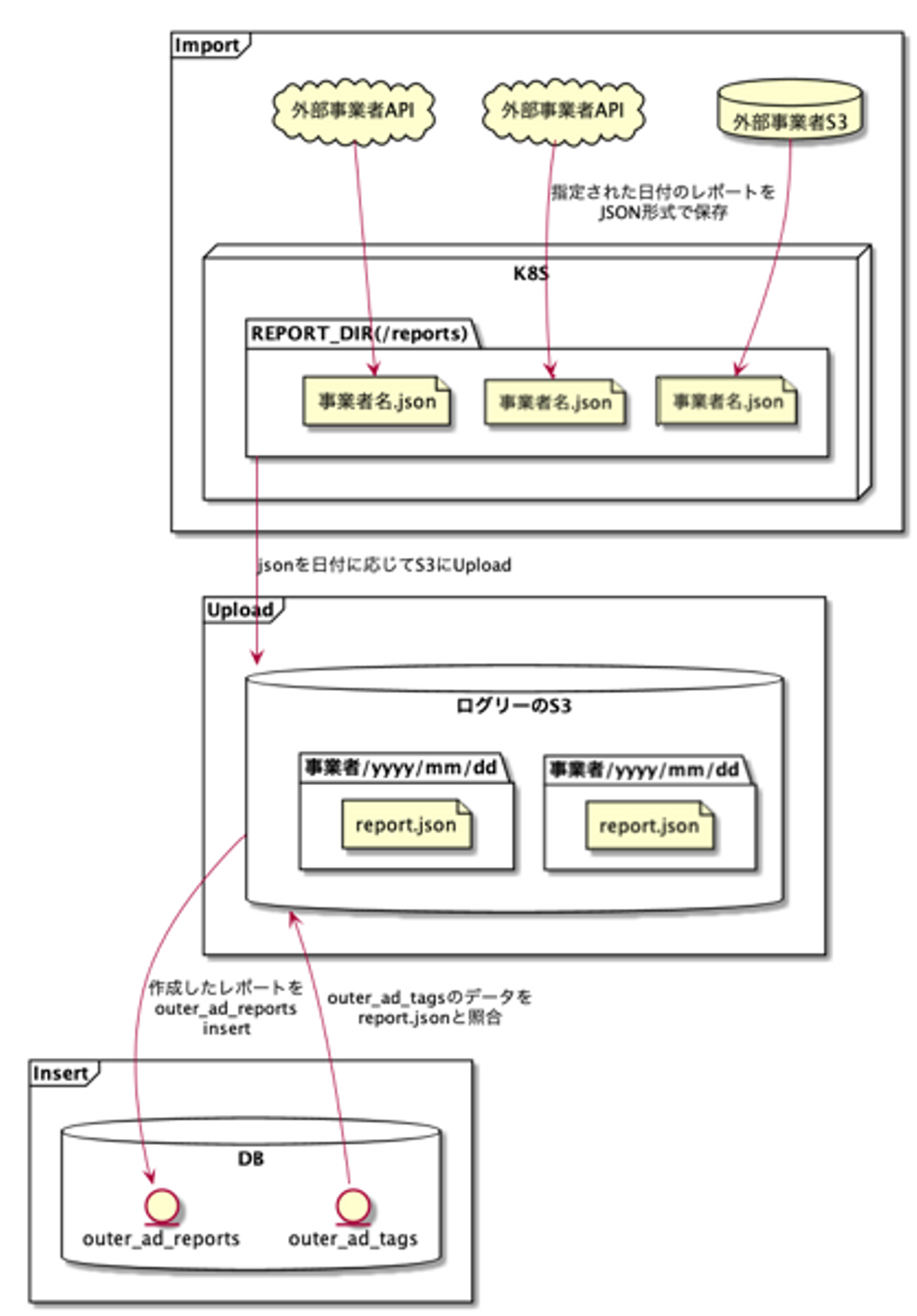
具体的な処理手順は以下の内容になります。
- データ構造が異なる各外部事業者ごとに、データをimportしJSONフォーマットに加工
- importしたデータをバックアップのためAWS S3へupload
- AWS S3へuploadしたデータをDBへinsertする。各タグ情報やレポートの最終取込時刻を管理するouter_ad_tagsテーブルを参照しつつ、outer_ad_reportsテーブルにレポートデータを登録する。取り込んだデータは管理画面での数値確認や請求確認用データとして活用
技術をどう選んでいったか
選定した技術スタックは以下の通りです。
上記で触れた問題点や負債を解消できるような構成にしました。
項目内容Tipsバッチ処理Kotlin設計にクリーンアーキテクチャを採用することで既存システムの負債に対抗 & 静的型付け言語による開発の効率化ワークフローArgoKubernetesとの相性がよく採用。ジョブ依存関係が表現され、タスク成否が可視化されるストレージAWS S3開発用にはMinioを使用インフラKubernetes複数コンテナをよろしく管理してくれ、複数サーバでのバッチ管理を実現してくれる & 当社インフラが全体的にKubernetesに移行中であり整合性を取れる
それぞれ(S3以外)の検討事項を簡単に書いていきます。
言語とクリーンアーキテクチャ
言語
問題点でも挙げた通り、処理速度を改善したいこと、また開発時の負荷を少しでも軽減したいこと(TypeErrorを防ぐ、Null safetyにするなど)といったニーズを踏まえ、静的言語を選ぼうという合意までは簡単に至りました。
LOGLYでは主要言語の一つとしてRuby(Ruby on Rails)を採用しているため、例外的にRuby on Railsだけ最後の方まで争いましたが、動的言語に変わりは無いことや技術的な挑戦を優先したいというメンバーの意向から、最終的に候補から除外しました。
静的言語では技術トレンドもあって、Go, Kotlin, TypeScriptが最終候補にあがりました。
- どれも会社として使ったことがないという点で差がない状態。正直悩みました。
- 【書きやすさ】【モチベーション】【コード量】【パフォーマンス】【インフラの運用のしやすさ】を軸にスコア付けして比較した結果、最終的にはサーバーサイドKotlinを採用しました!
細かな部分だと、KotlinだったらJavaの資産が利用できることや実行速度が十分に高速というメリットがあったり、Goであればビルドすれば管理が楽でかつシンプルな文法で学習コストが低かったり、TypeSctiptであればJavaScript慣れしていれば書きやすかったりとそれぞれメリットがありとても悩みましたが、最後はスコアとメンバーの「サーバーサイドKotlinやりたい」欲で決めました。
Kotlinライブラリ
