
株式会社AppBrew's job postings
- 自社プロダクト開発
- SNS動画制作ディレクター
- 美容メディア運営サポート
- Other occupations (18)
- Development
- Business
- Other
(この記事は2023年12月に弊社Zennに掲載した内容となっております)。
AppBrewでエンジニアインターンをさせていただいているshihoと申します。主にWeb版LIPSの開発をしています。
弊社ではAmazon Redshiftを用いてクエリの処理を行っています。Redshift インスタンスの数を契約更新時に1台減らしたところ、時折過負荷になり、クエリがスタックしてしまうことがありました。そのような事態を解消すべく、クエリの整理を行いたいと考えました。また、整理した結果として、インスタンス数をさらに削減し経費削減につなげられたらよい、というモチベーションもありました。
CTOの方から、SVL_STATEMENTTEXTとSVL_USER_INFO の情報を1週間分いただきました。
SVL_STATEMENTTEXTには、クエリを投げたアプリケーションのID(userid), クエリの内容(sequence)、クエリの実行開始時刻(starttime)、終了時刻(endtime)などが入っています。SVL_USER_INFOには、アプリケーションIDとアプリケーションの名前が入っているため、こちらのテーブルを参照することで、どのアプリケーション(redash,dbt,)がどのようなクエリをなげ、どれほどの時間を消費しているか知ることができます。
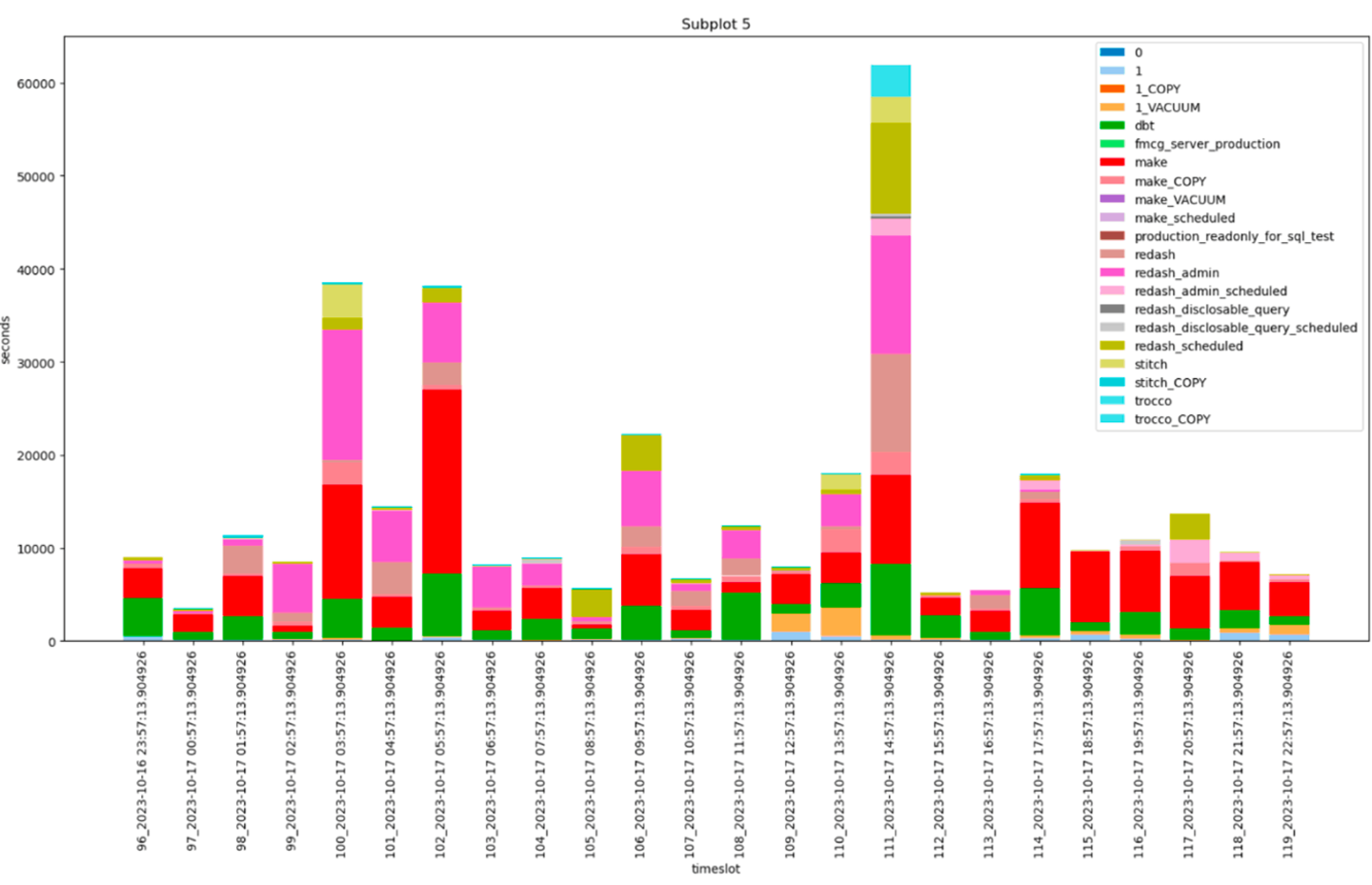
まずは、1時間ごとに区切って時系列を追い、異常がないか確かめます。
なお、以下の時間はクエリ処理開始時間から終了時間までを集計したものであり、実際にCPUを占有している時間とは異なりますが、一定程度相関はあるでしょう。
peakはありますが、日本時間で深夜0時のあたりなので、日中の仕事への影響は少なそうです。
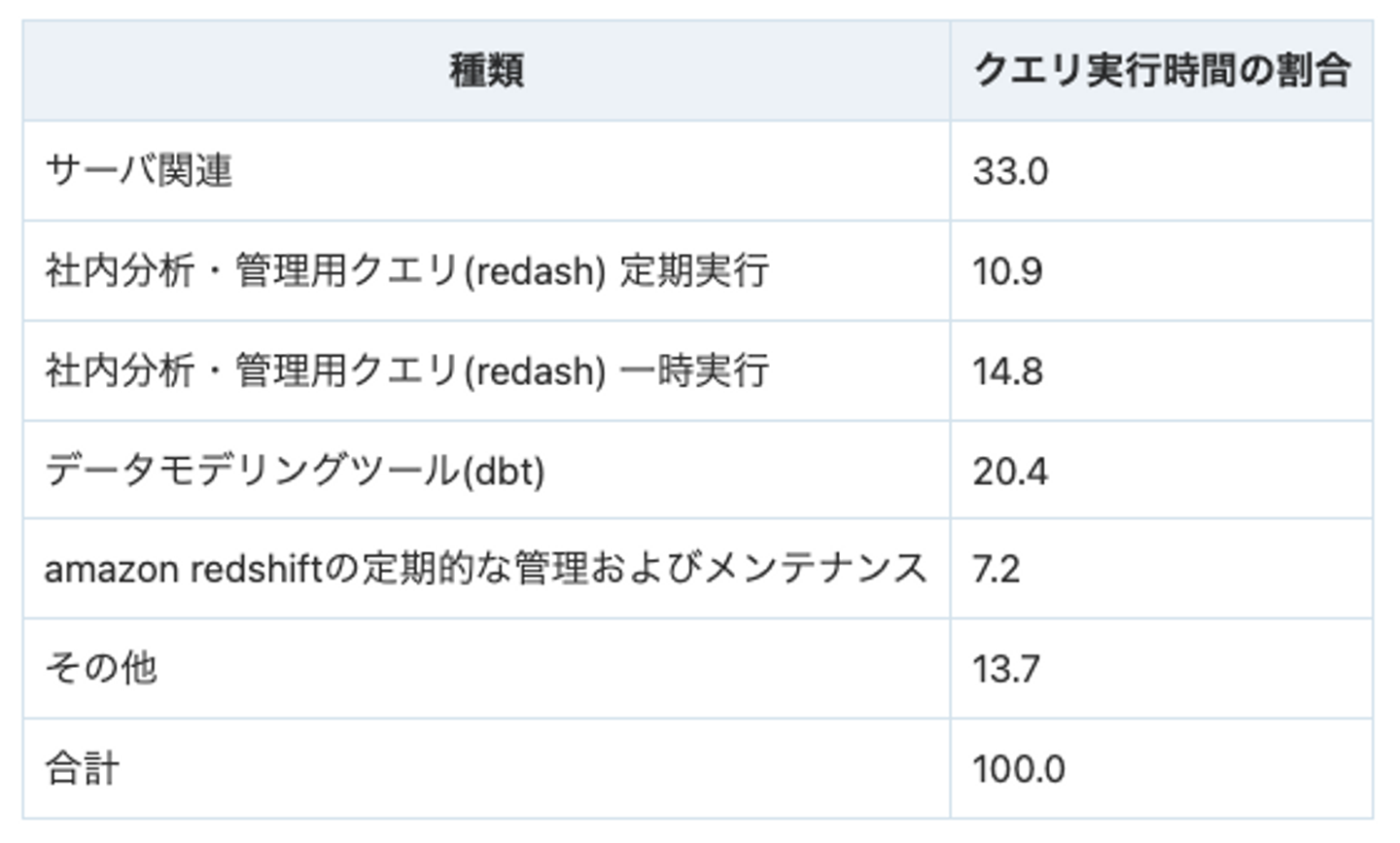
クエリの種類ごとに、クエリ実行時間の割合を算出したものを以下に示します。
もっとも多いのはサーバ関連のクエリです。また、定期実行クエリは簡単に見直しができそうです。
LIPSのサーバ関連のクエリに関しては、10分以上実行に時間がかかっているクエリをリストアップし、CTOの方等に対応をお願いしました。
