𝐓𝐡𝐞 𝐀𝐫𝐭 𝐨𝐟 𝐂𝐥𝐞𝐚𝐧 𝐂𝐨𝐝𝐞 : 𝐄𝐬𝐬𝐞𝐧𝐭𝐢𝐚𝐥𝐬

Table of Content :
1. Does Clean Code Matters
2. What is Clean Code
3. Why Easy to Read
4. Why Easy to Understand
5. Why Easy to Change
6. Conclusion

For developers, this is often the moment of truth in any code writing-style dilemma they find themselves in-between readability and brevity. The figure above shows two different ways to write Python code for an order processing system. This is a very good starting point of a review of the pros and cons of various coding philosophies.
Pitted against the traditional talkative coding style, that is usually friendly to clarity and self-documentation, is its outright opposite: a compact version, friendly to conciseness and efficiency. In fact, both styles shall find their places in the world of programming, with context, conventions, and personal taste often serving as deciding factors.
We discuss fine-grained details of these two approaches to answer the question “Which code do you like, and why?” in light of aspects related to maintainability, readability, and performance. This analysis provides context to the lively debate amongst members of the software development community regarding how to balance the use of concise code with clear, self-documenting implementations.
1. Does Clean Code Matters ?
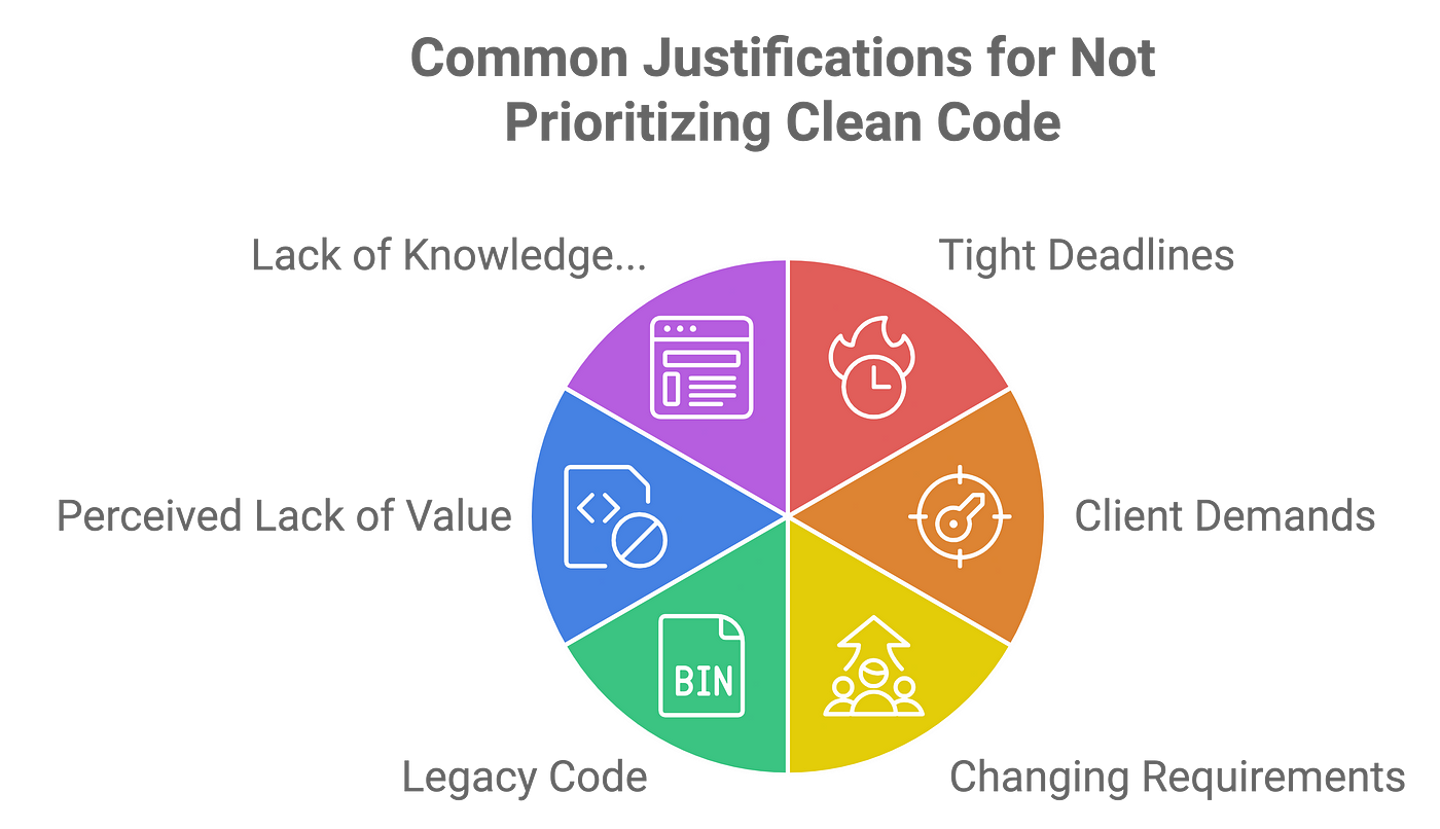
Let’s review common excuses that programmers make for not writing clean code. These may seem valid for temporary reasons, but the importance is in seeing where they lead over time with respect to the production of quality, maintainable software.
