Business social network with 4M professionals


A Kobashi
スタンフォード大学・大学院にて電子工学を専攻。世界最大の軍事企業であるロッキード・マーティン米国本社で4年超勤務。ソフトウェアエンジニアとして衛星の大量画像データ処理システムを構築し、JAXAやNASAも巻き込んでの共同開発に参画。その後、クアルコムで半導体セキュリティ強化に従事した後、アップル米国本社に就職。ハードウェア・ソフトウェアの両面からiPhone、iPad、Apple Watchの電池持続性改善などに従事した後、シニアエンジニアとしてAirPodsなど、組み込み製品の開発をリード。2017年11月に、キャディ株式会社を加藤と共同創業。
加藤 勇志郎
キャディ株式会社 代表取締役CEO 東京大学卒業後、2014年にマッキンゼーアンドカンパニーに新卒入社。2年後の2016年にマネージャーに就任。 シニアマネージャーとして、製造業の全社調達改革領域及びIoT/AI領域をリードするほか、グローバル戦略構築、新規事業策定などに従事。大手メーカー15社程度の調達改革に従事した結果、同分野への課題意識から2017年末にキャディ株式会社を創業。 製造業領域の「特注品のAmazon」として、日本国内だけでも120兆円の巨大領域に、自動見積・受発注プラットフォームを提供しています。ものづくりの世界を、テクノロジーの力でよりアツく元気で豊かにしていきたいです。 積極採用中ですので是非お声がけください! 週末は、愛犬(ボーダーコリー)とたわむれたり、山川に行ったりしています!
キャディ株式会社's members
What we do
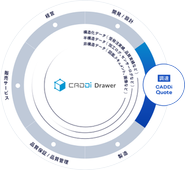




What we do
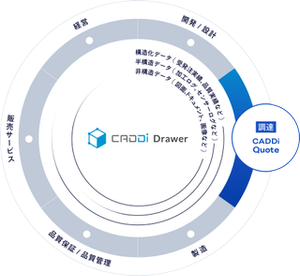
CADDi Drawerを中心に様々な新規プロダクトをプラットフォーム上に開発/展開しています。

展示会でのブース出展なども通じて大手メーカーの顧客獲得も行っています。
Why we do

2023年7月には、シリーズCラウンドで総額118億円の資金調達を実施。今回調達した資金は、グローバルも含めた人材採用やCADDiの開発、そして新規事業に投資する予定です。
How we do

グローバル4拠点に拡大し、世界中で使われるプロダクトを目指して開発を進めています。

創業7期目を迎えた弊社も、既に従業員が500名を超えております。
As a new team member
Highlighted stories
1 recommendation
What happens after you apply?
- ApplyClick "Want to Visit"
- Wait for a reply
- Set a date
- Meet up
Company info
Founded on 11/2017
535 members
- Expanding business abroad/
- Funded more than $1,000,000/
- Funded more than $300,000/
東京都台東区蔵前1-4-1 (総合受付3F)