学びの断片を、知識の資産へ変える
技術を記し、考え、発信する。小さなアウトプットが、やがてプロダクトになる。Go マイクロサービス + Next.js で構築された、モダンな技術スタックの実践場。
https://www.tenhub.tech/

AGIからASI(Artificial Super Intelligence)へ — AIの進化に対する期待と不確実性が交差する今、人間のアウトプットは日々AIに置き換えられつつある。社会の歯車がAIによって指数的に加速する中だからこそ、一度立ち止まって自分に問いかける。「何が必要で、何をしたいのか」。
その問いの過程で気づいたのは、人間の本来の価値は「思考し続けること」にあるということ。情報を整理し、実証し、活用し、自分の考えを与え続ける場 — それがナレッジベースだった。今後AIを使う側にとどまらず、仕組みを理解し作る側へ。その一歩として生まれたのが TenHub。
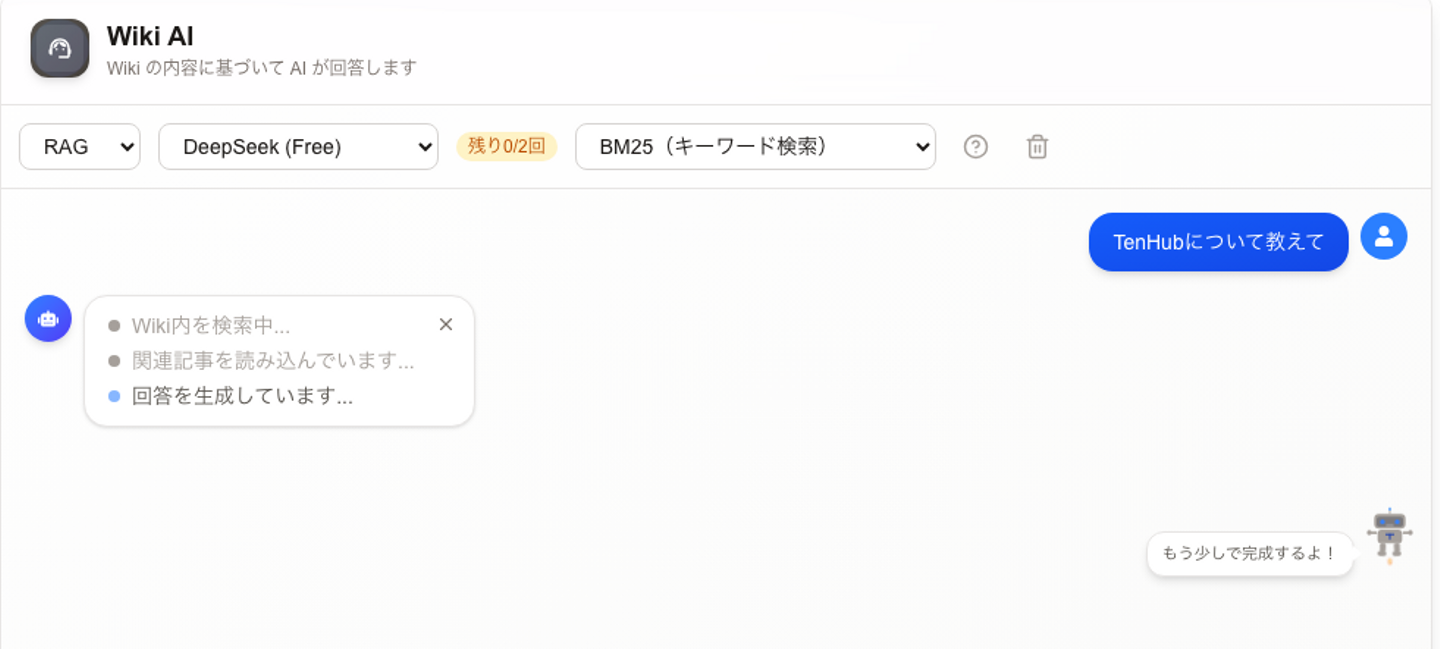
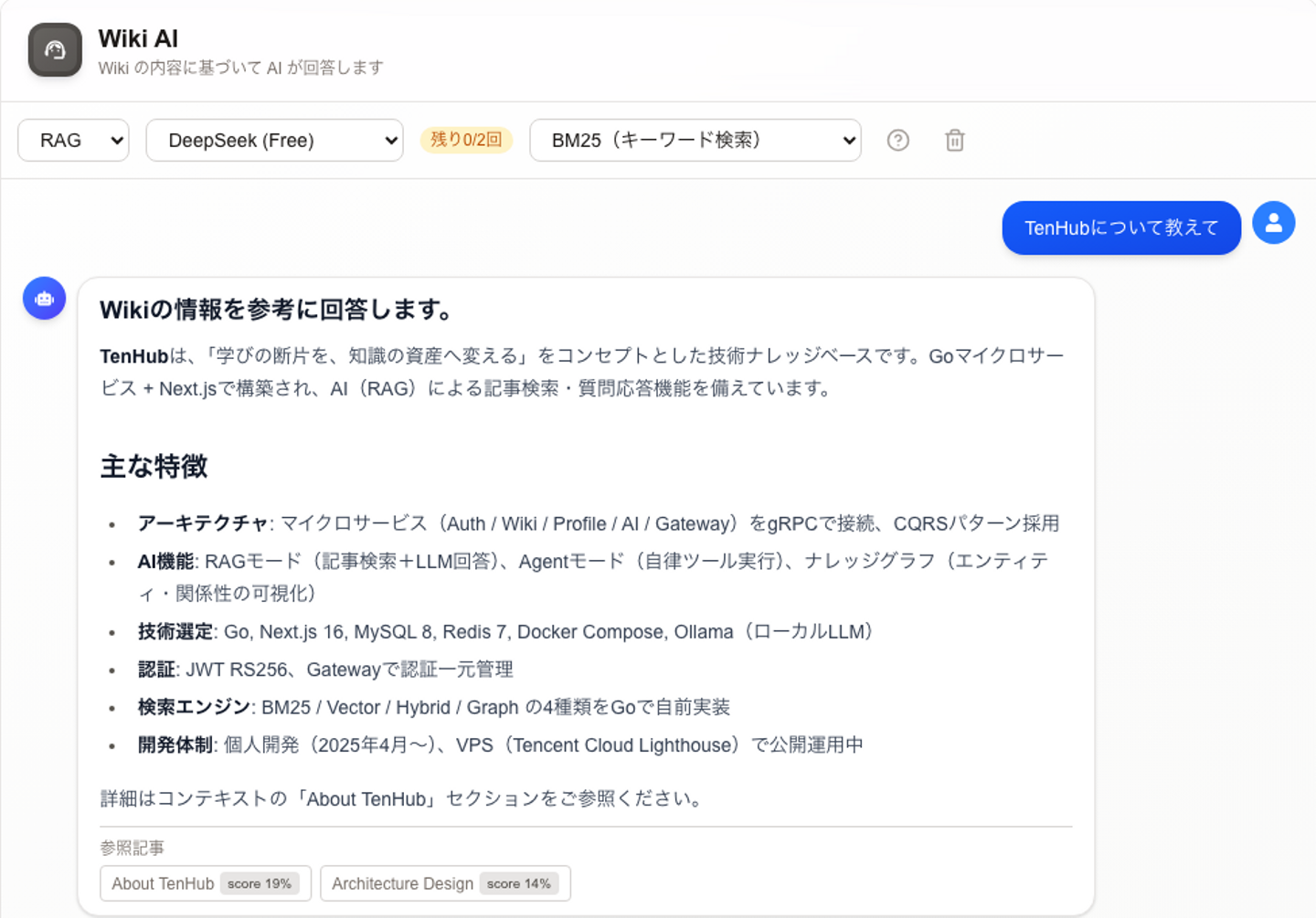