Tight Deadlines :
One of the standard reasons developers make compromises concerning clean code practices has to do with very tight deadlines. When there is not sufficient time, a natural urge is to take shortcuts by emphasizing functionality over code quality, hence coming up with quick, though messy, uncontrollable fixes.
Client’s Demands :
Closely related to tight deadlines is external pressure from clients who want the job done yesterday. This may result in forcing developers to concentrate only on delivering features-a lot of times at the expense of clean and orderly code.
Changing Requirements :
In fast-moving project environments, the ever-changing requirements can make them very shy to write clean code: they suspect that the next change request will just blow away the investment they’ve just made. Therefore, developers would rather not invest in good quality code.
Legacy Code :
Working with existing legacy systems can even further discourage the use of clean coding. To developers, it might be a waste of time to introduce clean code into an already complex codebase that, on top of everything, could be chaotic.
Perceived lack of value
It may be seen by developers and project managers alike as an implementative luxury instead of a necessity. They may think that all this time spent beautifying the code does not add to anything in apparent functionality, hence not making it that much of a priority.
Lack of Knowledge
Surprisingly enough, another barrier to clean code can simply be a lack of understanding of what it consists of or how to apply it effectively. A knowledge gap in this regard can only further worsen the effect of poor coding, as developers may barely understand the need for clean code that can be maintainable.
