目次
2019年にリリース、急成長を遂げるWINTICKET
プロフィール
1. WINTICKETデータチームが挑む、SQL研修でも解決できなかった「データの俗人化」
2. 自律型AI『Devin』がもたらした衝撃。導入の裏側に潜む、メタデータ整備の1年。
3. 「データ民主化の終着点」を迎えて、AI共生時代のビジョンとは?
採用情報:WINTICKETでは、データエンジニア・データサイエンティストを募集しています
2019年にリリース、急成長を遂げるWINTICKET
![]()
「競輪を若者の新たなエンタメへ」を中期にかけてのビジョンとし、急速な成長を続けるWINTICKET。(サイバーエージェントの連結子会社 株式会社WinTicketが提供する競輪・オートレースのインターネット投票サービス)
2019年のリリース以来、急成長を遂げ現在は競輪業界No.1(※)として業界を牽引する立場となりました。レース結果・オッズ・車券の販売状況といったドメインデータに加え、アプリ内でのユーザーログデータなど、数億レコード以上のビッグデータを扱いながら、AIを用いたレース予想機能の提供などを行っています。※ 2023年10月~12月の勝者投票券売上実績。(自社調べ)
WINTICKETではビッグデータを武器に、誰もが自在にデータを扱える組織を目指し、SQL研修を実施。しかしSQLが書けるようになってもドメイン知識の属人化への壁は残り、データ抽出に関する問い合わせを根本的に減らすには至りませんでした。
そこで自律型AIエージェント Devin を活用した分析エージェントを導入し、月100件以上の分析依頼を自動化で完遂させることに成功。AIと人間が共生する「データ民主化の終着点」についてお話します。
プロフィール
![]()
山田 瑠奈(データエンジニア): 2021年新卒入社。Amebaブログのレコメンドシステム改善等を経て、2023年にWINTICKETへ異動。現在はにWINTICKETにて、データ分析基盤の構築・運用を担当。
郭 恩孚(データサイエンティスト): 2023年新卒入社のDS。新卒入社後、WINTICKETのデータチームに配属。新規ユーザー獲得効率化・視聴体験改善などを目指したビジネスインパクトに直結する分析を得意とし、AIを用いたレース予想機能の開発を担当。
1. WINTICKETデータチームが挑む、SQL研修でも解決できなかった「データの俗人化」
―WINTICKETデータチームのメンバー構成を教えてください。
山田:データチームは現在DS6名、DE2名、ML(機械学習エンジニア)2名の計10名のチームで、チームの半分が入社3年以内の若手です。私は2023年にWINTICKETへ異動し、当初マーケティング領域の分析業務を担当していました。分析業務に携わっていくなかで、まずは根本的にデータを整備する必要性を感じるようになり、2024年4月にDEにジョブチェンジしました。
―DSとDEは普段どのように連携をしていますか?
郭:まずDEが構築した分析基盤の上で、DSが事業課題を解く構造になっています。事業に直結するデータ分析・効果検証・改善施策の提案を行い、DEが「データがどう使われるか」を見越してデータ設計に入り込んでいるのが特徴です。
山田:各自がオーナーシップを持って様々なチャレンジをしているので、週1回の定例で各メンバーの取り組みを共有しています。座席も近いので気軽にコミュニケーションが取りやすい環境です。
![]()
―AIとは縁遠く、予測ができないからこそ成り立つ公営ギャンブルにおいても、データ活用は進んでいるのでしょうか?
郭:むしろ逆で、公営競技は膨大なデータが公開されているからこそ、データ活用との相性が非常に良い領域だと思っています。WINTICKETではAIを用いたレース予想機能をユーザーに提供していて、過去のレースデータやオッズ、選手の成績などを学習させた予測モデルを開発していますが、「予測できないから面白い」というギャンブルの本質は変わりません。AIの予想をひとつの参考情報として提供することで、初心者でも楽しみやすくなるという価値を生んでいます。
―その他、AIを使った業務効率化も進んでいるのでしょうか?
