
目的
合同輪講が近づいて来ました。教授達から論文を読めとせかされます。しかし、世の中に存在する論文に目を通していくと日が暮れてしまいます。
そこで、今回は自動で論文を収集し、ChatGPTで要約し、それをteamsに送信する様なツールを作成した。
現時点ではCiNiiにしか対応していない。
参考元サイトさんでは、クラウドを用いていたがまだ学生の私には少し手が出せない。今回はオンプレのみで実装していこう。
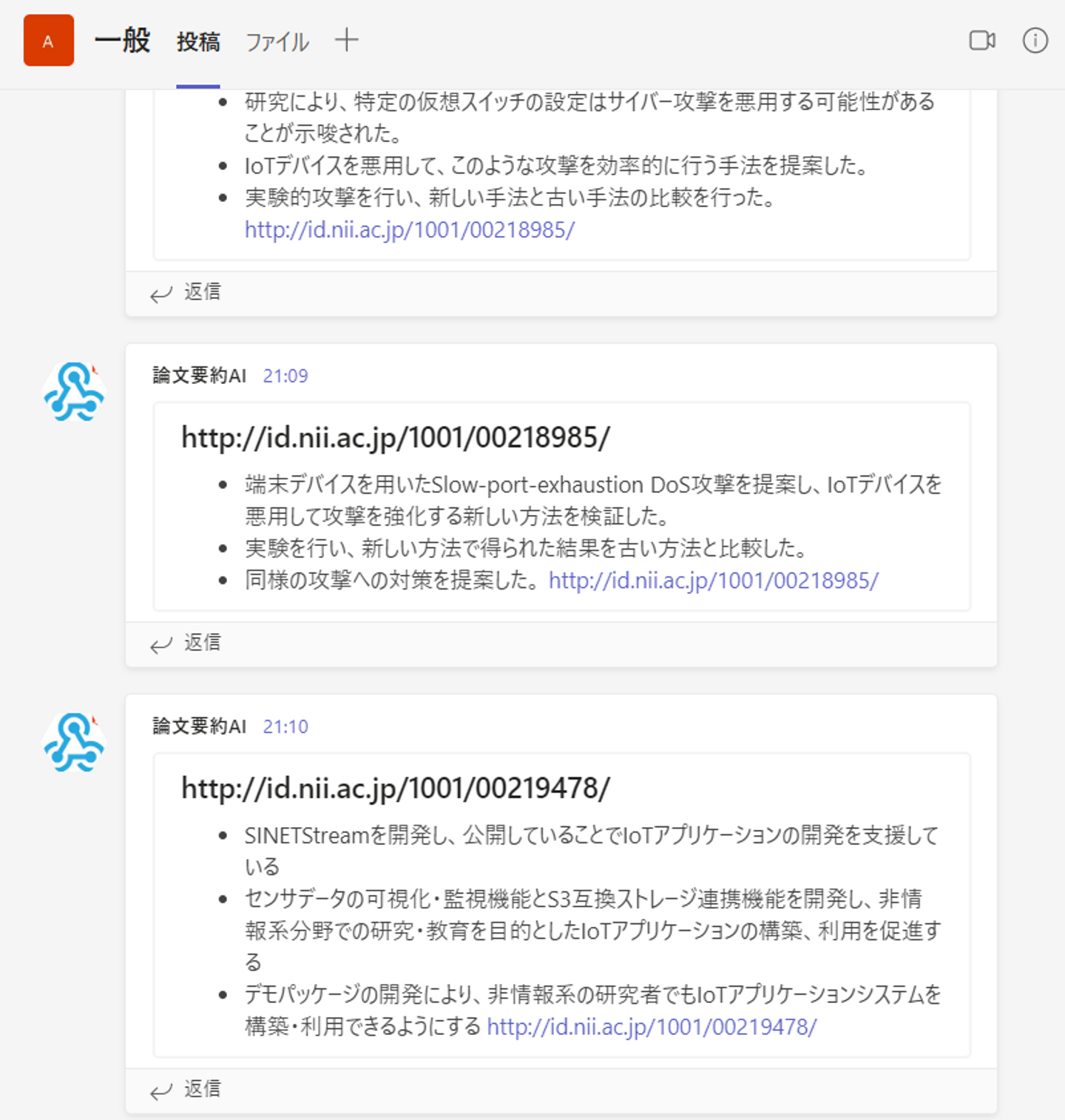
完成形
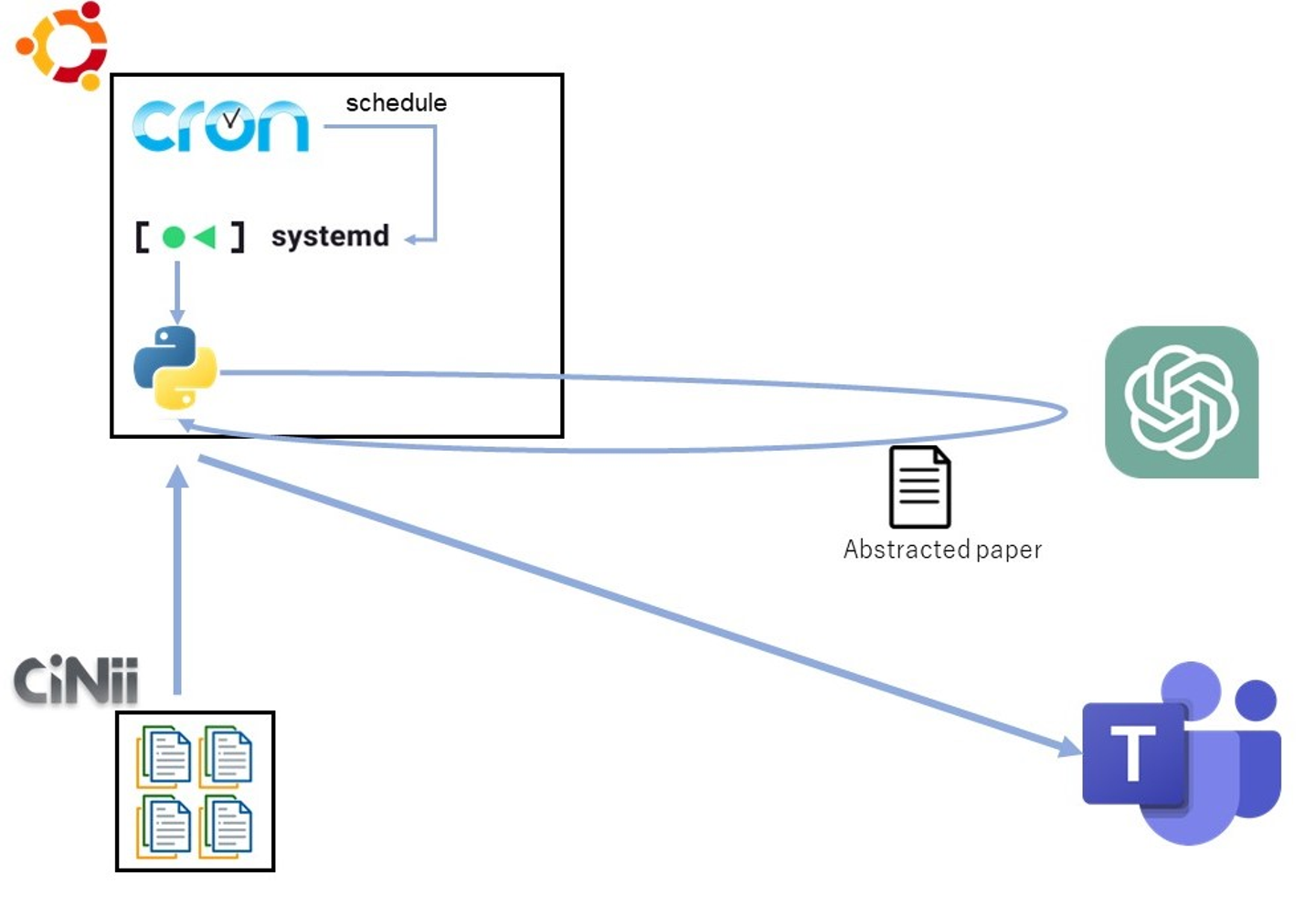
構成図
コード
https://github.com/shoma564/AIservey
論文の検索対象候補
Googleスカラー
CiNii
Jstage
IRDB
検索対象のクエリ分析
XXXXXXに検索文字列を入れる
- Googleスカラーhttps://scholar.google.co.jp/scholar?hl=ja&as_sdt=0%2C5&q=XXXXXX&btnG=
- CiNiihttps://cir.nii.ac.jp/all?q=XXXXXX
- Jstagehttps://www.jstage.jst.go.jp/result/global/-char/ja?globalSearchKey=XXXXXX
- IRDBhttps://irdb.nii.ac.jp/search?kywd=XXXXXX&op=%E6%A4%9C%E7%B4%A2&fulltextflg=All&title=&description=&creator=&creatoraf=&creatorid=&publisher=&journal=&pubdate=&open