Worse of all is the false idea of practical limitation. For some, perfectly clean code cannot be achieved in a real-world environment. This may lead to a defeatist attitude when it comes to code quality and a feeling that striving for excellence is a lost cause.
2. What is Clean Code ?
Let’s focus on the most interesting question of all: What is Clean Code? The picture that came out defines it in few but powerful words:.
Clean Code: Definition
Clean code should not be about being aesthetic and also not about blind obedience to a set or rules; rather, it is an intrinsic way of writing code that is maintainable, readable, and efficient. The four important features of clean code are given in the picture below.
1. Easy to Read: Just like well-written prose, using clear names and consistent formatting.
2. Self-Explanatory: What the code is supposed to do, and how it does it, should be obvious, at least with few or no comments.
3. Easy to Change: Because of a modular structure, it’s easy to make changes without side effects.
4. Easy to Test: Provides much facility for different automated testing by making the code reliable and easy to refactor.
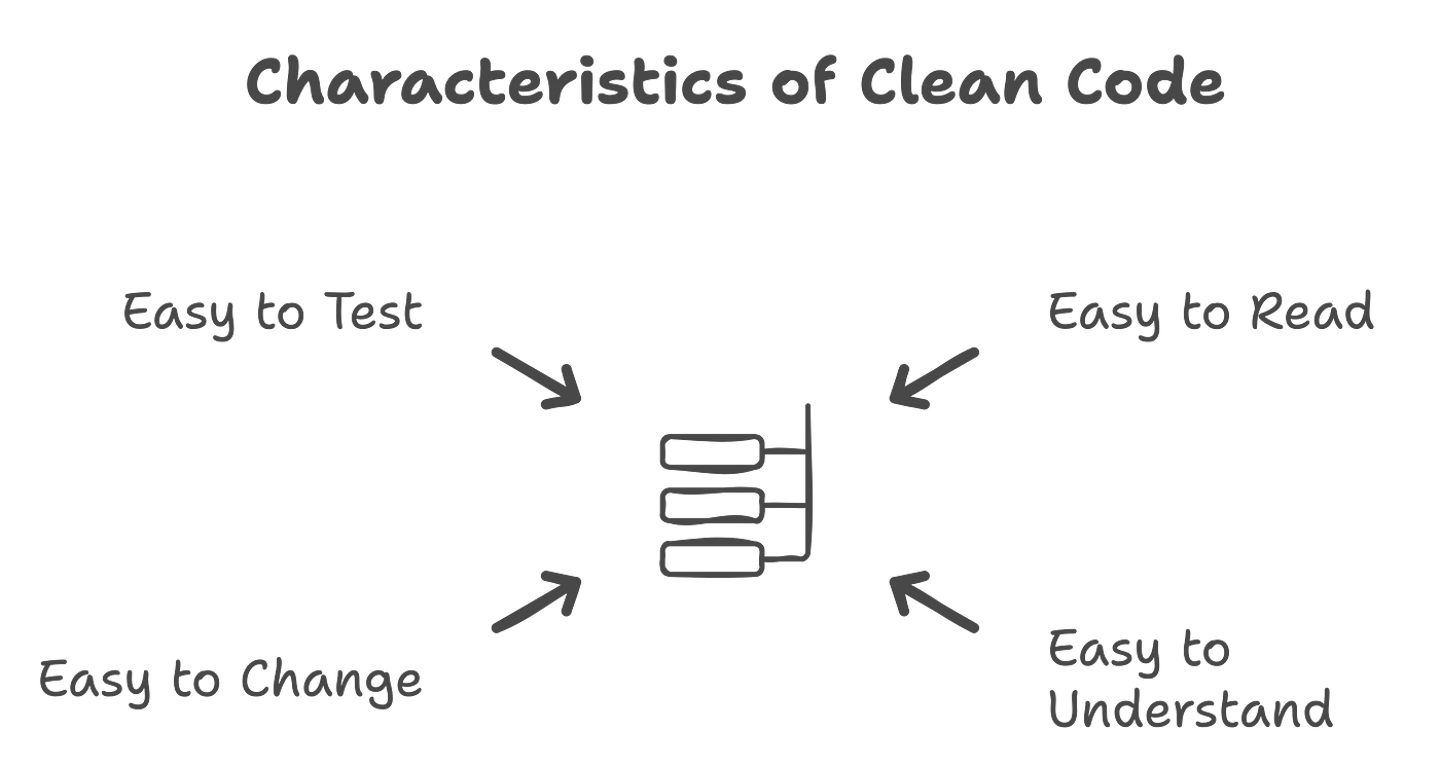
These characteristics then set the benchmark of the clean code philosophy, which amazingly captures the key issues of software development: maintainability, scalability, and reliability. Anyone who follows such principles will create code that works and will also stand against time with respect to changing requirements. The rest of this chapter explores some practical techniques that actually refactor noisy code into clean, efficient software. We then discuss how a clean code mindset can respond to the following challenges.
2. Why easy to Read ?
Coming off of our discussion of clean code, let’s take a look at one of the key components in making it clean: readability. Why is readability important in software development?
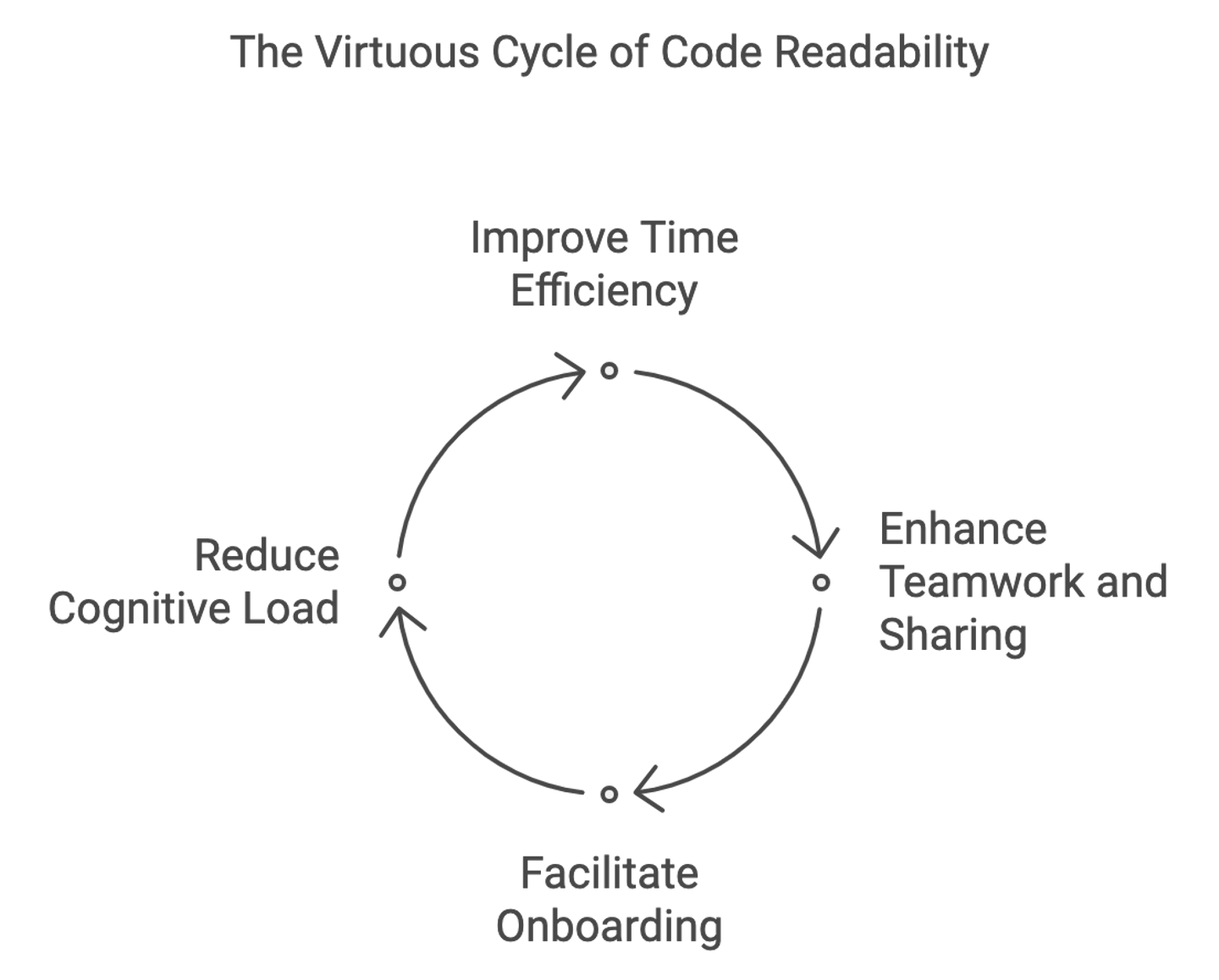
Why Focus on Readability?