こだわった部分の一つは、Pure Kotlinを貫くことでした。なるべくKotlinのみで書きたかったのでPure Kotlinのライブラリがあれば優先していました。あとはGitHubのスター数やクリーンアーキテクチャを考慮したり、書き心地の良し悪しで選んで行きました。
最終的にKotlin ライブラリは以下を選定しました。
ライブラリ目的選定理由cliktCLI ParserOkHttpHTTP ClientFuel と比較してインターフェイスが良かった、moshi と相性が良さそう(square 製、Okio 使用)koinDependency InjectionDIに特化したライブラリでクリーンアーキテクチャに欠かせない存在moshiJSON Parsergson と比較して Kotlin への対応が良かったExposedKotlin製DB ClientApache CommonsJava Util系mockkmock & spyライブラリmockito (mockito-kotlin) と比較して Kotlin への対応や文法が良かったspekRspec風な記述が可能AssertJ名前の通りアサーションの強化版
クリーンアーキテクチャ
またぐちゃぐちゃコード脱却のためクリーンアーキテクチャを採用しました。
クリーンアーキテクチャはDBやフレークワークからの独立性を確保するためのアーキテクチャで、以下の図で有名です。(原典より https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html)
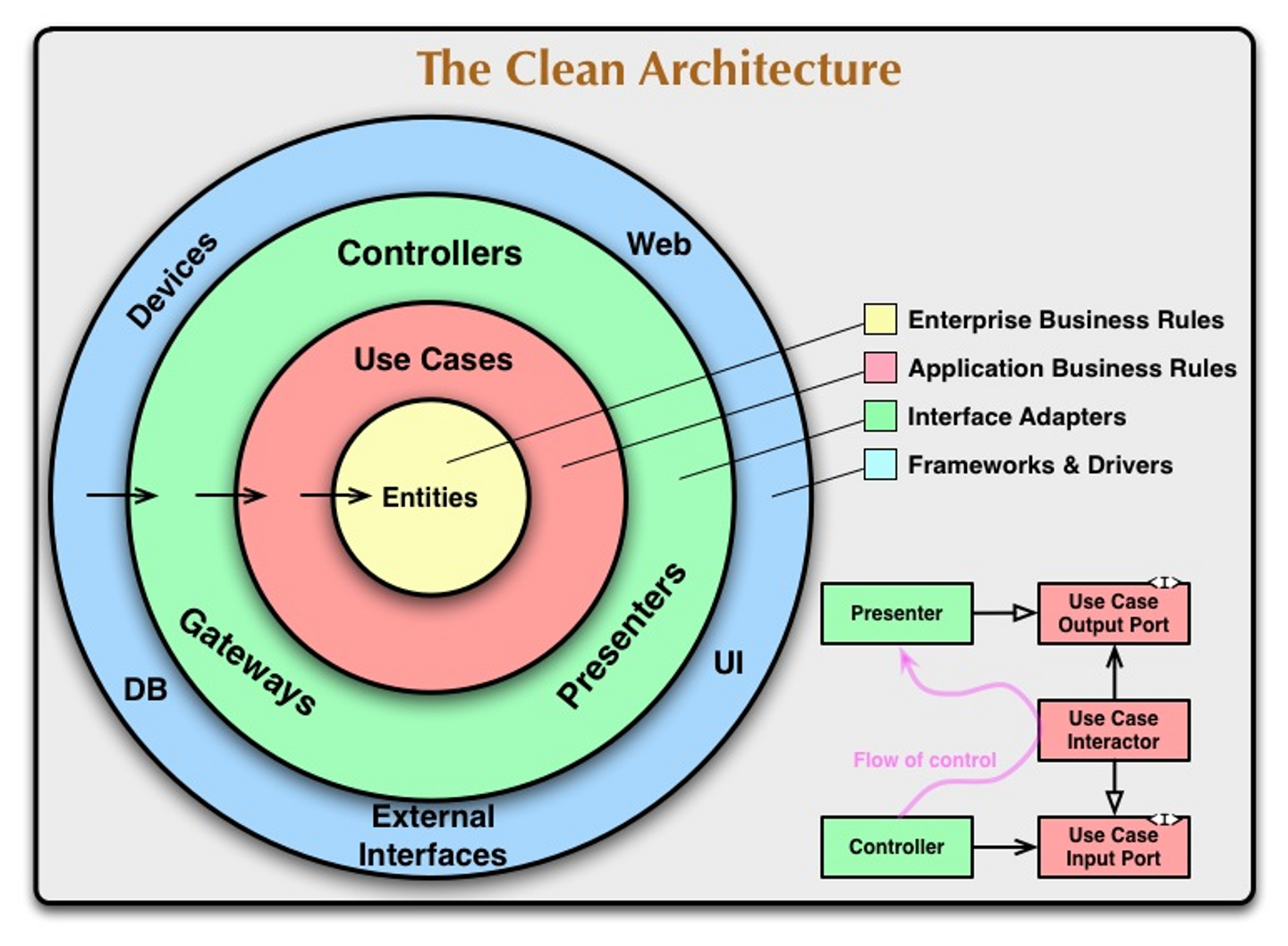
上記のクリーンアーキテクチャを、作成したバッチに以下のように当てはめてみました。
今回の説明に不要なディレクトリは端折っていますが、当社として初めてのクリーンアーキテクチャ導入だったこともあり、ディレクトリ名には図で示されている名称をなるべく使用し、どこで何の責務を担っているか、わかりやすい構成に仕上げるよう工夫しました。
├── adapter…Interface Adapters
│├── controller…APIやS3からの取り込みデータをUseCaseに伝えるため変換
││└── ReportCommand.kt
│├── dataaccess…DBと接続しデータを取得
││└── ReportDAO.kt
│└── repository…取り込みデータの保存先とのやりとりを抽象化
│└── ReportRepository.kt
├── application
│├── input…UseCasesの引数となるもの。各レポート処理でcontrollerから渡された値を引数として受け取る。
││├── ReportImportInputData.kt
││├── ReportInsertInputData.kt
││└── ReportUploadInputData.kt