郭:はい、サービス面だけでなく、業務面でもAI活用は進んでいます。今日お話しする分析エージェントもその一つですし、開発レビューにもAIを取り入れています。公営競技はレガシーな産業と思われがちですが、だからこそデータやAIで変えられる余地が大きく、チームとしても積極的に取り組んでいます。
―そんな中でも、分析エージェントを開発したきっかけは何だったんですか?
郭:まずDSは事業側からのデータ抽出依頼対応に時間を取られ、本来集中すべき「何が問題か・なぜそうなっているか」の考察に時間を割けないという課題をずっと抱えていました。
山田:そこでSQL研修を企画し、研修自体は成功でSQLを書ける人は増えました。しかし、課題の本質はクエリの書き方ではなく、どこにどんなデータがあるかというドメイン知識の属人化でした。最初はメタデータの管理を統一してドキュメント化し、誰でもアクセスしやすい形にしようとしていたんですが、試行錯誤するうちに、人がドキュメントを探すよりAIに聞いた方が早いんじゃないかと考え、AIが参照しやすいメタデータの整備とAIへの接続を同時に進めていきました。
2. 自律型AI『Devin』がもたらした衝撃。導入の裏側に潜む、メタデータ整備の1年。
―続いて「分析エージェント」の開発の裏側を教えてください。
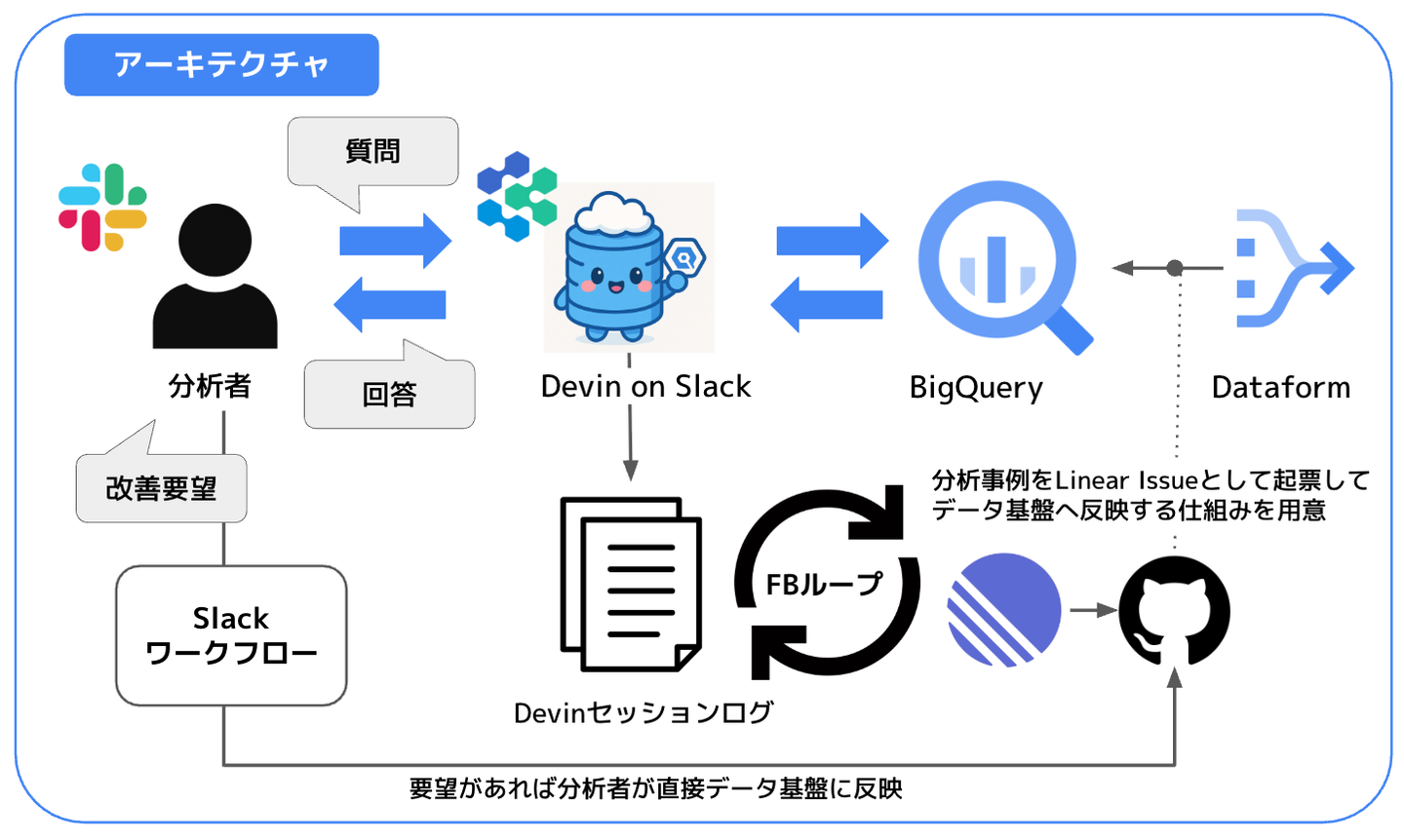
山田:当初はADKなどのSDKを使って自前でエージェントを構築することも検討していました。ただ、当初DE1人だったので保守運用まで回すことを考えると現実的ではありませんでした。そんなときにすでにWINTICKETの開発レビューで使われていたDevinを試しにデータ基盤と繋いでみたところ、想定以上に精度が良くて感動したのを覚えています。それまでにデータ基盤側の整備をかなり進めていたのが大きかったと思います。そこから、分析の際に呼び出す Playbook や Knowledge を徐々に整備していきました。
―実際にデータ基盤とDevinを連携させる際に気を付けた点などはありますか?
山田:大きくは3つあります。
1)まず優先的に参照する Tier をDevin の Playbook に書いたことです。WINTICKETではデータ基盤を大きく3層(lake・warehouse・mart)にレイヤリングしていて、mart層で集計済みのfact/dimensionテーブルを配置する設計にしてあります。mart層を使えばある程度指標がずれないようにモデリングされているため、AIにはまずmart層から探させて、なければ中間層へという優先順位をつけることで正しい数値にたどり着きやすくしました。