- Time Efficiency : Most of the time, developers really spend their time reading code rather than writing it. If the code is readable, then a person will be able to understand it faster, and thus debug much faster, maintain, and develop.
- Teamwork and Sharing : Some aspects on which collaborative development environments are focused involve many developers operating in the same codebase. Readable code in this case allows for much easier collaboration, in that each member of the team can understand both their own work and others.
- Onboarding New Members: It reduces the learning curve for new members joining the team to get acquainted with the project in the shortest time and be able to make worthy contributions.
- Cognitive Load Reduction: Code as readable as natural language reduces the need to use heavy cognitive load for a developer; hence, he/she can focus on the problem rather than deciphering complex code.
Consequences of Focusing on Readability
- Improved Maintainability : It is easy to update and modify, having fewer bugs.
- Increased Productivity : With this, developers can then work in a more productive manner-develop faster.
- Better Knowledge Transfer : The documentation is a way of knowledge transfer.
- Reduced Technical Debt : It is important because it reduces technical debts that emanate from poorly understood implications.

In other words, clean code readability cares about team efficiency and collaboration, eventually for a long-term successful software project. Attention to readability is of great help in developing codes functional to viable and adaptive to future needs. We now go into some practical guidelines and best practices on how to write readable code and how such principles are put to work when developing.
How to make it easy to read ?
1. Choose Meaningful names
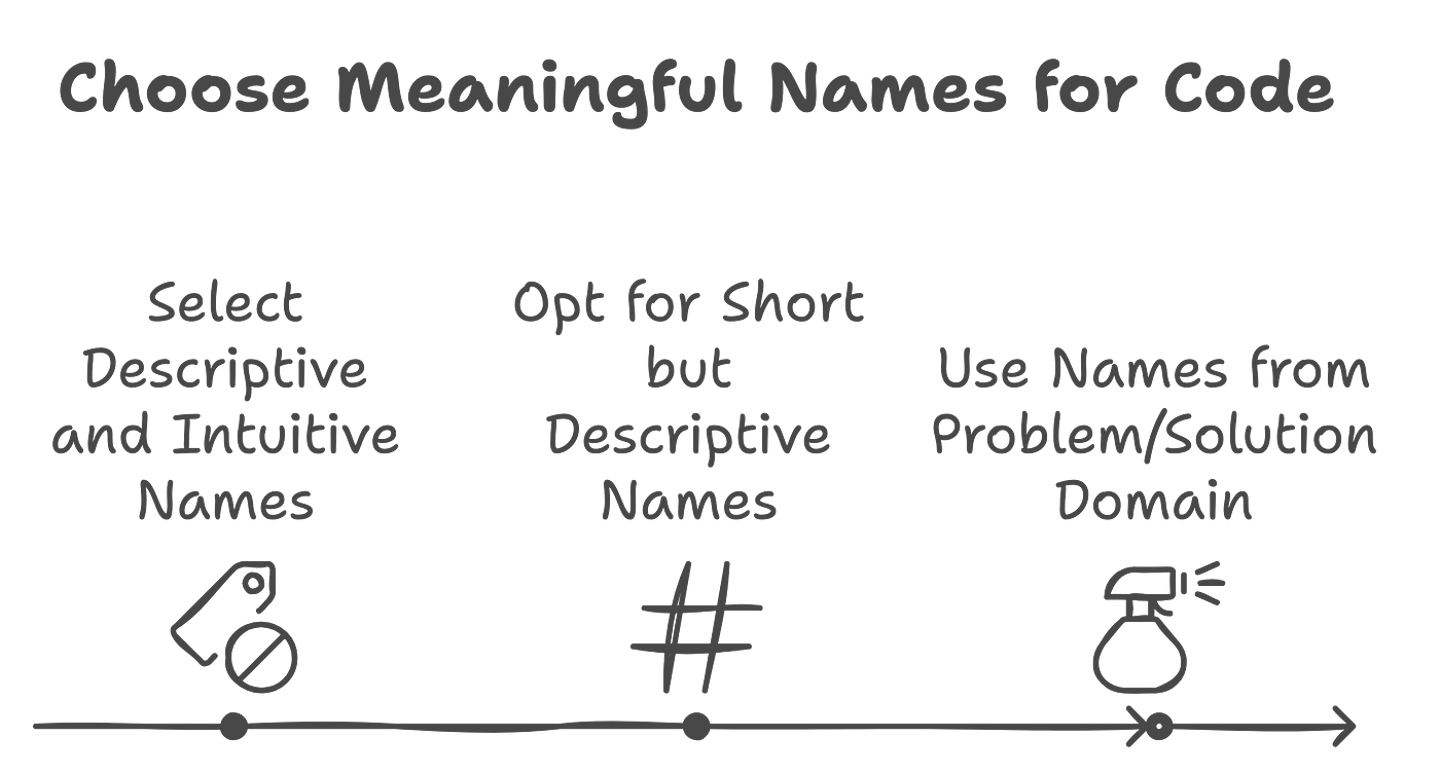
- Descriptive and Intuitive : The name should descriptively define the purpose of the variable, function, or class to allow some other programmer to go through code efficiently without the need for any external comments.