│├── interactor…UseCasesの実装部分。inputで受け取った引数の値をEntityで定義されたデータモデルの形に変形しcreate/update処理を呼び出す(inputとoutputとを結びつける)。
││├── ReportImportInteractor.kt
││├── ReportInsertInteractor.kt
││└── ReportUploadInteractor.kt
│└── usecase…UseCaseインターフェースの実装。interactorディレクトリからオーバーライドされる。
│ ├── ReportImportUsecase.kt
│ ├── ReportInsertUsecase.kt
│ └── ReportUploadUsecase.kt
├── drivers…レポートAPIやS3との接続部分。
│├── external
││└── ReportApi.kt
│└── storage
│ ├── StorageService.kt
│ └── StorageServiceImpl.kt
├── entity…主にレポート処理で使用するデータと型を定義。
│└── model
│ └── Report.kt
└── utility…レイヤーに関わらず使用したいメソッドを定義(小数処理、日付処理など)。
ワークフローエンジン
cronで管理しきれないジョブ依存関係の表現、タスク成否可視化、cronではできなかったリトライ機能実装のためワークフローエンジンを導入することに。
ワークフロー導入に際しては、コンテナによる実行が手軽に出来ること、出来るだけ手軽に導入 / 運用出来ること、などを軸に、代表的なワークフローエンジン(Airflow, Digdag, Argo)3つの中で検討を開始しました。
検討開始当初(1月あたり)はこんな感じで考えていました。
ワークフローエンジンメリットデメリット選びたいかAirflowPythonでジョブの依存関係を表現するので学習コスト低そうPythonで管理するシステムがLOGLYになくKotlinに加え管理する言語を増やすべきか/簡素なものでもプログラミングが必要になるので若干手間感△ – ×Digdagジョブスケジューリング機能が充実してそう/当社別サービスで導入した実績ありフルマネージドでない/Kubernetesとの相性がよくない/Pythonで管理するシステムがLOGLYになくKotlinに加え管理する言語を増やすべきか△ArgoKubernetesネイティブでインフラ側との相性がいい/ワークフローを宣言的に記述出来るCronWorkflowがなく、ジョブスケジューリングを他で管理する必要がある△ – ○