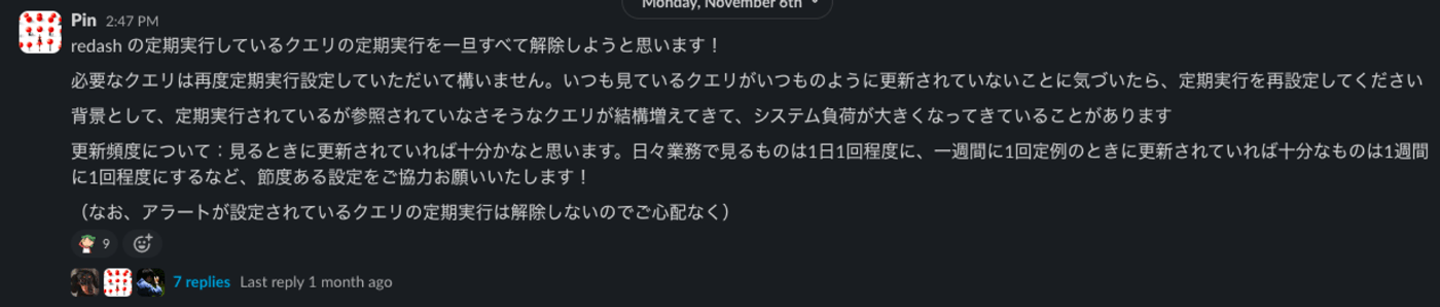
また、redashでの定期実行クエリは、一旦一律に停止が実行され、必要に応じて、クエリ参照者に再開をお願いしました。重いクエリだが定期実行されてかつ実際に定期的に参照しているものに関しては、参照する期間を減らすなどの対応が行われました。
処置後の結果は以下のようになりました。いずれも、対応をとる前のクエリ実行総時間を100とした場合の値を示しています。
全体としては増えていますが、定期実行クエリや、サーバ関連では減少を確認することができました。
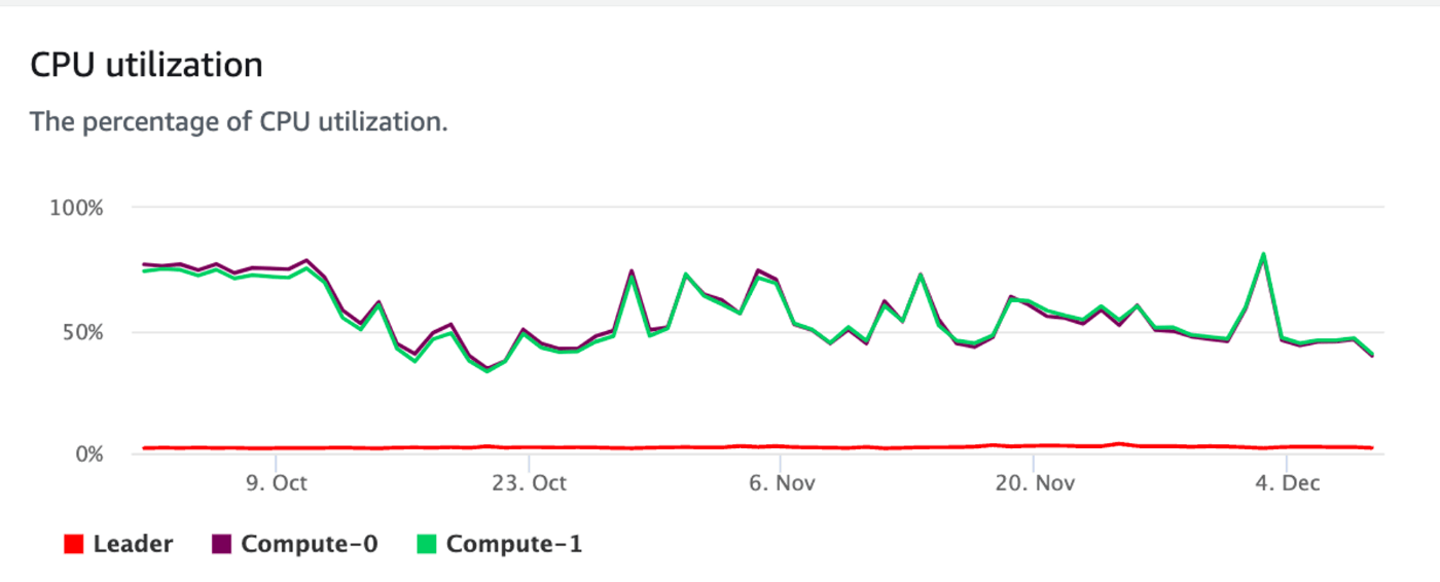
肝心のCPU使用率の推移は以下のようでした。
分析を10月下旬、対応は11月の上旬に行われ、それ以降特段の問題は起きていない状況です。
時系列を見て、異常がないか見る、また、クエリを階層的にグループ分けし、実行時間の大きさが目立つグループをさらに細分化する、というやり方で分析を行い、分析を元に関係各所に対応をお願いしました。
結果として、一部の種類のクエリ実行時間数について、減らすことができました。





![]()