- A short but descriptive name : It can be as short as possible, but not at the price of being not descriptive for a human reading in context of the program.
- Use Names from Problem/Solution Domain : Choosing names from the problem or solution domain improves understanding. It puts the code into harmony with real-world concepts that it works out, hence making things more intuitive.

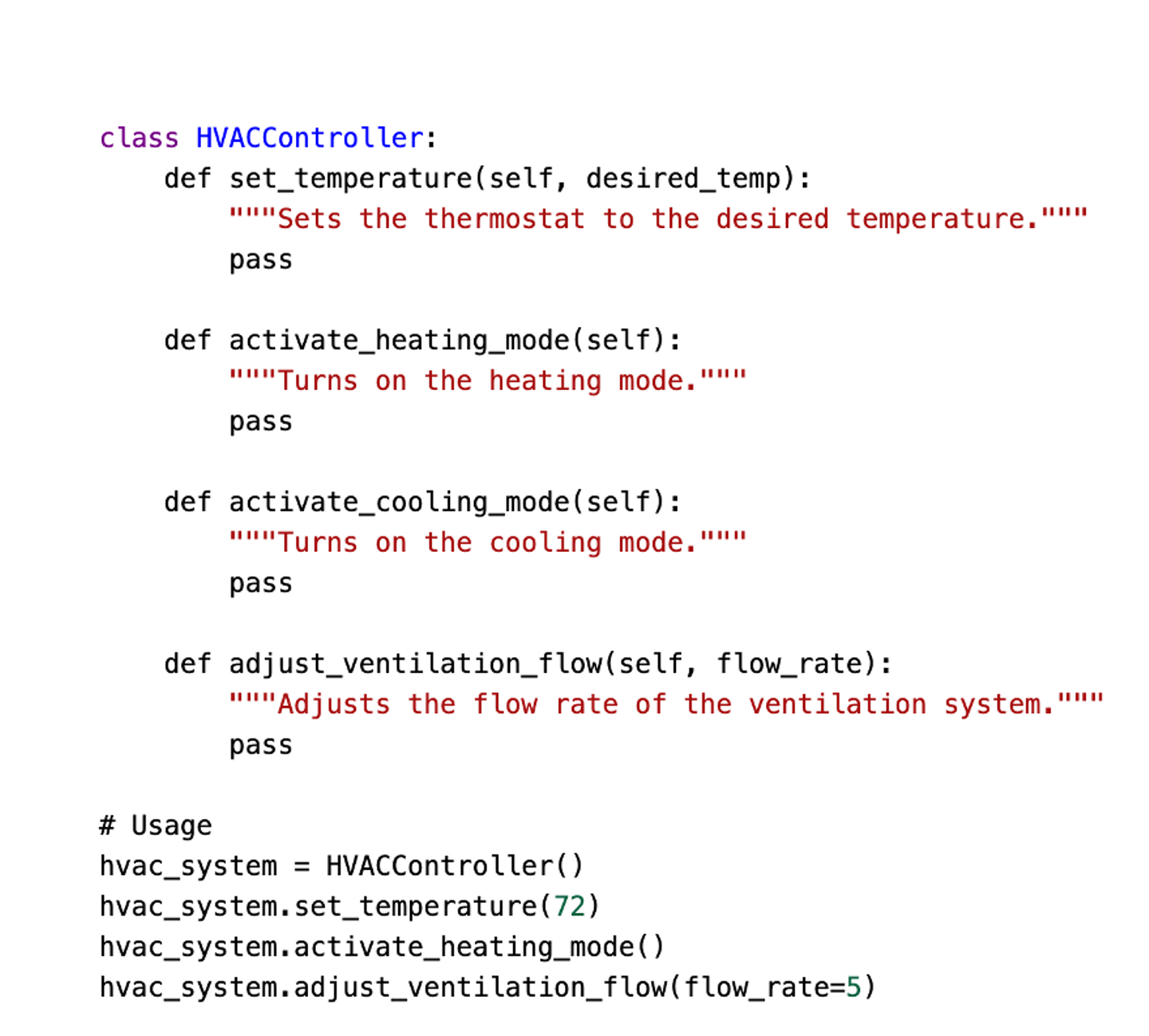
2. Choose Class and Method names

Class Names Should Be Nouns: Classes represent objects or concepts; hence, their names should be a noun or a noun phrase. This helps in defining what the class is, hence making more sense of it, such as “OrderProcessor” or “HVACController”, which inherently dictates the functionality to be expected of the code.