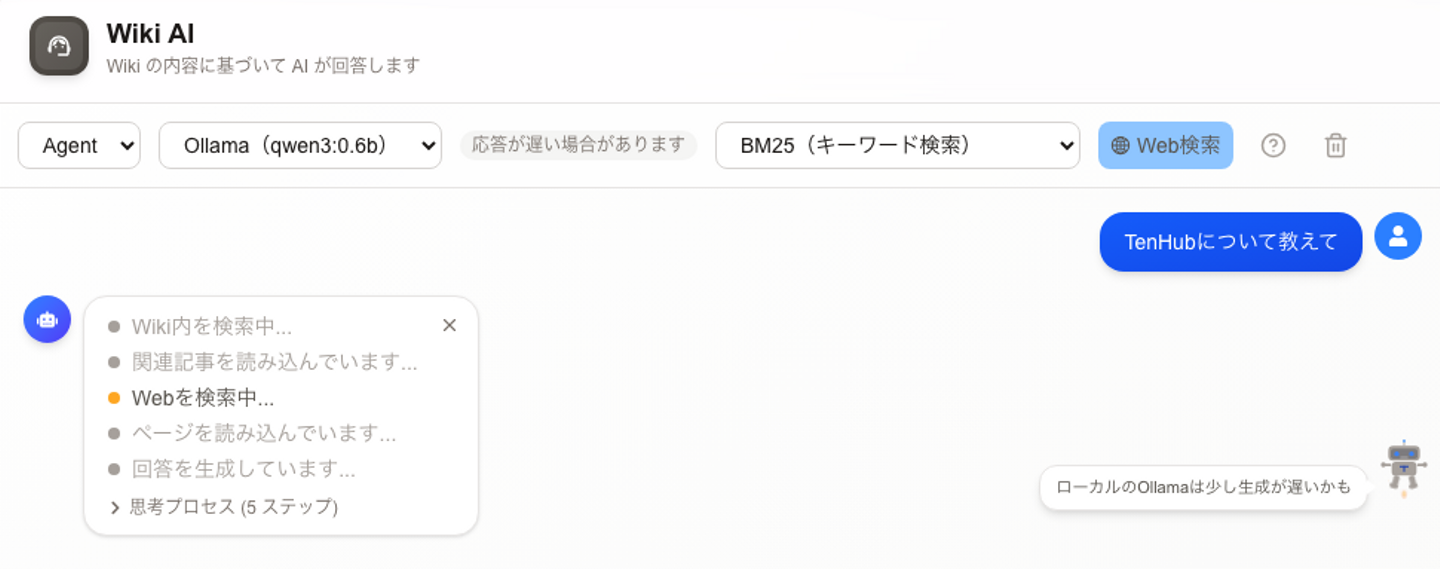
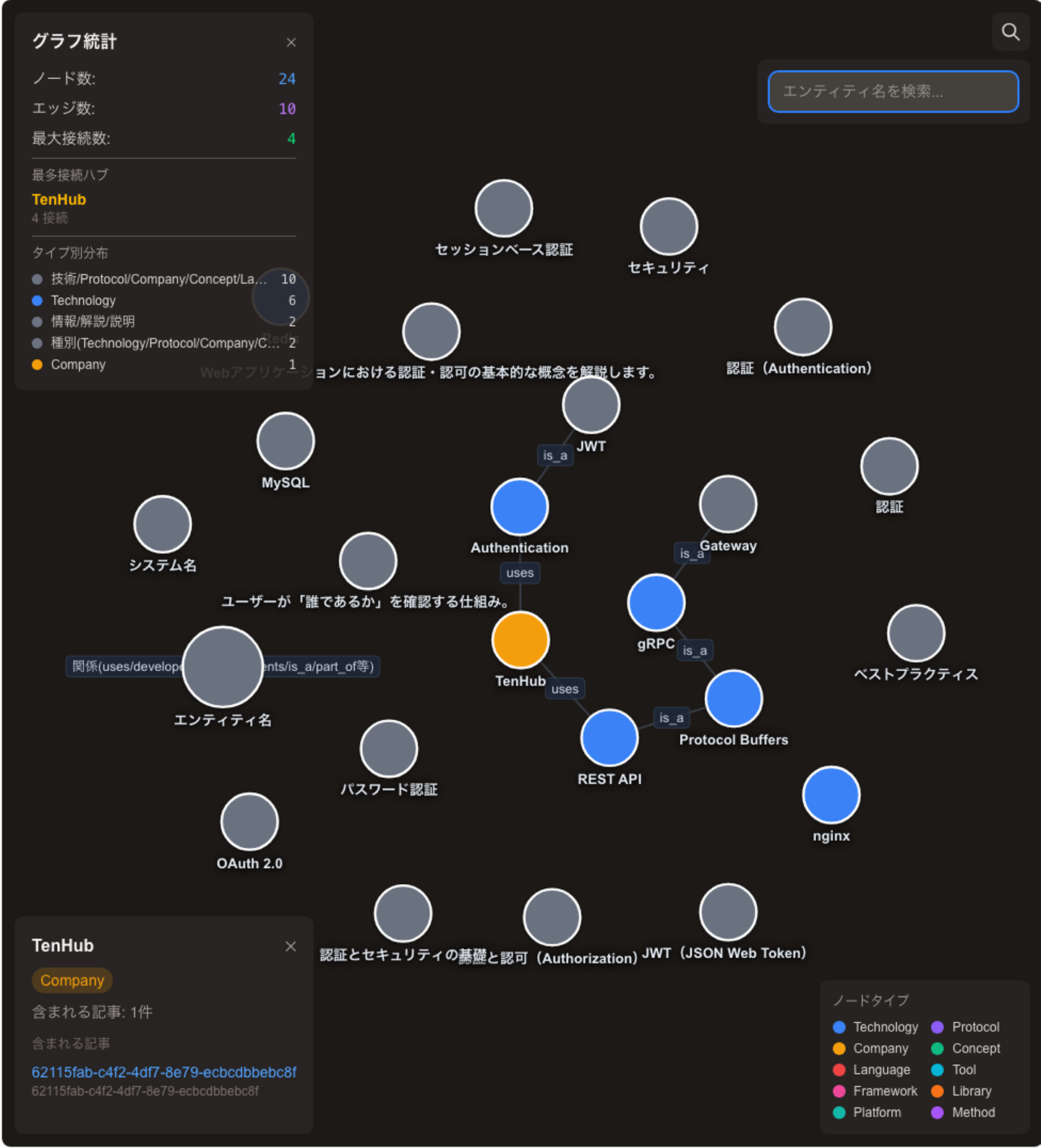
RAG / Agentモードにより、内部の記事を検索・要約できます。
また、外部検索機能も搭載しており、ナレッジベース内の情報と外部情報を組み合わせた調査・回答が可能です。
軽量モデルを使用しているため、抽出精度には一部ばらつきがありますが、知識同士のつながりを俯瞰する用途として活用できます。(他いい用途があれば、ぜひ教えてください)