_volume=&open_issue=&open_spage=&open_epage=&doi=&id=&typeid=&versiontypeid=&fundaf=&diaf=&dino=&kikanid=&items_per_page=20&sort=ss_record%2Bdesc
ChatGPTの設定
ChatGPTのAPIの設定
- OpenAIに登録
https://openai.com/product - Get started
- View API keys
- 「+ Create new sercret key」ボタンをクリック
アプリ名を入力する - APIKeyを取得

PythonからChatGPTを操作
ChatGPTのライブラリをインストール
pip install openai
取得したAPIをshell変数に格納
export OPENAI_API_KEY="sk-xxxx"
テストプログラム
import openai, json, os
openai.api_key = os.environ["OPENAI_API_KEY"]
def ask(question):
prompt = f"以下の文章を要約しなさい。Q: {question}\nA:"
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
max_tokens=1024,
n=1,
stop=None,
temperature=0.7,
)
answer = response.choices[0].text.strip()
print(answer)
return answer
bunsyou="いいかそのひとは指を一本あげてしずかにくるくるとまわって、前のあの河原を通り、三角標のあたりにいらっしゃって、いまぼくのことをぼんやり思い出して眼が熱くなりました[>
ask(bunsyou)
実行するとエラーになる場合
root@ubuntu-20:/home/tmcit# python3 ai.py
Traceback (most recent call last):
File "/home/tmcit/ai.py", line 8, in <module>
response = openai.ChatCompletion.create(
File "/usr/local/lib/python3.10/dist-packages/openai/api_resources/chat_completion.py", line 25, in create
return super().create(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/openai/api_resources/abstract/engine_api_resource.py", line 153, in create
response, _, api_key = requestor.request(
File "/usr/local/lib/python3.10/dist-packages/openai/api_requestor.py", line 230, in request
resp, got_stream = self._interpret_response(result, stream)
File "/usr/local/lib/python3.10/dist-packages/openai/api_requestor.py", line 624, in _interpret_response