Method names should be verbs or verb phrases : As methods perform some action, their names should be verbs according to what the method does. Examples will include anything like “set_temperature”, “activate_heating_mode”, and “calculateTotal”. This practice conveys the getting and setting of something that occurs with the method; in fact, it makes the code more readable.
Be Consistent with the Language Domain : Class and method names should be chosen in such a way that they are consistent with the terms normally used in the business domain. That way, consistency is ensured, or guaranteed, and the code is bound to be specifically about the domain; therefore, it will be easily readable by those people already conversant with the domain. Examples: “BankAccount”, “calculateInterest” for a financial application.
Below is a perfect code example following all three suggestions above.
4. Why Easy to Understand

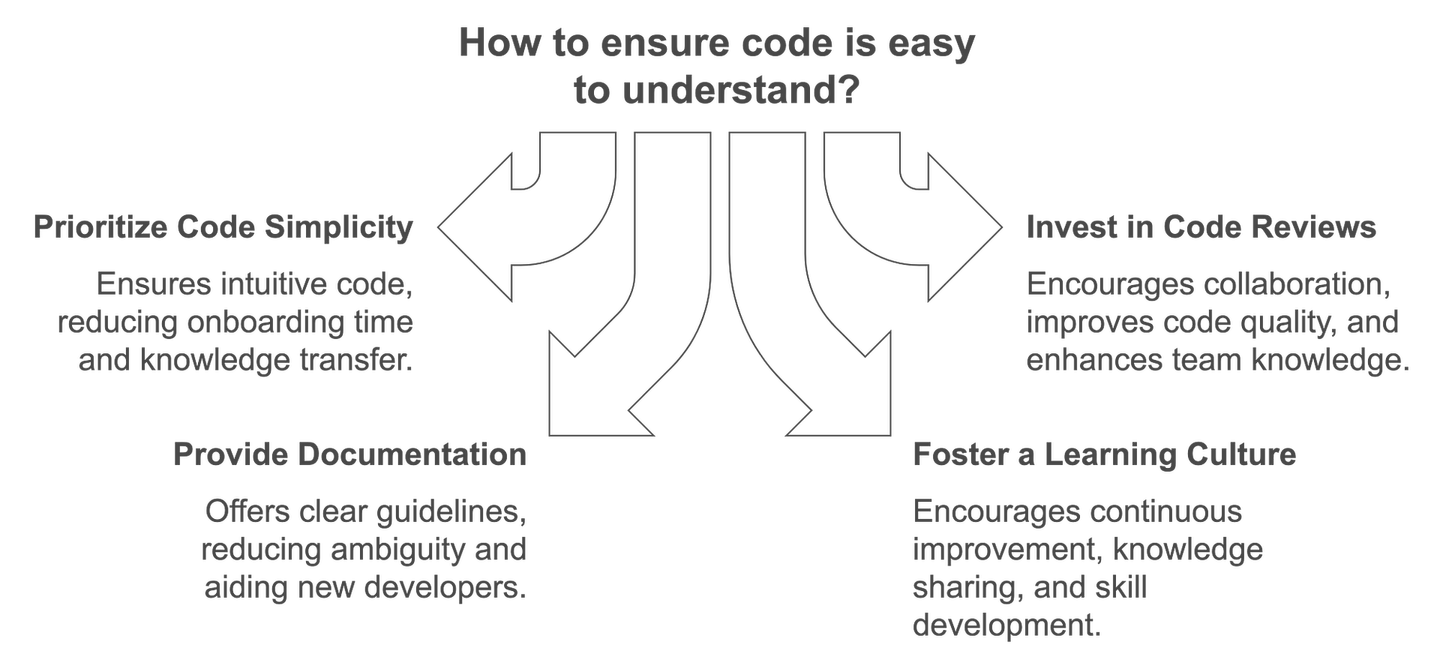
Having code that is easy to understand brings many benefits to the development process. Here are the key reasons why:
Any feature by anyone: Code should intuitively be such that any developer can jump into the project to start working on any part with minimal onboarding or handholding.
Change in the developers of a team: Whenever there is a shift of people to other teams or leaving, clarity of code ensures continuity with no loss in momentum.
