User-User Collaborative Filtering For Jokes Recommendation

Have you ever had ants in your home? If you’ve had, you might know that ants first spread out individually looking for food. But as soon as one of them finds the food, it makes its way back to the nest, leaving behind the scented trail that other ants soon follow. And then you have a stream of ants heading back and forth the food source and the nest. Those ants are exhibiting social navigation, a type of recommendation system where each of the ants goes out and explores a different part of the space, literally space, and when they find something that they think the community would like, they let everyone know about it.
Recommendation Systems are a big part of today’s world. Customers may see a lot of available options and not know what to buy. They may be unaware of a product that serves their purpose, or maybe a movie or a song or joke they will eventually like but they haven’t heard about it yet. This is why recommendation systems are used. They make specific recommendations to customers to overcome the above-mentioned problems. They may recommend items based on its content (content-based recommendation), based on user’s session activities (sequential or session-based recommendation), based on items that similar users like (user-user collaborative filtering), or based on the similarities with items that customer has liked previously (item-item collaborative filtering), or maybe a hybrid model of two or more of the above-mentioned systems.
In this article, we will focus on similar users based recommendation system, otherwise also known as user-user collaborative filtering, and apply it to give jokes recommendations.
Dataset
The jokes dataset is taken from Dataset 1 of the Jester Research project under the flagship of UC Berkeley Laboratory for Automation Science and Engineering. It has the ratings for 100 jokes from 73,421 readers. Ratings are real values ranging from -10.00 to +10.00 (the value “99” corresponds to “null” = “not rated”). Out of 73,421 readers, 14,116 have rated all the 100 jokes, and the remaining 59,305 have rated at least 15 or above jokes.
Algorithm
We will be implementing the user-user collaborative filtering approach to give the jokes recommendation to an active user. This approach relies on the idea that users who have similar rating behaviors so far, share the same tastes, and will likely exhibit similar rating behaviors going forward.

Source: Image by author. The figure on the left describes the user-based collaborative filtering approach whereas the figure on the right describes the content-based recommendation approach.
In other words, user-user collaborative filtering is an algorithmic framework where the neighboring users are identified based on the similarity with the active user, and then scoring of the items is done based on neighbor’s ratings followed by a recommendation of an item based item’s scores by the recommendation system. Companies like Amazon, Spotify, Facebook, LinkedIn, Google News, Netflix, etc are the most popular ones known to use some form of user-user collaborative filtering. Amazon’s “ Customers who bought this item also bought ” is a popular example of this filter, as shown in the following screenshot:

Source: Image by author. Implementation of user-user collaborative filtering by Amazon
The algorithm for recommendation can be summarized in 5 steps.

Source: Image by author
However, there are varieties of configuration points at each of these steps that can be helpful in making choices for setting up user-user collaborative filtering.
Let’s dive in detail and look at various configuration points for each step.
Data Normalization
Ratings are highly influenced by the scale of individuals. Some individuals are kind-hearted while rating and tend to rate high, whereas others are just cold-hearted and tend to give medium ratings for good content. Normalization is one way to compensate for such a user's behavior by adjusting the scale of rating to be comparable or on the same level to other user’s ratings.
One simple technique to normalize the ratings is to subtract the rating average of each user from their ratings.
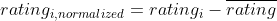
Here is the python implementation of the normalization.
def normalization(dataframe):
dataframe_mean = dataframe.mean(axis=1)
return dataframe.subtract(dataframe_mean, axis = 'rows')Let’s implement this method for the jokes dataset. For demonstration purposes, we will select ratings by 10 users for the first 10 jokes.

Source: Image by author
We can also implement other configurations at the normalization step.
Z-score is another possible way to normalize the rating data where the normalized value tells about how many standard deviations from the mean our score is.
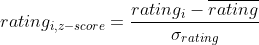
Computing Similarity
Similarity computation between users is the main task in collaborative filtering algorithms. The similarity between users ( also known as the distance between users) is a mathematical method to quantify how different or similar users are to each other. For a User-User CF algorithm, similarity, sim ₓᵧ between the users x and y who have both rated the same items is calculated first. To calculate this similarity different metrics are used. We will be using correlation-based similarity metrics to compute the similarity between user x and user y, sim ₓᵧ using Pearson correlation
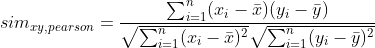
The choice of Pearson correlation makes sense as similarity metrics as rating data for each user tend to be normally distributed. Like other correlation coefficients, this one varies between -1 and +1 with 0 implying no correlation. Correlations of -1 or +1 imply an exact linear relationship. Positive correlations between user x and user y imply that if user x has rated a joke as positive, there is a very high chance that user y will also rate positively to the same joke.
Here is the python implementation of the Pearson Correlation using scipy package.
def similarity_pearson(x, y):
import scipy.stats
return scipy.stats.pearsonr(x, y)[0]Now we implement the above-mentioned method to find Pearson similarity for the ratings dataset. Please note that here we are evaluating similarity using the ratings dataset and not by normalized ratings dataset because the Pearson Correlation method takes care of the normalization step!

Source: Image by author
We can also implement other configurations at the similarity computation step.
Cosine Similarity is another possible configuration to compute similarity among two users by computing the cosine of the angles between two rating vectors and determining whether both vectors are pointing in the roughly same direction. Cosine similarity is one often used to measure document similarity in text analysis.
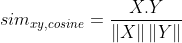
Selecting Neighbours
User-User collaborative filtering (UUCF) approach heavily relies on active user neighborhood information to make predictions and recommendations. Neighborhood selection can either make or break the recommendation for an active user and can have a direct bearing on the rating prediction and item recommendation.
Currently, any commercial recommendation system has a very large number of users, thus the neighborhood must be composed of the subset of the users if the recommendation system wants to guarantee an acceptable response time.
The figure below shows four traditional approaches to select neighborhoods.