self._interpret_response_line(
File "/usr/local/lib/python3.10/dist-packages/openai/api_requestor.py", line 687, in _interpret_response_line
raise self.handle_error_response(
openai.error.RateLimitError: You exceeded your current quota, please check your plan and billing details.
- openAIのサイトを開く
https://platform.openai.com/account/billing/overview - Set up paid account
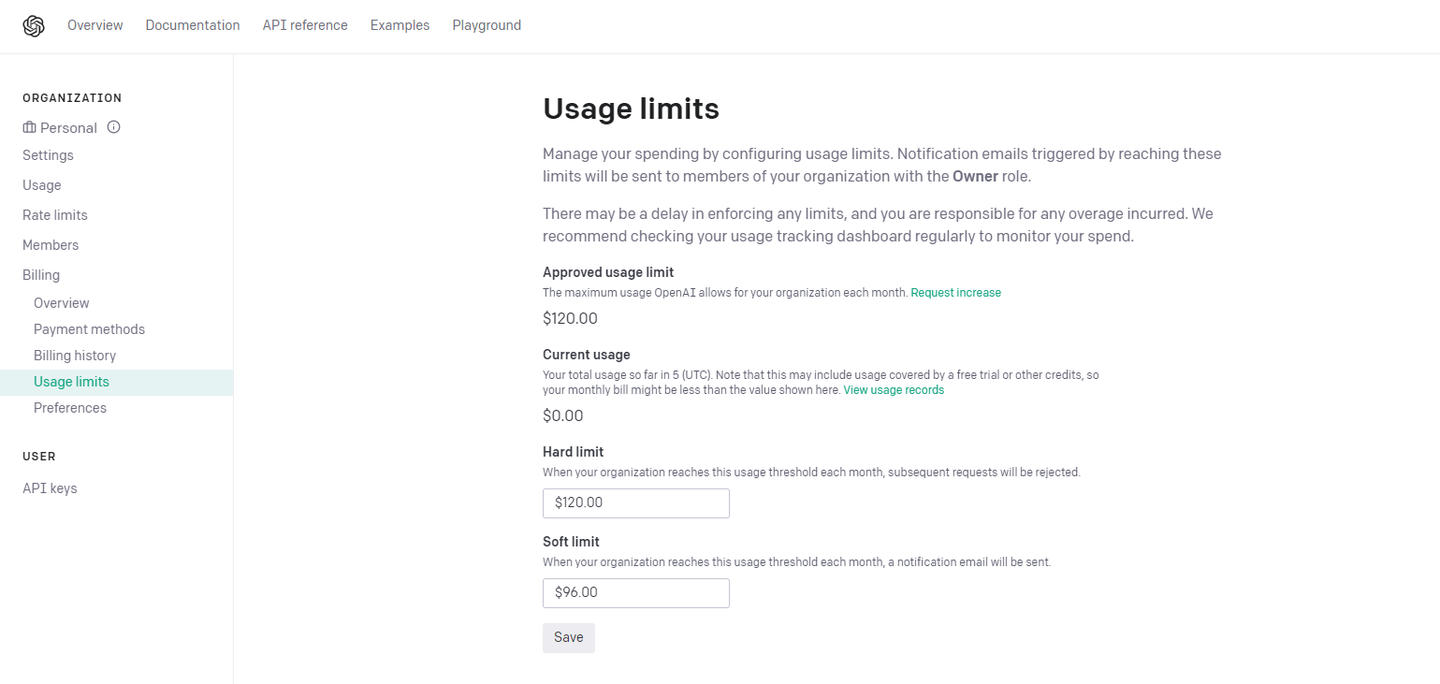
- 上限金額の設定
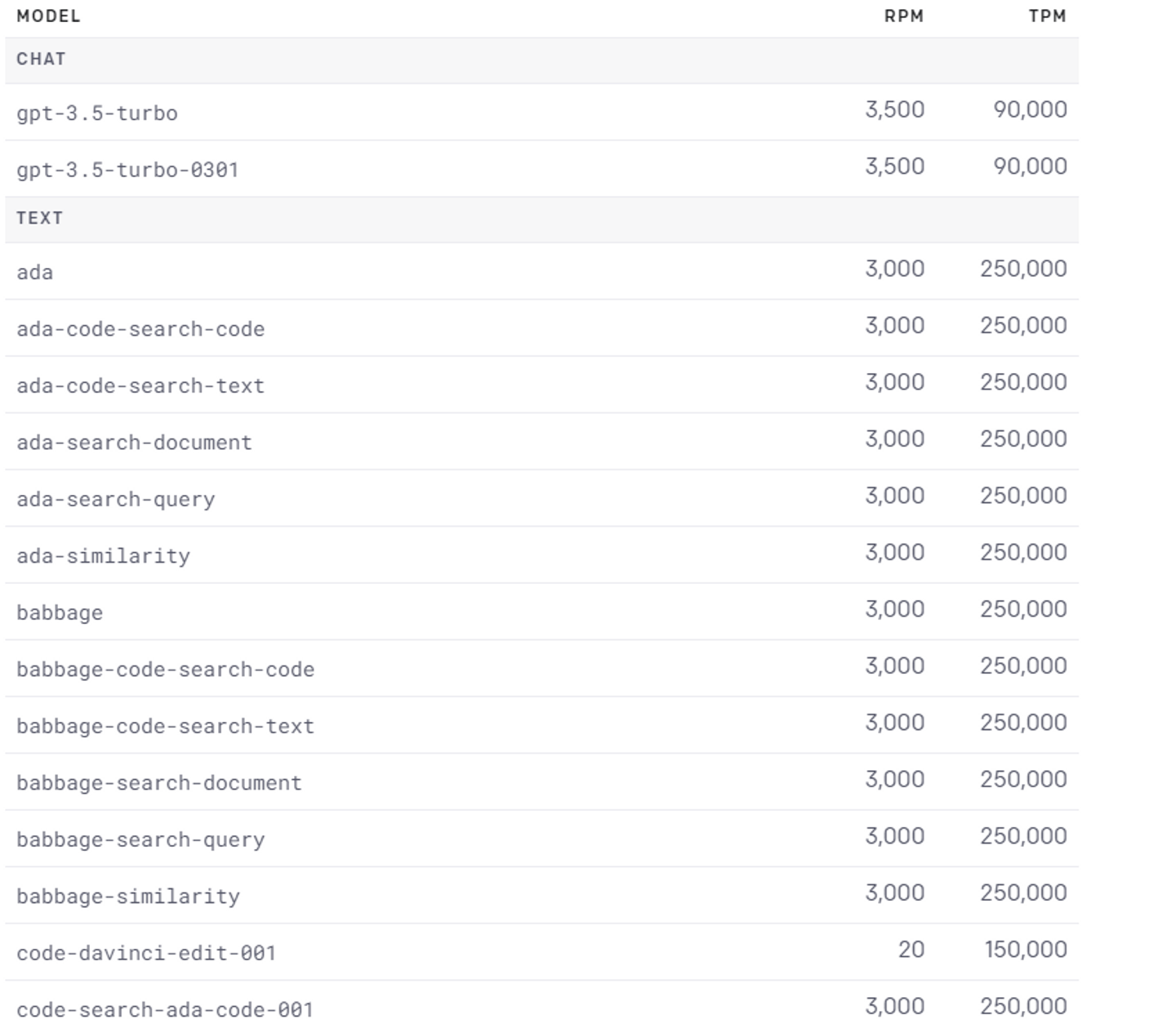
usage limit - 使用出来るエンジンの確認
https://platform.openai.com/account/rate-limits
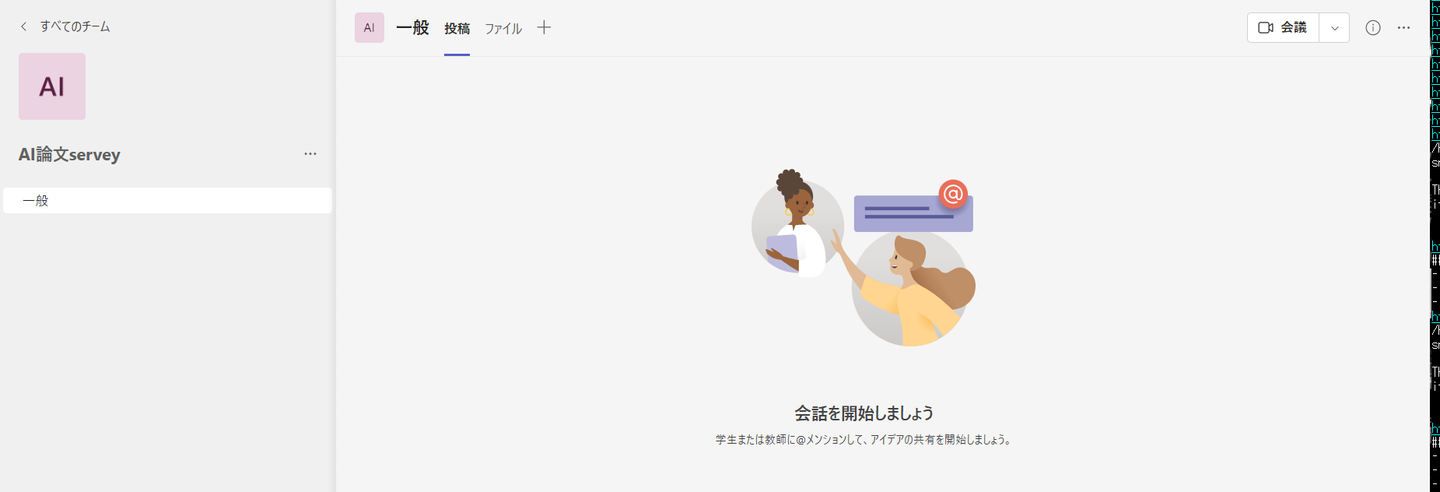
teamsの用意
- チームの作成
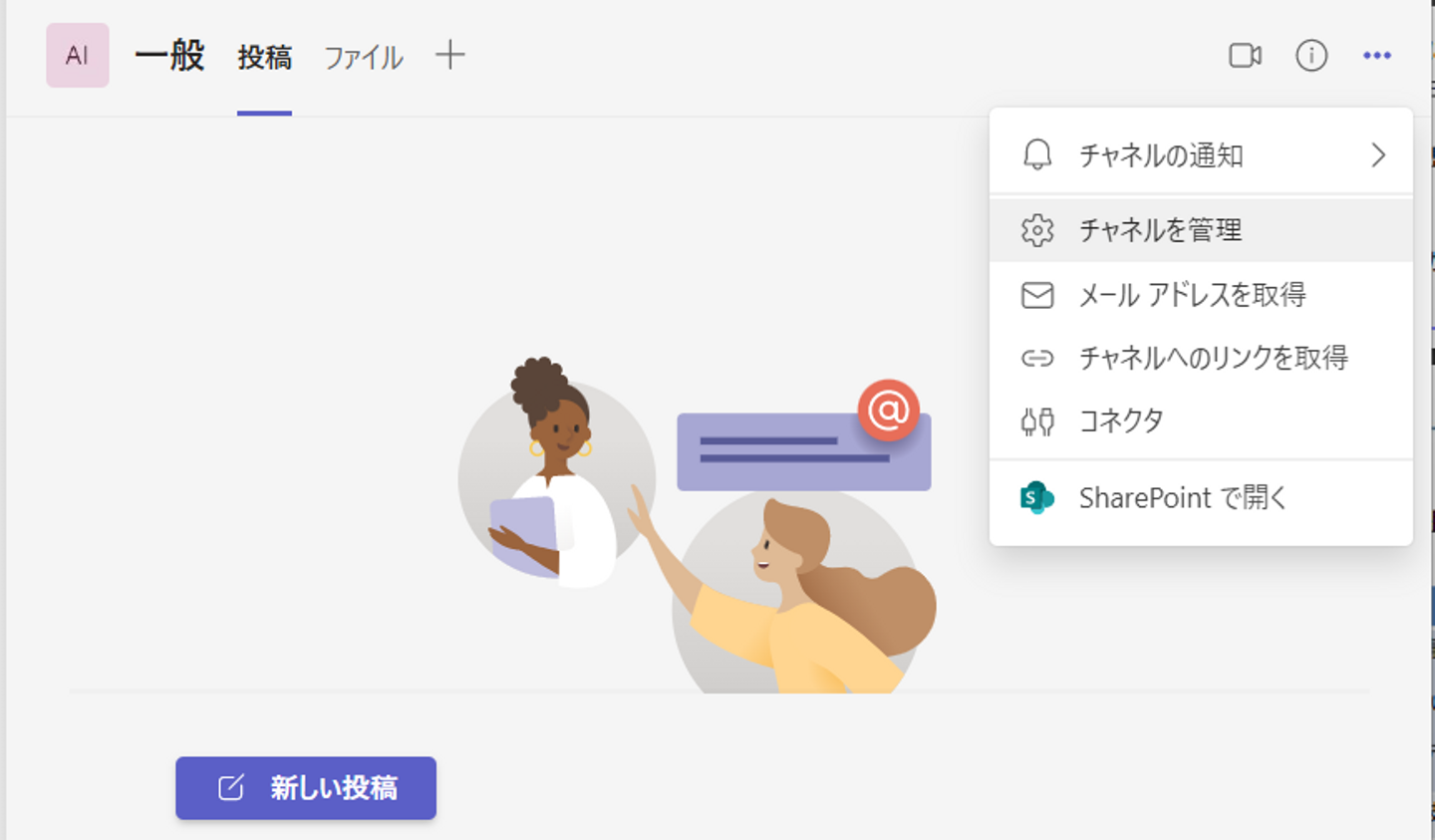
- コネクタ
- incoming webhook
- 名前を入力し、作成すると、URLが出力される
- 完了ボタン


pythonとteamsの連結
pip install pymsteams
テストコード
import pymsteams