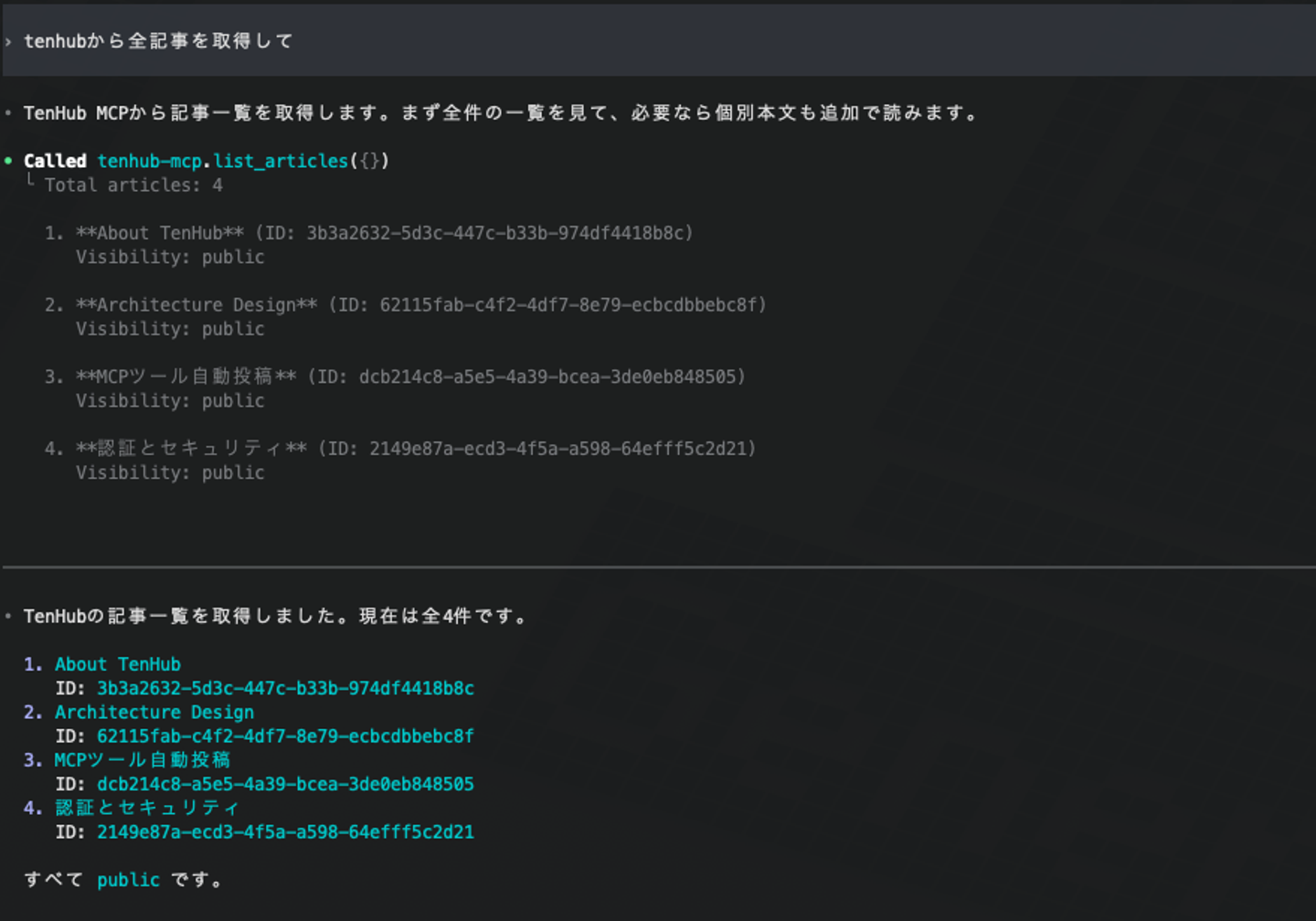
記事の作成・取得・更新・削除といった基本的なCRUD操作に加え、記事検索ツールも利用できます。
全記事を取得
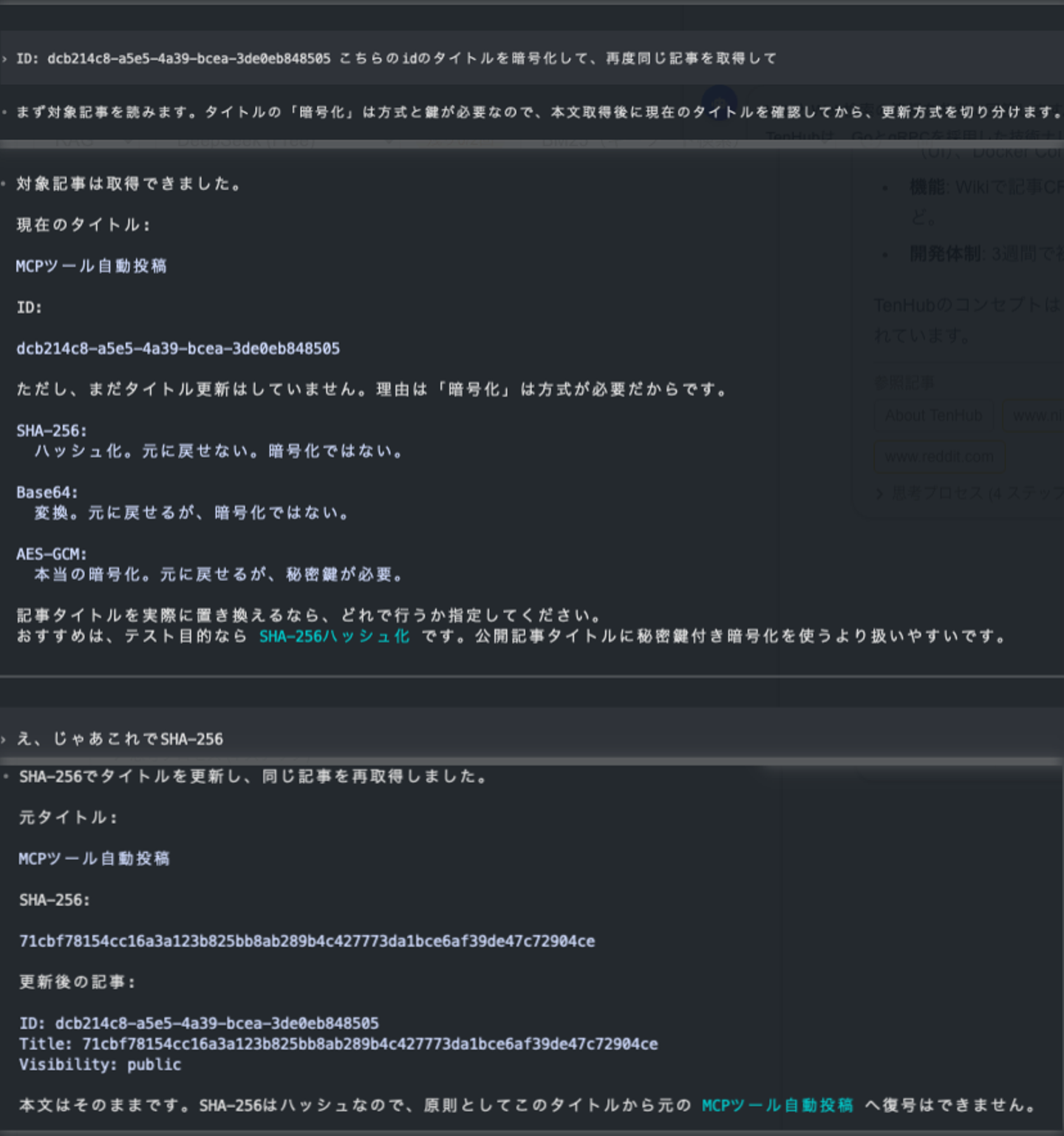
実際に記事を取得し、タイトルを変更してもらう
- 検索エンジン別の閾値チューニング
1. 5種の検索エンジン(BM25/Vector/Hybrid/Graph/TF-IDF)を自前実装
2. 各エンジンのスコア分布が異なるため、閾値を個別設定
3. Vector: 0.30(意味的類似度を広く拾う)
4. Hybrid: 0.50(キーワード+意味のバランス)
5. Graph: 15.0(強い関係性のみ通す)
閾値以下のノイズを除去してからLLMに渡すことで、軽量モデルの「迷い」を減らす
- コンテキストの質 > 量
1. 検索結果は上位5件に絞る(大量のコンテキストは小さなモデルを混乱させる)
2. 閾値を超えた記事がゼロの場合、LLMを呼ばずに定型応答を返す(トークンを無駄にしない)
3. Hybrid検索(BM25+Vector の重み付き結合)で、キーワードの正確性と意味的関連性を両立
- 差分更新による応答速度改善
1. ベクトル埋め込みをJSONに永続化し、新規・更新記事のみ再計算
2. ナレッジグラフも差分更新(記事のハッシュで変更検知)
3. サーバー再起動時のコールドスタートを最小化
- プロンプト設計の工夫
1. 言語制約の明示(日本語/英語のみ、他言語禁止)
2. 記事が見つかった場合は「必ずその内容を説明する」指示
3. 簡潔に回答する指示(生成トークンの効率化)

![]()