Source: Image by author
- Use all dataset when the dataset is very small
- Select dataset when similarity score is above certain threshold
- Select top N dataset by similarity score
- Select a similar cluster using a clustering method like K-Mean
We will be using the threshold approach to select neighborhoods for an active user. Let’s designate the user at index 2 as our active user.

Image by author
The active user has read only 4 out of 10 jokes, so we will find out, which joke out of the remaining 6 will be the best recommendation for the active user.
Let’s select a threshold of 0.1 or above to filter out the neighbors.
Here is the python implementation to find similar neighbors using the threshold method. Here “sim” implies for similarity array of pandas series type.
def neighbours(sim):
return [sim.index[i] for i, v in enumerate(sim) if v>=0.1]Here is the screenshot of the similarity array for our active user. Please ensure to drop active user’s own similarity to itself before working.

Source: Image by author
We will be implementing the “neighbors” method for the similarity array.

Image by author
As evident from the screenshot above, here only users with index 3, 4, 6, 9 qualify to be neighbors.
But in any commercial recommendation system that has a very large number of data, we may end up with a large number of neighbors if we go with the threshold method. So the question arises, how many neighbors?
Theoretically speaking, the more the better, if we have a good similarity matrix. But practically, noise from dissimilar neighbors decreases usefulness. if we mix a lot of low similarity neighbors then the difference from target user can start to degrade the quality of the recommendation. Between 25–100, high similarity neighbors are often used in practical and commercial recommendation system.
Scoring Items
Scoring items using the neighborhood ratings is at the very core of making a collaborative filtering model. The weighted average is one of the most common methods to construct such a scoring system. We will be using weighted average to compute scoring for our items.
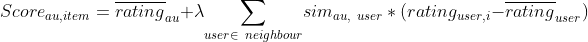
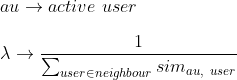
The first step is to select only those items which hadn’t yet been rated by the active user
Image by author
In our case, it’s joke_1, joke_2, joke_3, joke_4, joke_9, and joke_10. Since the remaining four jokes are already rated, we won’t score those items.
Below is the screenshot of the neighbor_rating and neighbor_similarity pandas dataframe. We will these two dataframes and ratings dataframe to create scores for each joke. Note that here we are using the normalized rating dataframe for finding neighbor_rating.

Source: Image by author
Here is the python implementation to calculate the score of the items.
def score_item(neighbor_rating, neighbor_similarity, ratings ):
# aumr -> active user mean rating
aumr = np.mean(ratings.iloc[2, :])
score = np.dot(neighbor_similarity, neighbor_rating) + aumr
data = score.reshape(1, len(score))
columns = neighbor_rating.columns
return pd.DataFrame(data = data , columns = columns)We will implement “score_item” method to find the score of all the jokes.

Source: Image by author
Here, it’s clearly visible that joke_2 have the highest score, and joke_4 have the lowest.
Items Selection
Once the item scoring is decided, the item with the maximum score will be the best recommendation. Thus in our case, joke_2 will be the most suited recommendation to our active user.
Recommend Joke 2 to our active user
However, there is a high chance that by using this method the recommendation may saturate to just a few recommendations every time. This may lead to a degrade of recommendation quality.
One simple solution to this problem is to take top n positively scored items and randomly recommend one of those.
Pitfalls of User-User Collaborative Filtering
User-User Collaborative Filtering systems have been very successful in the past, but their widespread use has revealed some real challenges. Let’s discuss briefly the four key challenges of using such a system:
Cold-Start :
If a user is new, its similarity with other users cannot be calculated as the system may not have any form of data on this new user.
Scalability :
As the number of users or items began to increase, then the user-user collaborative filtering suffers a drop in performance due to the growth in similarity computation.
Data Sparsity:
With large item sets, a small number of ratings, often there are situations where no proper recommendation can be made for the user.
Influencing:
An organization or person can deliberately manipulate prediction that gets made for others by creating multiple civil accounts and putting fake ratings.
Conclusion
User-User Collaborative Filtering approach is the most commonly used and studied technology for making recommendations and has been widely adopted across the industry. The core concept behind this approach is that “similar users tend to have similar tastes.”
In this blog, we have presented the UUCF approach and its practical application on the jokes recommendation using 5 step process. We have also shown the possibility of varieties of configuration points at each of these steps.
At many of these steps, we didn’t choose the best result but a more random choice out of the acceptable choices. This is the main irony of the recommendation system as we don’t look for the best result and a bit of randomness is always welcomed by the user and is necessary otherwise the whole experience becomes monotonous.
References
- http://eigentaste.berkeley.edu/dataset/
- https://github.com/abbi163/Jester-Joke-Recommender-System
- Marwa Hussien Mohamed, Mohamed Helmy Khafagy, Mohamed Hasan Ibrahim. “Recommender Systems Challenges and Solutions Survey”. ITCE’2019, Aswan, Egypt, 2–4 February 2019
- Zhipeng Zhang, Yasuo Kudo, and Tetsuya Murai. “Neighbor selection for user-based collaborative filtering using covering-based rough sets”. Annals of Operations Research, Nov 8, 2016
- Dietmar Jannach, Markus Zanker, Alexander Felfering, and Gerhard Friedrich. “Recommender System, An Introduction”. Cambridge University Press, 2011
- Rounak Banik, “Hands-On Recommendation Systems with Python”. Packt Publishing, 2018
- Coursera. Course on “Nearest Neighbor Collaborative Filtering”, by the University of Minnesota. Week 1 and Week 2.