TEAMS_WEB_HOOK_URL = "https://outlook.office.com/webhook/xxxxxxxxxxxxxxxxxxxxxx"
myTeamsMessage = pymsteams.connectorcard(TEAMS_WEB_HOOK_URL)
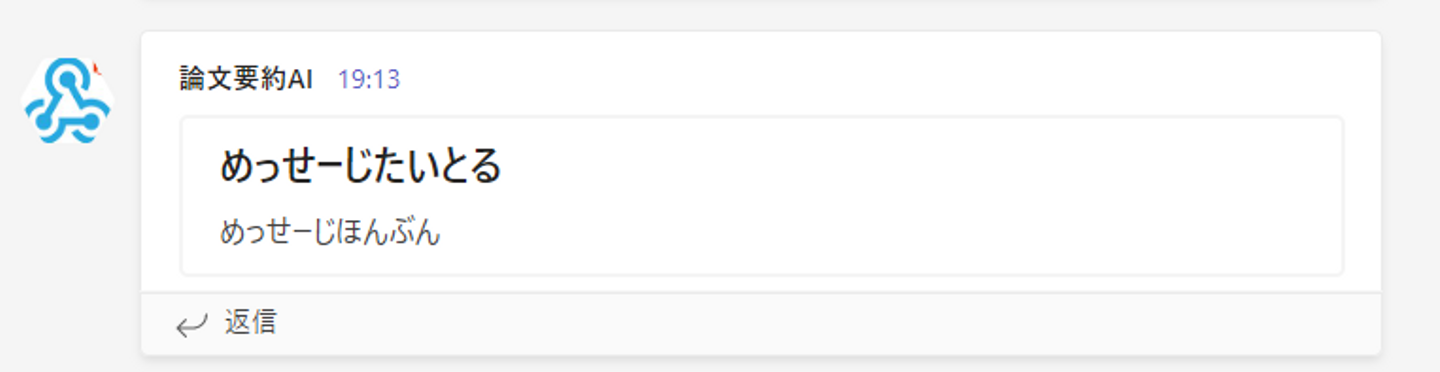
myTeamsMessage.title("title")
myTeamsMessage.text("message")
myTeamsMessage.send()
実行
完成形(収集+要約+投稿)
import openai, json, os
import urllib.request
import json
from bs4 import BeautifulSoup
import requests
import pandas as pd
import re
from urllib import request
import pymsteams
import random, time
openai.api_key = os.environ["OPENAI_API_KEY"]
teamsapi = os.environ["TEAMS_WEB_HOOK_URL"]
def ask(question):
prompt = f"### 指示\n論文の内容を要約した上で,重要なポイントを箇条書きで3点書いてください。また 、URL(httpから始まる文字列)が入力されていた場合はそのURLを一番最後に出力する事。\n### 箇条書きの制約###\n- 最大3個\n- 日本語\n- 箇条書き1個を50文字以内\n###対象とする論文の内容###\n{question}\n###以下のように出力してください###\n- 箇条書き1\n- 箇条書き2\n- 箇条書き3\n-入力されたURL(URLが入力されていな ければ無視して良い)"