2)次に、DevinにはGitHubのリポジトリを直接読ませています。DataformのSQLやテーブル定義、カラムの説明がリポジトリにあるので、Devinはデータの依存関係を理解した上でクエリを書けます。
3)最後に、フィードバックの仕組みです。エージェントが行った分析を自動で記録して、間違いのパターンを見つけたらKnowledgeに反映する。エージェント自体を賢くするというより、参照先のデータとナレッジの品質を上げ続けるサイクルを回しています。
![]()
―DSは分析エージェントの開発において、どのような役割を担っているのでしょうか?
郭:分析エージェントの出力の正確性を担保する役割を担いました。エージェントの回答はおおむね合っているけれど細部がずれているというケースが多く、その精度を引き上げるのがDSの仕事です。競輪には「グレードレース」や「オッズ」など独特のドメイン用語や集計ルールがあるので、それらの意味やルールをAIに正しく理解させるために、Devinにナレッジとして登録し、実務で正確な回答が出せる状態に仕上げていきました。事業のドメイン知識をいかにAIが解釈可能な形に変換するか、という抽象度の高い設計が求められるなと感じています。
山田:また全員が使い慣れているSlackをインターフェースにし、AIがどういう思考プロセスでそのSQLを書いたのか、その背景や分析課程もSlack上に表示されるようにしました。リリース初期段階でDSがたくさん使ってくれたことで、WINTICKET全体に浸透していき、今では職種を問わず多くのメンバーが使っています。
―月100件ほど発生していた「データ抽出・確認」の問い合わせが、ほぼゼロになり、DSの働き方は変わりましたか?
郭:自分でSQLを書く前にエージェントで方向性を確認できるため、手戻りが激減しました。体感では業務効率が2倍近くになっています。実際に分析エージェントを活用して、新規ユーザーの離脱ボトルネック特定に取り組んだのですが、継続ユーザーと離脱ユーザーの行動パターンの差分を、複数の軸でセグメントを切りながら分析できるようになりました。「どこで・どんなユーザーが・なぜ離脱するのか」の特定がスムーズに進み、その結果をもとに離脱を防ぐための機能改修まで実行できています。今後は、これまで時間がなくて諦めていた仮説の検証にも取り組めるようになっていくと思っています。
![]()
3. 「データ民主化の終着点」を迎えて、AI共生時代のビジョンとは?