Less knowledge transfer required: As most of the code is self-explanatory, there is no need to formally transfer much knowledge.
Work-life balance: More readable code implies no night debugging, no stress, or urgent development because the developers can scan and resolve issues quickly.
This simplicity ensures effectiveness in the team, less turnover, and a better work-life balance.
5. Why Easy to Change
Change in software is inevitable, with technology and business requirements being dynamic. Business growth and shifting customer expectations compel changes in software to accommodate new requirements, regulations, and market demands. Besides, technological advancement keeps introducing new tools, frameworks, methods, and such for which code needs modification for performance, security, or other functionality enhancement purposes. Besides, bugs, unforeseen issues, or user feedback contribute to developers revisiting and refining their solutions so that the software remains effective, efficient, and competitive.
How to make it easy to read
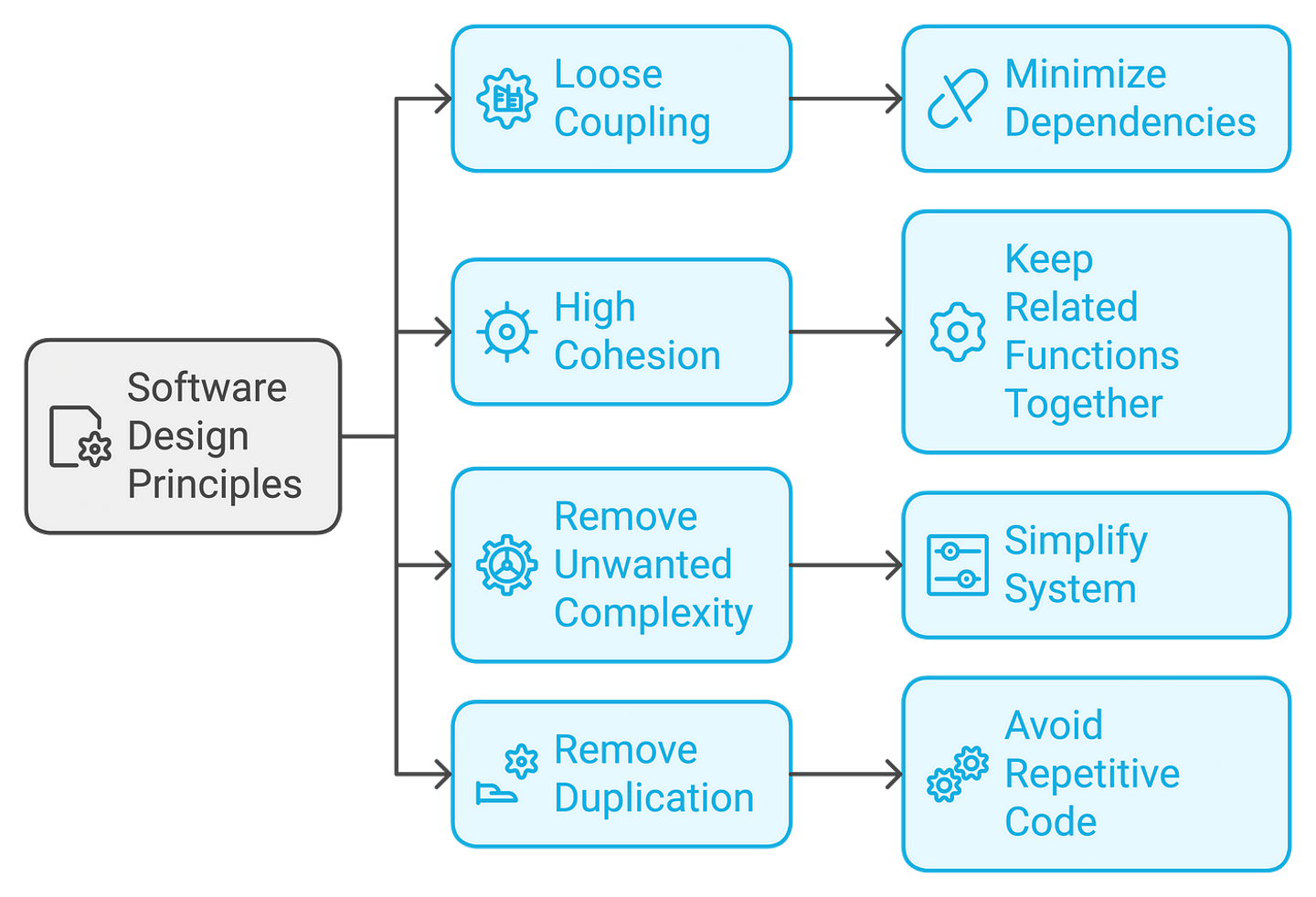
In order for code to be easy to change, some important software design principles have to be followed. First of all the concept of Loose Coupling: which calls for dependency among components to be reduced to a minimum because changes to some module will thus not cut through the system. High Cohesion arranges functionalities related to a particular aspect of the system together for easy maintenance and changeability of the code. The system becomes straightforward by removing unwanted complexity, with fewer chances of bugs and errors. Finally, removal of duplication cleans up the code and makes the maintenance of the code easier to perform since developers do not have to change the very same logic multiple times when performing updates. This set of principles enables developers to make changes more quickly, safely, and flexibly.