print(prompt)
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
max_tokens=1024,
n=1,
stop=None,
temperature=0.7,
)
answer = response.choices[0].text.strip()
print(answer)
time.sleep(10)
myTeamsMessage = pymsteams.connectorcard(teamsapi)
myTeamsMessage.title(tagurl)
myTeamsMessage.text(answer)
myTeamsMessage.send()
return answer
kensakulist = ['container', 'コンテナ', 'Docker','CNCF', 'kubernetes', 'k8s', 'マイクロサービス','ク ラウド']
for kensaku in kensakulist:
try:
url = "https://cir.nii.ac.jp/articles?q=" + str(kensaku) + "&count=200&sortorder=0"
print(url)
response = request.urlopen(url)
soup = BeautifulSoup(response)
response.close()
tag_list = soup.select('a[href].availableLink')
for tag in tag_list:
tagurl = tag.get('href')
print(tagurl)
tag_list = soup.select('a[href].availableLink')
for tag in tag_list:
try:
tagurl = tag.get('href')
response = request.urlopen(tagurl)
soup = BeautifulSoup(response)
response.close()
tables = soup.findAll('table')[0]
rows = tables.findAll('td', class_="td_detail_line_repos w80")
for row in rows:
text1 = row.get_text()
text1 = re.sub('\s+', ' ', text1)
print(len(text1))
if 500 < len(text1):
teur = str(text1) + str(tagurl)
ask(teur)
except:
pass
except:
pass
上記のコードを実行すると
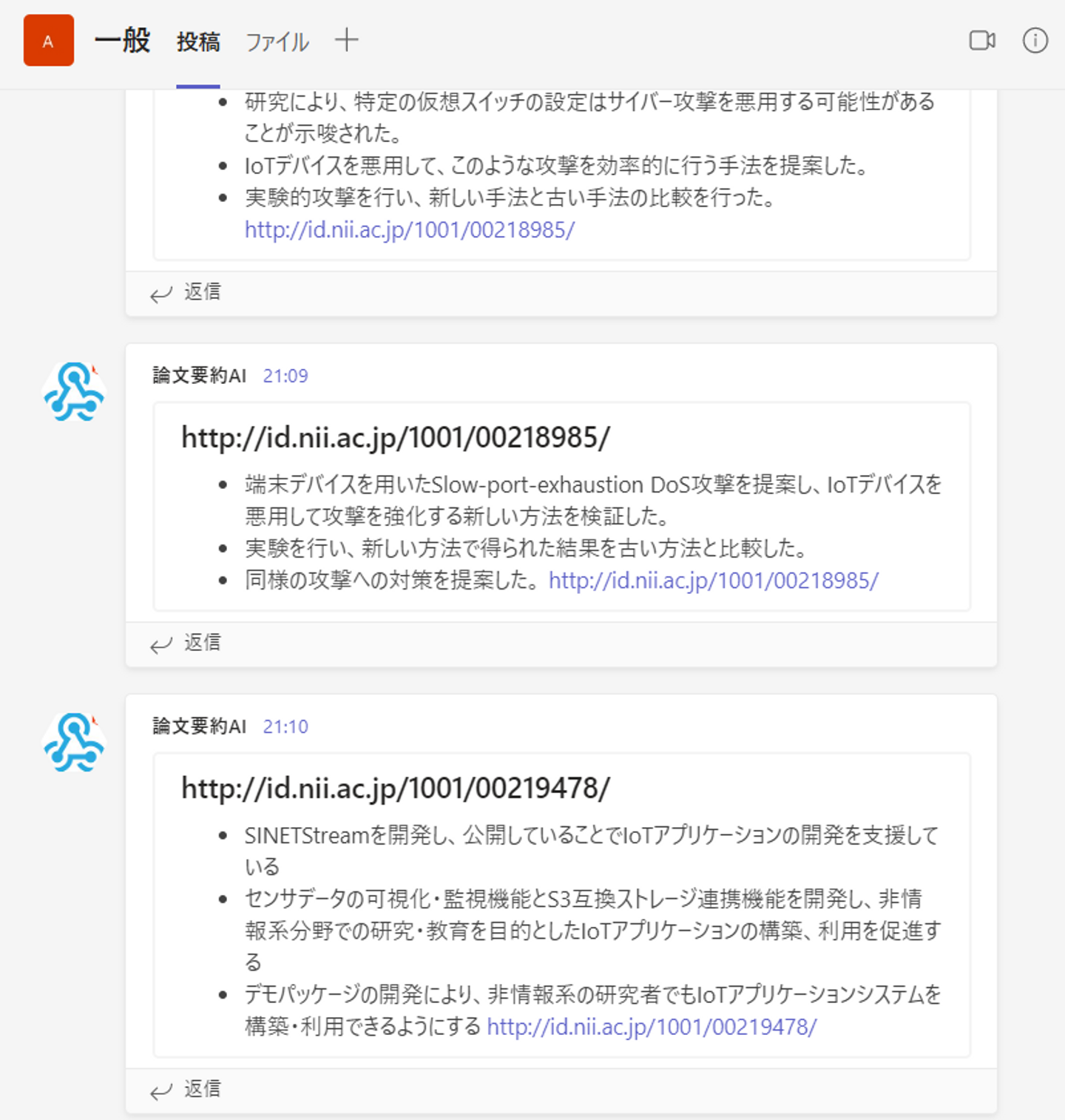
systemdの作成
nano /etc/systemd/system/aiservey.service
aiservey.service
[Unit]
Description=
Documentation=
[Service]
Type=simple
User=root
Group=root
TimeoutStartSec=0
Restart=on-failure
RestartSec=30s
#ExecStartPre=
ExecStart=/home/tmcit/AIservey/aiservey.sh
SyslogIdentifier=Diskutilization
#ExecStop=
[Install]
WantedBy=multi-user.target
nano /home/tmcit/AIservey/aiservey.sh
aiservey.sh
#!/bin/bash
export OPENAI_API_KEY=xxxxxxx
export TEAMS_WEB_HOOK_URL=xxxxxx
pkill python3 -9
pkill python3 -9
python3 /home/tmcit/AIservey/ai2.py
systemd実行
chmod +x aiservey.sh
systemctl daemon-reload
systemctl start aiservey
crontabの設定
毎日7時の実行
crontab -e
* 7 * * * systemctl restart aiservey
参考文献
- https://dev.classmethod.jp/articles/openai-api-chat-python-first-step/
- https://auto-worker.com/blog/?p=6988
- https://python.atelierkobato.com/chatgpt/
- https://qiita.com/nemutas/items/3f5816eabbf0eda5e6a9
- https://qiita.com/yuta0821/items/2edf338a92b8a157af37
本記事はqiitaにも投稿しております
AIservey:収集した論文を要約してteamsに送信してくれるツール