上記の通り、1月時点ではArgo面白そうだけど、CronWorkflow(Argo単体でスケジューリングされたジョブを実行する機能で、KubernetesのCronJobのすべてのオプションをサポート) がまだリリース予定段階で日本での実績も多くなかったことから、Argoを諦めマイクロサービスで導入実績のあるDigdagで管理するか、もしくはArgo使ってKubernetesのCronJobリソースを使うか、など考えていました。Airflowはプログラミングが必要になることや導入実績もないことから3つの中では及び腰状態でした。また Digdagについても、Kubernetesのジョブを管理するためにひと工夫必要だった、という声もあり、何かしらのデメリットをどう克服するかの悩みがありました。
そんな折に、Argoリポジトリ(https://github.com/argoproj/argo/pull/1758) でCronWorkflowが出たことで、上記の懸念が払拭されたこと、また必要な機能は後からついてくるだろうという若干先走った感じでArgoを採用しました。
絶賛開発中のプロジェクトではありますが、Argo CI 、Argo CDなど魅力的なプロジェクトが複数あり、新規開発でありダメだったら比較的すぐに方針転換、といったモチベーションでできたこともArgo挑戦への後押しになりました。
また記事の分量の関係で今回は詳細は触れませんが、CDにはArgo CDを採用しました。
インフラ
全体感
Kubernetes(EKS) を使用しました。
Kubernetes を使うことでのメリットは Kouさんのスライド(https://speakerdeck.com/kkoudev/introduction-to-kubernetes-for-docker-compose-user) や @MahoTanakaさんの記事(https://qiita.com/MahoTakara/items/39ed37449e6f0f8f65a7) にわかりやすくまとめられている通りなのですが、今回作成したバッチインフラだけではなく、当社のインフラがKubernetesに移行中であったため、そちらに揃える形で採用しました。
インフラ設定は全てTerraformで構築しています。Kubernetesのnamespace設定や role と service account との紐付け、各種AWSリソース管理、次で触れるDatadog管理など、今回のインフラ構成に必要な要素を一元的に管理でき運用面でとても楽なこと、また当社の他インフラリソース管理もTerraformに移行していたことから、異論なく採用が決定しました。
監視
監視には Datadogを新規採用することに。元々Zabbixを使っていましたが、既存の設定がカオスになっていたり、画面から設定する項目も多く管理が面倒なこと、またLOGLYのインフラがコンテナ化された環境であり、現在の環境により適した監視ソリューションを選択する必要がありました。
最終候補としてDatadogとPrometheusが残りましたが、Prometheusサーバ自体を管理するのが若干手間になりそう、というのが主な理由でDatadogに決めました。
やってみてどうだった?