Tight vs Loose Coupling in Software design !
Tight Coupling :
Components are highly dependent on each other’s implementation which can do making changes very difficult even in simple ways like changing path.
Let’s see it with a code example.
import glob
import pandas as pd
import os
def aggregate_csv_files(store_name):
"""Aggregates all CSV files from a specified store into a single file."""
# Define the base path for easier modification and readability
base_path = r"C:\development\csv_data\processed_data"
# Construct the folder path where the CSV files are stored
csv_folder_path = os.path.join(base_path, store_name)
# Use os.listdir to find all files that match the pattern
csv_files_path = [
file for file in os.listdir(csv_folder_path) if file.endswith(".csv")
]
# Read and concatenate all found CSV files into a single DataFrame
combined_df = pd.concat(
[pd.read_csv(os.path.join(csv_folder_path, file)) for file in csv_files_path],
ignore_index=True
)
# Define the output file path
output_file_path = os.path.join(base_path, f"{store_name}_merged.csv")
# Save the combined DataFrame to a new CSV file
combined_df.to_csv(output_file_path, index=False)The function above is an example of highly coupled code where the whole function is highly dependent on base_path and certain combination of base_path and store_name
Now let’s look at loose coupling
Loose Coupling
Components are loosely or non-dependent on each other such that making changes are relatively simple.
Let’s see it with another code example.
import os
import pandas as pd
def aggregate_csv_files(csv_folder_path, output_file_path):
# Use os to find all files that ends with csv
csv_files_path = [file for file in os.listdir(csv_folder_path) if file.endswith(".csv")]
# Read and concatenate all found CSV files into a single DataFrame
combined_df = pd.concat([pd.read_csv(file) for file in csv_files_path], ignore_index=True)
# Save the combined DataFrame to a new CSV file
combined_df.to_csv(output_file_path, index=False)The function above is an example of loose coupled and highly reusable code. Input parameters are easier to implement, and the code won’t need any major change while reusing.
Low vs High Cohesion in Software design !
High Cohesion
High cohesion means each module or class is designed to have a specific, focused responsibility and it should only contain elements that are related to the functionality it provides.
Let’s see it with another code example below. Each function is designed to carry our only one task as mentioned from the function name.
Low Cohesion
Low cohesion means that a module or class tries to do too many unrelated things. Low cohesion leads to a scattered design where functions and data are not related to one another.
Let’s look at another code example.
import os
import pandas as pd
import matplotlib.pyplot as plt
import datetime
def int_are_graph_plot(store_name, folder_path, files):
today = datetime.date.today()
yesterday = today - datetime.timedelta(days=1)
start_date = yesterday.strftime("%Y-%m-%d")
end_date = yesterday.strftime("%Y-%m-%d")
df_total = pd.DataFrame()
for file, equipment in files.items():
df = pd.read_csv(os.path.join(folder_path, file))
df['timestamp'] = pd.to_datetime(df['timestamp'])
df = df.set_index('timestamp')
df = df.loc[start_date:end_date]
df['equipment'] = equipment
df_total = pd.concat([df_total, df])
df_total = df_total.groupby([df_total.index.date, df_total.index.hour, 'equipment'])['used_power'].sum().reset_index()
df_total.columns = ['date', 'hour', 'equipment', 'used_power']
df_total['used_power'] = df_total['used_power'] / 1000
color_dict = {
'Other': '#666666',
'Freezer': '#FF4B00',
'AirConditioner': '#005AFF',
'LightPanel': '#03AF7A'
}
for date in pd.date_range(start_date, end_date, freq='D').date:
df_plot = df_total[df_total['date'] == date]
ax = df_plot.pivot(index='hour', columns='equipment', values='used_power').plot(
kind='area',
stacked=True,
color=[color_dict[equipment] for equipment in df_plot['equipment'].unique()]
)
plt.title(f'{store_name} Power Consumption {date}')
plt.ylabel('Power Consumption (kWh)')
plt.ylim(0, 40)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.show()In the above coding example, function is aggregating multiple csv together followed by doing data transformation operation and then do the plotting of the graph. This is an example of low cohesion design
6. Conclusion
Cleaning the code is not beautification, and neither is it all about following rules and regulations. Rather, it’s a mindset that enforces maintainability, readability, and efficiency in writing code. Making code readable, understandable, modifiable, and maintainable will grant developers better productivity, collaboration, and adaptability. Principles arising from loose coupling, high cohesion, reduction of complexity, and duplication allow better system design. At the end, clean code means projects will be more successful, easier to maintain, update, and scale over time, but it also entails a healthier environment for developers in this fast-evolving landscape.