―分析エージェントの今後について、どのような構想を持っていますか?
山田:今は人がレビューして間違いを見つけたらフィードバックする仕組みがありますが、それだとスケールしない状態です。そこでエージェントが参照するメタデータやテーブルの品質を上げることで、そもそも間違いにくい状態を作りたいです。データの定義が整備されていて、テーブルの構造が綺麗であれば、AIが正しくデータを見つけて正しく分析できる確率が上がることが分かったので、エージェントの改善というより、エージェントが乗っかる基盤の品質をより向上させることを目指しています。
―AIにとって「良いデータ基盤」とは何だと思いますか?
山田:人間が見ても分かりやすい基盤が、AIにとっても分かりやすい基盤だと思います。テーブル命名のコンテキストもAIに渡させるので、当たり前のことになってしまいますが明文化できる規則性やルールをもって統一することが重要だとは思います。
―分析エージェントという強力な「バディ」を得たことで、データチームは今後どういった働き方が出来るのでしょうか?
郭:定型的なデータ抽出や集計をエージェントに任せられるようになった分、より高度な予測モデルの開発や、事業戦略のコアに踏み込む分析に集中できるようになると思っています。DSとしては、データ抽出からインサイトの導出までの工程をエージェントで効率化していきたいですし、最終的には「人間がやるべき思考」と「エージェントに任せるべき作業」の境界を継続的に更新していきたいと考えています。
―「人間がやるべき思考」とは?
郭:以前はクエリを書ける・分析ツールを使えること自体がDSの価値でしたが、データ抽出や集計をエージェントが担えるようになった今、人間の主戦場は「何を解くか」を定義する問いの設計力と、事業文脈の理解に移っていくと思います。「なぜこれを解くのか」「この結果から次に何を問うべきか」という思考の部分が剥き出しになっていく感覚ですね。
―最後に、WINTICKETデータチームにはどんな方が向いていると思いますか?
山田:DEとしては課題を見つけたときに、その場で対応するだけでなく仕組みで解決したくなるタイプの人だと楽しめる環境だと思います。またAIを使った開発にも積極的に取り組んでいるので、そこに興味がある人にはマッチすると思います。
郭:公営競技やスポーツという、データ活用がまだ成熟していない領域で課題発見・問題解決に取り組みたい人が向いていると思います。特定の技術や手法にこだわらず、事業課題に柔軟に対応できる人、他職種と連携しながら主体的に動ける方のご応募をお待ちしております。
山田:データチームはDS・ML・DEで一体運営されており、分析から基盤構築まで一気通貫で関われるのも魅力です。新しい技術も導入しやすい開発環境が整っていますので、もし興味をお持ちいただけましたら、まずはお気軽にカジュアル面談でお話できると嬉しいです!
「最新のAI技術を使って、レガシーな産業(公営競技)にイノベーションを起こす」。この挑戦にプロフェッショナルとして深く関わりたいと考える皆さん、ぜひ一度お話ししましょう。あなたの経験やスキルが、WINTICKETの未来を加速させる推進力になります。
![]()
採用情報:WINTICKETでは、データエンジニア・データサイエンティストを募集しています
[▶︎ データエンジニアの募集要項を見る]
[▶︎ データサイエンティストの募集要項を見る]
#WINTICKET #データ基盤 #分析エージェント #LLM #Devin #データマネジメント







/assets/images/7709735/original/3fac7de2-0515-4537-bdfb-6171ae20f2ca?1633496092)


/assets/images/7709735/original/3fac7de2-0515-4537-bdfb-6171ae20f2ca?1633496092)

/assets/images/7709735/original/3fac7de2-0515-4537-bdfb-6171ae20f2ca?1633496092)