所感
アプリ側で技術的負債に向き合って大きく変えていこう、とメンバー全員が合意し実際に取り組んだことは当社アプリチーム初の出来事で、プロジェクトが終わったときは感無量の一言でした。
また負債を確実に解消しつつ「技術的な挑戦意欲を削がない構成にしよう」という意思がメンバー間で統一されていたことで、ゼロベースで技術をフラットに比較し、当社にとってのベストな技術構成を取れたのだと思います。
結果として、「新規開発を3ヶ月弱という期間でスピーディーにリリース」という実績をチームで作ることができ、チームとしてのキャパシティも大きくなったのではないかなと感じています。
難しかったこと
タスクアサイン
技術資産獲得モチベーションが高いメンバーが多く、「誰がどこを担当するか」を決めるのに1週間くらいかかった記憶があります笑。困難を困難と感じずにどんどん前に進める馬力が備わったメンバーが多いからこその悩みだったかもしれません。
学習コスト
筆者はインフラ構築を担当したのですが、Kubernetes, Terraform, Datadogなど初めてのことだらけでスケジュールについていくだけで精一杯でした。SREチームにアドバイスいただきながらなんとか構築にたどり着いたのですが、そばに聞ける人がいなかったら文字通り死んでいた気がします。今回は良かったですが、技術選択の際、スケジュール如何では「今選ぼうとしている技術に少しでも精通した人がいるか」を軸の一つにおいても良いかもしれません。
初回リリース
複数人で分担して進める案件あるあるですが、E2Eの動作試験で例に漏れず一つ一つこけながら前に進んで行きました。「S3へのアクセス権限のつけ方が違う」「ライブラリのバージョンを上げないと問題が解決しない」「AWS KMSに登録しているキーの値が違う」など挙げればキリがありませんが、改修含め1週間弱かかってようやく疎通に成功しました。慣れていないこともありましたが工数を2日くらいで見積もっており、精度の甘さが出てしまいました。
今度どうするのか
今は新旧バッチシステムが共存している状態なので、まず全てのバッチを新システムに置き換えることが目標です。
その先ですが、利用するコンピューターリソースやDocker Imageを柔軟に変更できることを活かし、機械学習システム構築やその他新システム構築にも利用できそうであればしていきたいと思います。
また、今回使用した技術に変わる良いものが出てきたときは、積極的に検討し必要があれば入れ替えなども行っていこうと思っています。
Appendix
ブログ作成にあたり参考とさせていただいた記事をまとめておきます。ありがとうございました!
https://speakerdeck.com/kkoudev/introduction-to-kubernetes-for-docker-compose-user (Kou さん)
https://qiita.com/MahoTakara/items/39ed37449e6f0f8f65a7 (@MahoTanaka さん)
https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html (Robert C. Martin)
バッチシステム刷新にあたって技術選定をLOGLYはどう行ったのか

/assets/images/3156150/original/c11f8a92-dd62-4530-87a0-2dfede136d16?1539566834)

/assets/images/3156150/original/c11f8a92-dd62-4530-87a0-2dfede136d16?1539566834)
